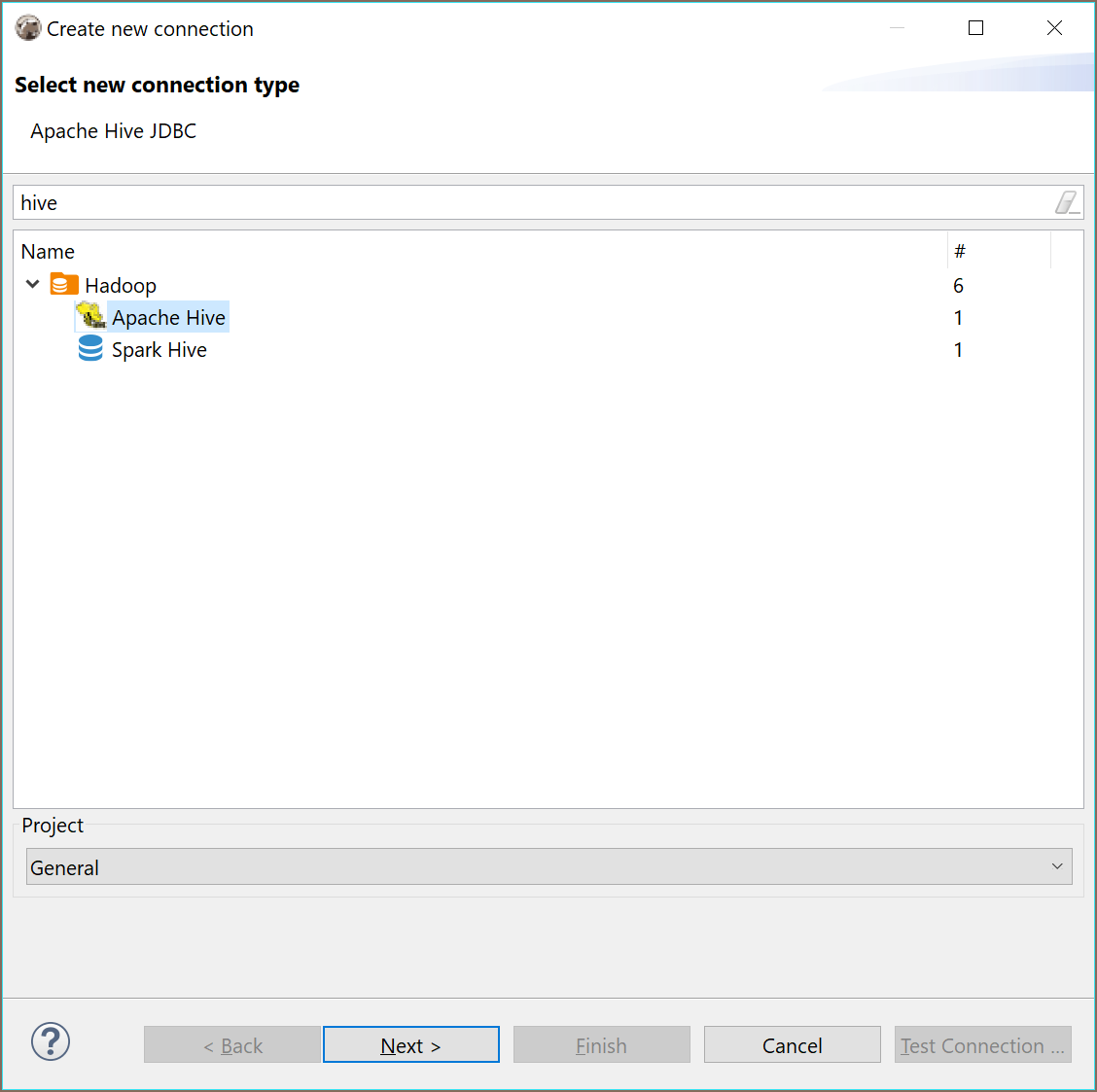
Apache Hive
Hive is a Hadoop-based storage system. Hive uses a special SQL dialect (HiveQL) to operate with data and metadata. Generally, it is quite similar to SQL.
There are multiple implementations of storage systems which utilize Hive on the server-side - including Apache Spark, Impala, etc. Most of them support the standard Hive JDBC driver which is used in DBeaver to communicate with the server.
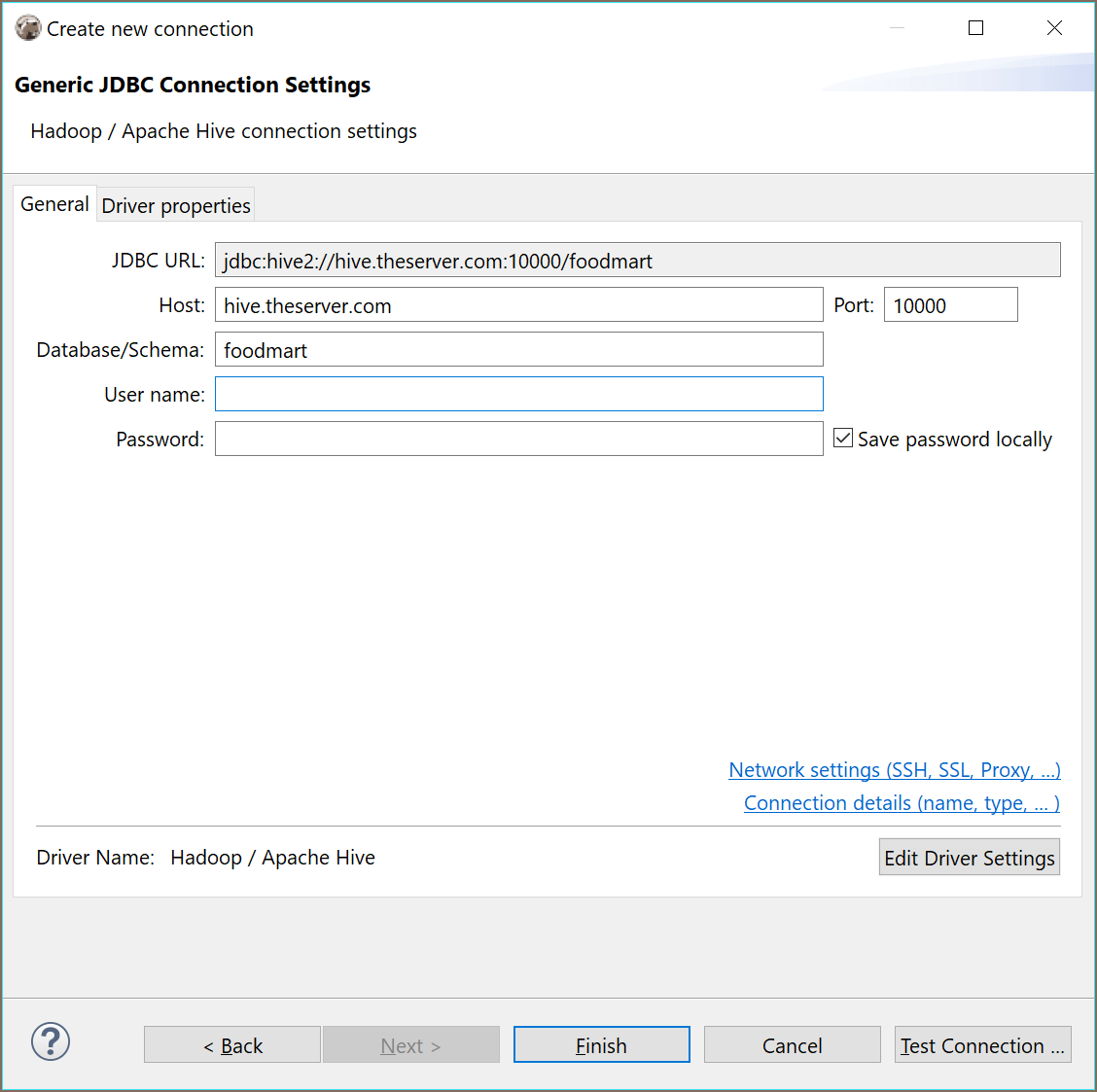
DBeaver uses a so-called Hive JDBC Uber Jar driver (https://github.com/timveil/hive-jdbc-uber-jar) which includes all necessary dependencies. You do not need to download anything - DBeaver will download everything automatically (if you have internet access).
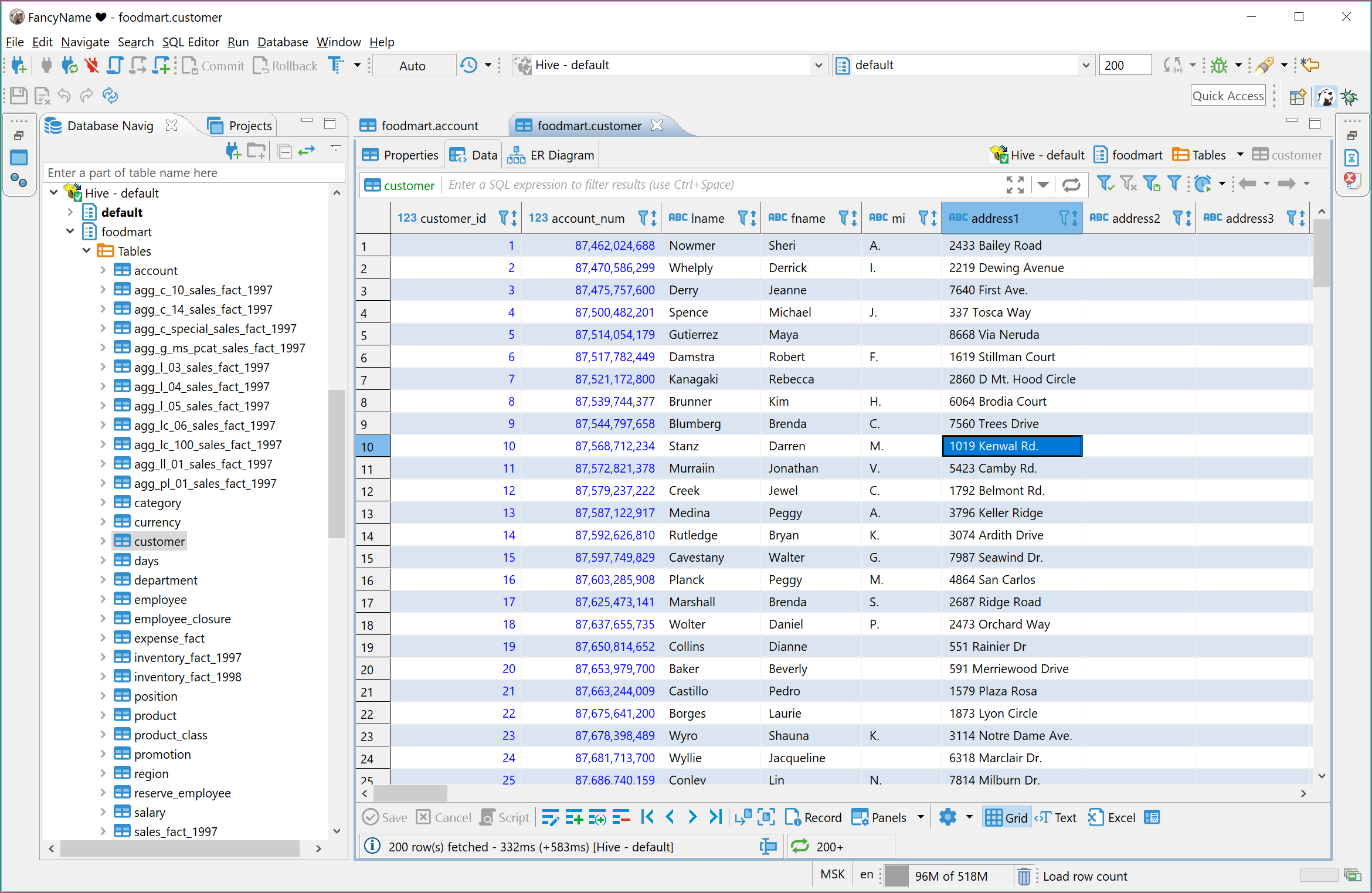
Hive does not support referential integrity so you will not see primary keys or foreign keys. ER diagrams also do no make much sense.
- Installation
- Application Window Overview
- Views
- Database Object Editor
- SQL Editor
- Search
-
Schema compare

-
Using Liquibase in DBeaver
-
Data compare
-
MockData generation
-
Spelling
- Dashboards, DB monitoring
- Projects
-
Managing Master password
-
Security in PRO products
-
Certificate Management
- Bookmarks
- Shortcuts
- Accessibility
- Sample Database
-
Database Connections
- Edit Connection
- Invalidate/Reconnect to Database
- Disconnect from Database
- Change current user password
- Advanced settings
- Cloud configuration settings
- Local Client Configuration
- Connection Types
- Configure Connection Initialization Settings
-
Tableau integration
- Transactions
- Drivers
- Tasks
-
Cloud Explorer
-
Cloud Storage
- Classic
- Cloud
- Changing interface language
- DBeaver extensions - Office, Debugger, SVG
- Installing extensions - Themes, version control, etc
- User Interface Themes
- Command Line
- Reset UI settings
- Reset workspace
- Troubleshooting system issues
- Posting issues
- Log files
- JDBC trace
- Thread dump
- Managing connections
- Managing variables
- Managing drivers
- Managing preferences
- Managing restrictions
- Windows Silent Install
- Snap installation