Keypoint Detection Training - dnum-mi/basegun-ml GitHub Wiki
Keypoint Detection Training
In order to obtain the best possible model, we conducted several experiments to determine the optimal parameters. In this section, we will present the experiment, the results, and the conclusions.
Data Augmentation
YOLOV8 offers various data augmentation techniques directly within the Ultralytics library. However, not all techniques are applicable to our use case.
- We chose not to use flip or mirror augmentation because weapons are not symmetrical. Therefore, this augmentation could potentially create impossible weapons.
- We chose not to use mixup because the superposition of weapons could distort the results of our model, where we aim to precisely detect the barrel.
The decision on whether to use mosaic augmentation required further investigation. For this purpose, a test was performed, launching the same training with and without mosaic augmentation and comparing the results.
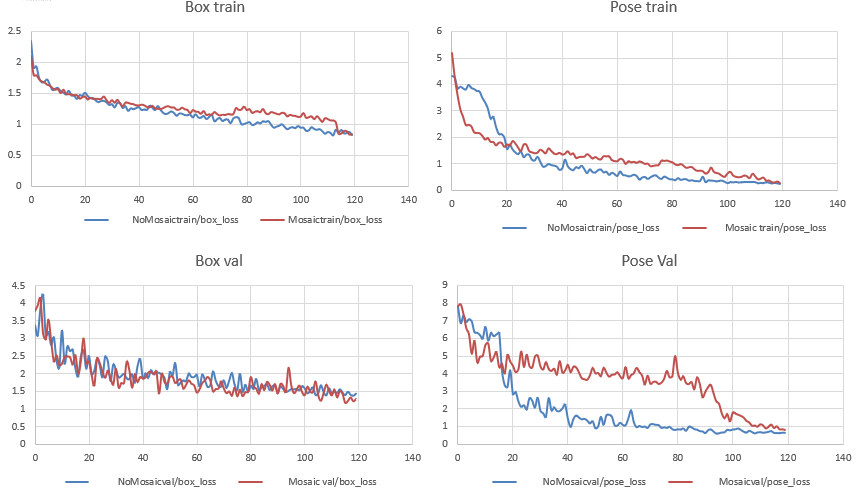
As one can see, the final results are not significantly different whether using mosaic or not. For our use case, we need the weapon to be entirely visible, and sometimes with mosaic, the weapon may be cropped. Therefore, we chose not to use this augmentation.
Model Size
The length detection module will be integrated into the BaseGun app, and the total execution of the module must be less than 2 seconds. Also, the module will be executed on CPU-only servers. For these reasons, the model must be lightweight and have a short inference time. We will study the Nano and Small models of YOLO.
To determine which model size to use, a simple training on the custom dataset was performed, with the only change being the model size.
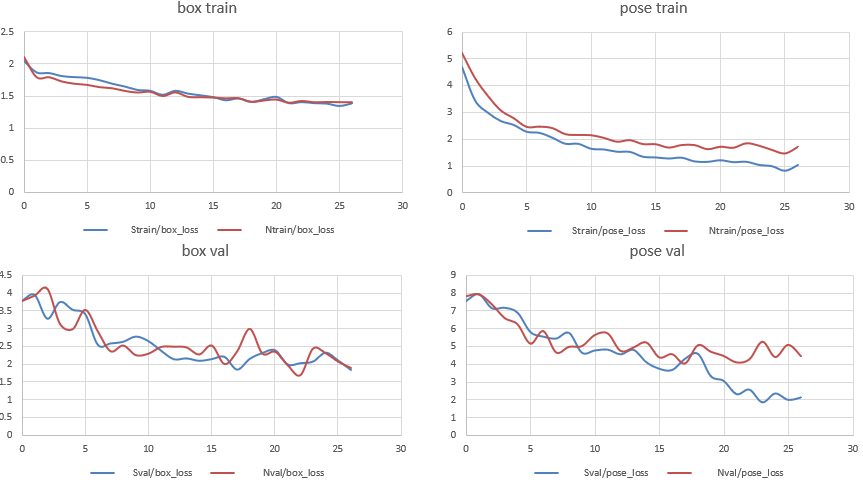
For bounding box detection, the performance is similar between the Nano and Small models. However, one can see a difference in keypoint detection. So, if the inference time allows it, the Small model would be better. However, the Small model requires more CPU for training and using our machine, the training crashes after 16 epochs.
The final decision is to continue the exploration with the Nano model and, in the end, if the inference time is compatible with the constraint, retrain the model on a larger machine using the Small model.
Keypoint Detection Loss
The keypoint detection loss is based on the OKS metric explained [here](link to OKS). In the case of pose detection, the factor K is well defined for each keypoint.
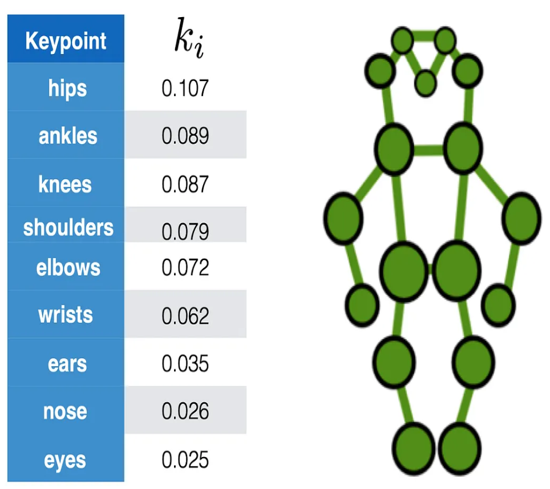
However, in our case, it is not a common task to determine points on weapons, therefore those coefficients are not defined. In that case, YOLOV8 makes an assumption and defines K=1/(number of keypoints) = 1/4. Compared to the coefficient for pose detection, it is very high, therefore the precision on the keypoint would be low.
To resolve this issue, there are two solutions:
- Adapt the coefficient
- Change the metric
Some experiments have been conducted using different metrics:
- The OKS with K defined by YOLO, which we will call baseline
- The OKS with K from YOLO but divided by 3 to reduce it
- The L1 loss function $$\sum_{i=1}^{n} |y_{\text{true}} -y_{\text{predicted}}|$$
- The Euclidean distance $$\sqrt{\sum_{i=1}^{n} (y_{\text{true}} -y_{\text{predicted}})²}$$
Impact on Validation Images

As one can see, the most precise metric function is the Euclidean distance. Therefore, it will be the selected metric for keypoint detection.
Optimizers
The choice of the optimizer in a deep learning model can have a significant impact in terms of convergence and speed of convergence. To determine which optimizer to use, we compared Adam and SGD on the same training.

There is no major difference between the two trainings for box detection or keypoints. Therefore, we chose to continue with Adam, which was our original choice.
Weighted Loss
As previously seen here , YOLOV8 calculates different losses and then combines them to obtain a global loss for backpropagation. These losses can be weighted to adapt the model to a specific use case. Several experiments have been conducted to determine which loss to prioritize.
The main conclusion is that some losses are essential for the keypoint detection to perform well: Box_Loss and Cls_Loss. The model needs to know where the object is and what it is before pinpointing the keypoints. Knowing this, one can adjust the different weights for better detection or better keypoints.