Keypoint Detection research - dnum-mi/basegun-ml GitHub Wiki
Common Use Cases of Keypoint Detection
Keypoint detection is a machine learning task that aims to detect specific points on an object within an image or video. The most common use cases for keypoint detection are pose detection and face landmarks detection.
- Pose detection involves detecting human poses and is used to track movements.\
Models
Developing a model from scratch requires a tremendous amount of data and computational power. Therefore, we chose to explore existing models and tune them for our use case. Here are some examples of models for keypoint detection. We compared these different models according to the following parameters:
- AP50 COCO is the average precision of the model on the Coco dataset with an OKS threshold of 0.5. It means that the keypoint is considered precise when the OKS is higher than 0.5, then the average precision is calculated.\
After considering various models and conducting several inference trials, we have selected YOLOV8 as the model for our use case.
A Deep Dive into YOLOv8
How Does It Work?
YOLOv8, or "You Only Look Once V8," is a computer vision algorithm used for object detection in images and videos. The name "You Only Look Once" signifies that the algorithm processes the entire image or video in a single forward pass, rather than dividing it into smaller regions or windows. This feature allows it to be very fast, making it a popular choice for detection on live video feeds such as autonomous vehicles or security cameras.
YOLO offers various tasks such as:
- Object detection
- Object segmentation
- Object classification
- Object pose detection
For our use case, which involves keypoint detection on weapons, the most relevant task is the last one. The Ultralytics library provides access to YOLO models and methods for training them, evaluating them, and even preparing datasets, which is very convenient. You can find more information here. The pose detection model predicts a bounding box of the object and the keypoints associated with the object. It also performs classification if it is a multiclass problem.
How to Train a YOLOv8 Pose Detection Model on a Custom Dataset?
Given our need for speed in our use case, we will be working with the nano and small models.
Dataset Preparation
To train the model on a custom dataset, the dataset must adhere to a specific structure and format.
Each image in the dataset has a corresponding label file with the following format.
\
- Filename matching with image
- Class ID (only one class in our use case)
- Bounding box coordinates (Xcenter, Ycenter, Width, Height)
- Keypoint coordinates (X,Y)
Data Augmentation
With YOLO, you can perform data augmentation transformations on the training dataset. The available data augmentation transformations include:
- Color transformations such as Hue, Saturation, and Value.
- Geometric transformations, such as Rotate, Translate, Zoom, Shearing, Flip.
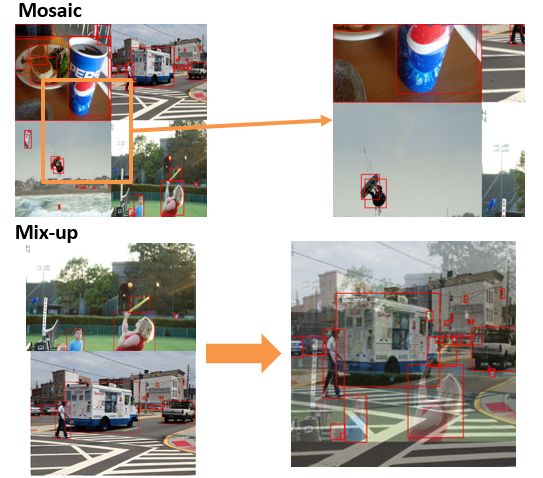
YOLO also offers specific transformations such as Mosaic transformation and Mix-up, which are described below.
Model Size
For each task, there are different model sizes, which are named after T-shirt sizes. For instance, for pose detection, there are:
- YOLOV8-pose Nano, Small, Medium, Large, Extra Large. The larger the model, the more computational resources it requires for training, and the longer the inference time will be. However, the precision will also increase, as shown here.
Loss Functions and Metrics
The YOLOV8 model calculates different losses and performs a weighted sum to obtain a global loss used for backpropagation. The different losses include:
- Box_Loss: Used for bounding box detection and based on IOU
- DFL Loss: Distribution Focal Loss used for bounding box (not mandatory)
- Cls_Loss: Classification loss based on BCE
- Pose_Loss: Keypoint detection usually based on OKS
- Kobj_Loss: Keypoint objectness used in the case of keypoint prediction with confidence score
The weights of the different losses can be adjusted depending on each use case.
Hyperparameters
For the training, you can tune YOLOV8 hyperparameters such as:
- Optimizer
- Batch size
- Number of epochs
- Image size Other parameters can be found here.
Model Outputs
The training outputs of the YOLO library are very convenient. They include:
- Training curves in various formats: CSV, PNG, TensorBoard
- A YAML file containing all the hyperparameters used for the training
- Weights of the trained model: The best on the validation dataset and the weights from the last epoch
- Predicted images of the validation dataset
For the training of YOLOV8, you can check out this page