Captain's log Wavy - WojciechMigda/TruRL GitHub Wiki
2021-06-26
W ramach przygotowania do eksperymentów ze stride ściąga z wykonywania analizy przebiegów CSV:
./run_klines_info.py -w 150 ../../../Kanomalia-experiments/klines/bina/Binance_BTCUSDT_1m_Y2021.csv.bz2
2021-06-26
Jak robić walidację? Na przykład dodając do wywołania:
--validate-klines 15789 ../../experiments/klines/Binance_BTCUSDT_1m_1597278060000-1598227200000.json \
--validate-klines 206189 ../../experiments/klines/Binance_BTCUSDT_1m_1557792000000-1570233600000.json \
2021-01-24
Aplikacja potrafi robić walidację modelu na przekazanym przebiegu czasowym. Próbne eksperymenty pokazują, że modele nie uczą się w przewidywalny sposób.
2021-01-17
Zagadka niestabilności samouczenia i rozrzutu wyników wyjaśniona: 2021-01-16 Klines 1 - random walk.
Najbliższy plan: dodanie funkcjonalności walidacji Agenta na dodatkowym przebiegu czasowym.
Z innych wieści:
- aplikacja została rozszerzona o możliwość przekazania LAMBDA, wartości seed dla Agenta, oraz kontroli poziomu logowania dla zdefiniowanych kategorii logów.
2021-01-16
Zakończyły się dwa eksperymenty sprawdzające wpływ podwojenia parametrów BATCH SIZE oraz NEPOCHS. Raport wkrótce.
W kolejce są dwa nowe eksperymenty jak będzie wyglądała stabilność samouczenia:
- dla liczby kroków=480 i liczby epizodów=200,
- dla s=50 przy włączonym próbkowaniu Box-Muller,
Pomysły do zweryfikowania na istniejących danych:
- na ile wpływ na obserwowany rozrzut ma branie pod uwagę początkowych wartości nagrody, z etapu kiedy model dopiero się uczy.
Development:
- kontrola poziomu logowania w aplikacji dla poszczególnych modułów, jako rozszerzenie poziomów globalnych.
2021-01-16
Zakończyły się zaplanowane eksperymenty przeglądu specificity. Wyniki są zebrane tutaj. Status wykonania:
T=10k Q=±0.5 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
T=10k Q=±5.0 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
T=32k Q=±0.5 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
T=32k Q=±5.0 s=4.0 ❌ s=8.0 ❌ s=16.0 ❌
T=100k Q±0.5 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
T=100k Q±5.0 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
2021-01-15
Spływają wyniki dla specificity. Mały przegląd:
T=10k Q=±0.5 s=4.0 ✅ s=8.0 ❌ s=16.0 ❌
T=10k Q=±5.0 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
T=32k Q=±0.5 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
T=32k Q=±5.0 s=4.0 ❌ s=8.0 ❌ s=16.0 ❌
T=100k Q±0.5 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
T=100k Q±5.0 s=4.0 ✅ s=8.0 ✅ s=16.0 ✅
2021-01-15
Kolejne pomysły:
- podwoić NEPOCHS,
- podwoić BATCH size,
TODO:
- dodać kategorie do logowania,
- dodać możliwość zapamiętania modelu,
- tryb walidacji modelu.
2021-01-14
Ustalenia do tej pory:
- Box-Muller nie pomogło, ale trzeba spróbować z mniejszym specificity, 2021-01-13 Klines 1 - Box-Muller fiasco
- zwiększenie Threshold nie pomogło, 2021-01-13 Klines 1 - Threshold + Loss fn test
- loss function MAE i L1+2(0.5) też nie pomogło, 2021-01-12 Klines 1 - loss function test
- jedyny dobry trop to specificity, aktualizacja wkrótce...
2021-01-12
Co wiem do tej pory:
- właściwie wszystkie eksperymenty
07_klineszrobione do tej pory są do powtórzenia, - wysiłki skupiają dążą do wyjaśnienia co zmienić żeby samouczenie było stabilne,
Obserwacje poczynione do tej pory:
- jest duży rozrzut w wynikach samouczenia dla pojedynczych uruchomień,
- widać na pewno poprawę przy zawężaniu roboczego zakresu wartości funkcji Q, nawet gdy wartości używane do trenowania regresora muszą być przycinane (patrz eksperyment z zakresem [-0.5, 0.5]. Zawężanie roboczego zakresu Q to większa gęstość dyskretnych wartości w domenie interfejsu regresora.
- użycie innej loss function daje niewielką poprawę, wciąż daleko od tego co daje zmiana roboczego zakresu wartości funkcji Q,
Najbliższe plany:
- zwiększenie wartości parametru
Threshold, większa gęstość dyskretnych wartości w domenie interfejsu regresora - co to zmieni? - użycie Box-Muller w regresorze, jeśli źródłem obserwowanych problemów jest niski gradient przy małych wartościach błędu, to może próbkowanie w ten sposób jest właściwym rozwiązaniem?
2021-01-09
Add control over Q range used for digitization in WavyModel.
2021-01-09
Support for passing transaction fees from CLI was added.
Two new actions were added (70).
Proper parsing of nul-separated arguments to Wavy function was added.
Fixed string-to-number conversion in run_csv.py .
2021-01-08
Support for 07_klines generating functions was added.
Support for log_ret range control from CLI was added.
WavyEnv feed code was refactored. Includes reset of the feed upon start of each episode.
Initial 1m klines experiments were launched.
2021-01-07
Experiments with 06_noisier_two_sines were completed.
2021-01-06
Experiments with 03_noisy_sine were completed. First of the two raports is up
[1].
2021-01-06
Two experimented were completed. Both focused on a two-sine (02_two_sines) function generator. One experiment varied gamma, the other varied the number of clauses.
Two new experiments were started. Both were following the approach excercised in past days, only the function generator used was the noisy sine (03_noisy_sine).
2021-01-05
Program's capabilities were extended:
(commit ff895bc6a2c71aa28ccb72d64735d949aa8c5ea1)
Generator functions
With this release there are six functions available:
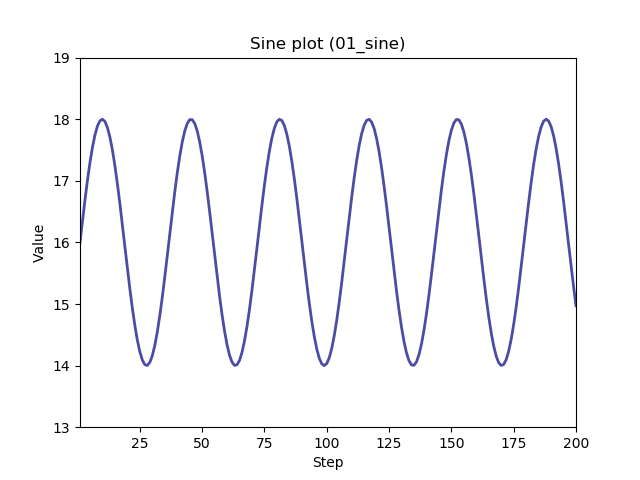
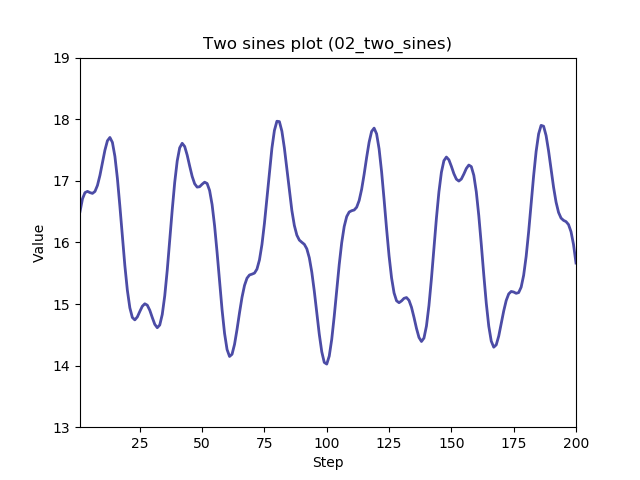
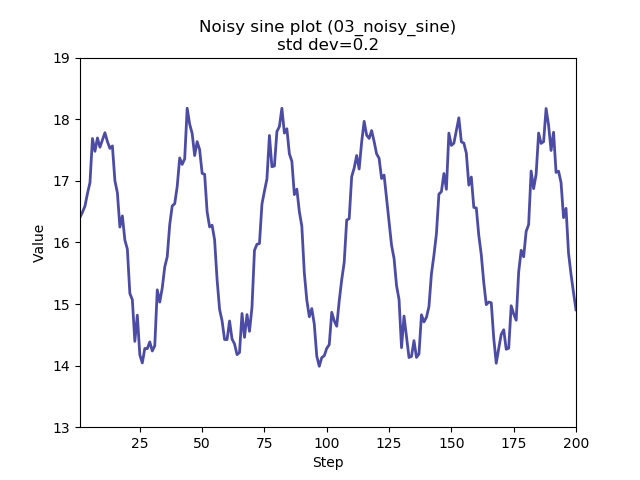
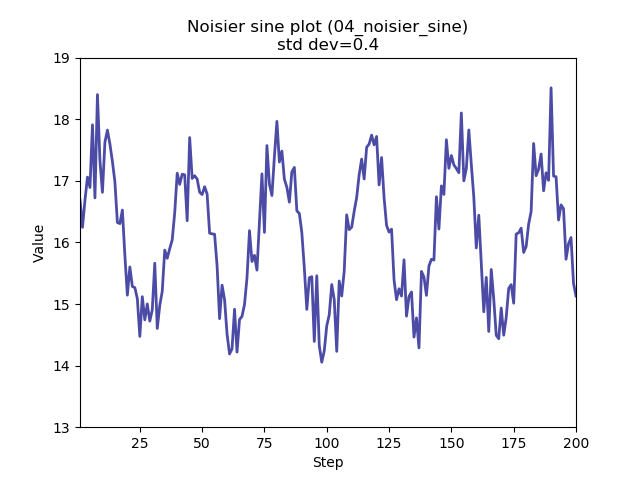
All can be selected from the command line.
Actions specification
Gym actions can be passed from the command line.
2021-01-05
Two new experiments were completed with yesterday's setup as a baseline
- learning with gamma={0.80, 0.90, 0.95}
- learning with number of clauses C={1600, 800}
Raports to be added.
2021-01-04
First official Wavy experiment that seems to work was run.
Code was checked out from this hash 94514cc8151df3341ce6d89d8b0b99ed1b0aa978.
The experiment consisted of 10 runs. Each run consisted of 100 episodes and each episode consisted of 200 steps.
GAMMA was set to 0.7, Threshold was set to 10000, and Memory size was 100k large.
Hardcoded Q limit was +/- 50, and the actions were HOLD, BUY100, and SELL100.
The experiment ran for about 1h:40m.