basics blockchain code - SkycoinWikis/CXChains GitHub Wiki
 HOME » CX » CX CHAINS » BLOCKCHAIN CODE
HOME » CX » CX CHAINS » BLOCKCHAIN CODE
Blockchain Code
"Blockchain code" plays a similar role to that of a programming language library: it defines a series of subroutines (functions), types (structs) and variables, and it can be imported into a program. The differences between blockchain code and a library are the following:
- It is used to initialize a CX chain.
- The global variables defined in the packages that compose the blockchain code act as the program state of a CX chain.
- It includes a
mainfunction. This function is used to initialize the program state of a CX chain. - After initializing the program state, the
mainfunction is removed from the blockchain code.
Program State
The program state of a CX chain is generated by serializing the CX program represented by a blockchain code. This serialization includes all the blockchain code with the exception of the main function which serves solely for the initialization of the program state of a CX chain. This program state is stored on the blockchain as part of an unspent output of a transaction.
The entirety of the program state can be queried or mutated. As is described in the following subsections, it can be seen that the code segment – which represents the blockchain code – is also part of the program state. As a consequent of this design, the code of a CX chain can be modified. Although this feature is not implemented yet, the modification of a CX chain blockchain code is intended to be modified by the use of affordances.
Program State Structure
The program state of a CX chain is equivalent to the serialization of the initialized blockchain code, minus its main function. The structure of this serialization is composed of four memory segments: code, stack, data and heap. The code segment represents the source code in the blockchain code; the stack segment represents the CX program's stack, which stores the local variables of the different function calls that are performed when running a CX program; the data segment stores any global variable and primitive literals found in the source code (for example, in the function call foo(5), the value 5 is stored in the data segment); lastly, the heap segment stores objects that can shrink or expand in size (strings and slices) and objects that are being pointed to by pointers and that escape their function call scope (see Escape Analysis). A diagram of this structure is shown below:
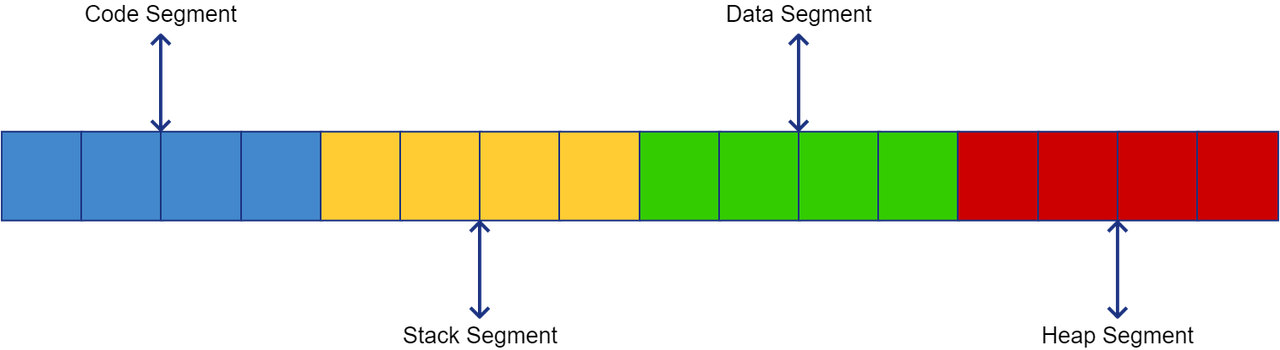
It must be noted that the stack and heap segments are not being included at the moment, but this can/should change in the future versions of CX chains. Despite this limitation, the role of these segments in a CX chain are also described in this document.
Code Segment
The code segment in the program state of a CX chain represents the blockchain code, without its main function. This code can be imported into the transaction code, in order to have its different packages, functions and types be used by the transaction code to modify the program state.
package viewsChain
var views i32
func GetViews() (currentViews i32) {
return views
}
func IncrementViews() {
views++
}
func main() {
// Initialize views.
views = 78
}
The code above shows a minimal library to manage video views in an application. After initializing a CX chain with the code above, we will have a code segment with two functions (GetViews and IncrementViews), a global variable (views) and a package containing these elements (viewsChain). Additionally, views will be pointing to a 78, but this number is stored in a different memory segment.
The code segment has an additional property: it can be modified by using affordances. For example, a user with the required permissions to a CX chain could call a function that adds more functions to the code segment. It is noteworthy that this feature has not been implemented nor fully designed yet.
Stack Segment
The stack segment stores all the values of the local variables of a function call. This memory segment is volatile, as the values stored in it can suddenly be considered garbage after a function call is finished. Storing this memory segment in the program state enables a CX chain to be paused and resumed in a subsequent transaction.
It must be noted that the stack segment will always be wiped out after initializing the program state. In other words, after running the blockchain code, the values left in the stack by calling its main function will not be preserved.
Data Segment
Although the other segments can also be used to preserve the state of a CX chain, the data segment results in the most reliable of the segments due to its nature. The code segment only stores data that represents source code; the stack segment is volatile, which means that the data contained in there can suddenly become garbage, depending on the behavior of the function calls in a program; and the heap segment stores data objects that could be removed by the garbage collector at any moment. In contrast, the data segment has a fixed size, where every chunk of bytes represents the value of each of the global variables declared in the blockchain code, and these global variables will always point to the same addresses in the data segment.
Heap Segment
The heap segment should be seen as an auxiliary mechanism for storing data in a CX chain. Although variables in function calls can point to objects in the heap, these objects will sooner or later be destroyed by the garbage collector if the function call containing that local variable has finished its execution. However, the heap segment works well together with the data segment, as the heap segment allows a CX chain to have pointer global variables, slices and strings, as these are objects that are always allocated in the heap segment in CX.