MySQL - zhongjiajie/zhongjiajie.github.com GitHub Wiki
- 通过conf文件配置编码
[mysqld]
# 服务端编码
character-set-server=utf8
collation-server=utf8_general_ci
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8- 设置sql模式,是否跳过动态名
[mysqld]
# 是否允许group by select 别的字段
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
skip-name-resolve- 想要客户端不输出表头和框框How can I suppress column header output for a single SQL statement: 链接的时候加上
-sN参数,其中-N is --skip-column-names -s --silent例如:mysql -sN -uroot -pmysql
- 类型声明里面的
int(5)代表的意思.INT is always four bytes wide.The 5 is the "display width"What does INT(5) in mysql mean
- mysql中varchar类型最大是多少(这是一个复杂的问题)What is the MySQL VARCHAR max size
- Keep in mind that MySQL has a maximum row size limit: The internal representation of a MySQL table has a maximum row size limit of 65,535 bytes, not counting BLOB and TEXT types. BLOB and TEXT columns only contribute 9 to 12 bytes toward the row size limit because their contents are stored separately from the rest of the row. Read more about Limits on Table Column Count and Row Size.
- Maximum size a single column can occupy, is different before and after MySQL 5.0.3: Values in VARCHAR columns are variable-length strings. The length can be specified as a value from 0 to 255 before MySQL 5.0.3, and 0 to 65,535 in 5.0.3 and later versions. The effective maximum length of a VARCHAR in MySQL 5.0.3 and later is subject to the maximum row size (65,535 bytes(65K), which is shared among all columns) and the character set used.However, note that the limit is lower if you use a multi-byte character set like utf8 or utf8mb4: VARCHAR(21844) CHARACTER SET utf8
- Use TEXT types inorder to overcome row size limit.: The four TEXT types are TINYTEXT, TEXT, MEDIUMTEXT, and LONGTEXT. These correspond to the four BLOB types and have the same maximum lengths and storage requirements.
mysql可以在ddl的时候设置bool类型,但是mysql解释器会将其转译成tinyint(1),也可以使用bit类型实现,参考
-
DECIMAL(13,4): This means that the column will have a total size of 13 digits where 4 of these will be used for precision representation. have a max value of: 999999999.9999
load data local infile 'c:/country.csv'
into table country
fields terminated by ','
enclosed by '"'
lines terminated by '\n'
ignore 1 rows
-- 全部
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number {LINES | ROWS}]
[(col_name_or_user_var
[, col_name_or_user_var] ...)]
[SET col_name={expr | DEFAULT},
[, col_name={expr | DEFAULT}] ...]mysqldump [OPTIONS] database [tables]
mysqldump的基本用法: mysqldump [OPTIONS] database [tables],其中的一些可选项OPTIONS为:
-
-d; --no-data: -d option means "without data", default false -
--comments: Add comments to dump file, default true -
--create-options: Include all MySQL-specific table options in CREATE TABLE statements, default true -
--where: Dump only rows selected by given WHERE condition -
--compact: Produce more compact output, default false. 让输出更加紧凑 -
--add-drop-table: Add DROP TABLE statement before each CREATE TABLE statement, default true 但是使用了--compact参数之后就不会为false -
--complete-insert: Use complete INSERT statements that include column names, default false -
--skip-add-drop-table: Do not add a DROP TABLE statement before each CREATE TABLE statement, default false -
--skip-add-locks: Do not add locks, default false -
--skip-comments: Do not add comments to dump file, default false -
--skip-extended-insert: Turn off extended-insert, default false. 把多值插入改成追条插入 -
--lock-tables: Lock all tables before dumping them -
--lock-all-tables: Lock all tables across all databases -
--add-drop-database:
如果想要导出全库的同时带有一个drop database if exists <dbname>以及create database <dbname> if no exists: mysqldump --add-drop-database -uroot -pmysql --databases dbname
- 备份 docker 中的 mysql 数据
#!/bin/bash
backupDir=/srv/mysql/backupDir
backupDate=$(date +%Y%m%d)
backupKeepday=30
if [ ! -d $backupDir ]; then
mkdir $backupDir
fi
find $backupDir/*.gz -ctime +$backupKeepday -delete
docker exec mysql \
sh -c 'exec mysqldump test -uroot -p"$MYSQL_ROOT_PASSWORD"' \
| gzip -c > $backupDir/$backupDate.gzmysqldump运行的时候默认会锁数据库,要想实现不锁表,这里:
- MyISAM: 使用
--lock-tables=false - MyISAM: 使用
--single-transaction=true
-
关于索引的比喻: 索引就好比一本书的目录,它会让你更快的找到内容,显然目录(索引)并不是越多越好,假如这本书1000页,有500也是目录,它当然效率低,目录是要占纸张的,而索引是要占磁盘空间的 -
概念: -
mysql索引两种主要结构:-
hash: hash索引在mysql比较少用,他以把数据的索引以hash形式组织起来,因此当查找某一条记录的时候,速度非常快.但是因为是hash结构,每个键只对应一个值,而且是散列的方式分布.所以他并不支持范围查找和排序等功能. -
B+树: b+tree是mysql使用最频繁的一个索引数据结构,数据结构以平衡树的形式来组织,因为是树型结构,所以更适合用来处理排序 范围查找等功能.相对hash索引,B+树在查找单条记录的速度虽然比不上hash索引,但是因为更适合排序等操作,所以他更受用户的欢迎.毕竟不可能只对数据库进行单条记录的操作.
-
-
聚簇索引 主键索引(PRIMARY KEY): 它是一种特殊的唯一索引,不允许有空值,不能重复,很少改变,经常被检索,不能太长,建议使用snowflake生成.ALTER TABLE table_name ADD PRIMARY KEY(column_name) -
唯一索引(UNIQUE): 与普通索引类似,不同的就是,索引列的值必须唯一,但允许有空值.ALTER TABLE table_name ADD UNIQUE(column_name) -
普通索引(INDEX): 最基本的索引,没有任何限制可以有重复,对数据按照索引的规则进行排序,加快查询速度.ALTER TABLE table_name ADD INDEX index_name(column_name) -
全文索引(FULLTEXT): 仅可用于MyISAM表,针对较大的数据,生成全文索引很耗时好空间.ALTER TABLE table_name ADD FULLTEXT(column_name),查询的时候应该使用SELECT * FROM article WHERE MATCH(title, content) AGAINST('查询字符串') -
组合索引(INDEX): 为了更多的提高mysql效率可建立组合索引,遵循最左前缀原则.ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3)
difference-between-key-primary-key-unique-key-and-index-in-mysql
- 主键是一种约束,唯一索引是一种索引,两者本质上是不同的
- 主键创建后一定包含一个唯一性索引,称为主键索引(是一个特殊的唯一索引)
- 主键不能为空,唯一所以可以为空
- 一个表最多只能创建一个主键,但可以创建多个唯一索引
- 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号
- 主键可以被其他表引用为外键,而唯一索引不能
- InnoDB建表时,可不可以不声明主键
- 可以不声明主键,但必须要有聚簇索引(主键和聚集索引不是一个东西,不要混淆)
- 有主键,主键是聚簇索引
- 没有主键,首个非空唯一列是聚簇索引
- 没有符合条件的列,内置生成一个row_id是聚簇索引
- 可以不声明主键,但必须要有聚簇索引(主键和聚集索引不是一个东西,不要混淆)
- InnoDB建表时,可不可以不声明主键非空
- 可以不声明主键非空,会自动加上非空限制
- 如果没有设置自增的话,会使用默认值,
int会是0
- InnoDB建表时,可不可以选择多个字段做主键
- 可以使用联合主键,组合列唯一即可
- InnoDB插入时,可不可以主动插入自增主键
- 可以指定自增列的值,但可能导致空洞
- InnoDB建表时,可不可以使用联合自增主键
- 可以,但自增ID必须在联合主键的第一列
- 主键不能为空,唯一索引可以为空
- 唯一索引允许有多个空值,参考这里
用于提升数据库的查找速度,如果没有索引就要通过遍历来查找数据,如果有索引可以通过索引缩小查找的范围
- 哈希,例如HashMap,
查询/插入/修改/删除的平均时间复杂度都是O(1) - 树,例如平衡二叉搜索树,
查询/插入/修改/删除的平均时间复杂度都是O(lg(n))
为什么所以不设计成哈希而要设计成树呢?其实和sql的需求有关,其本质是tree是有序的数据结构 方便范围查询:
- 如果所有的查询都是进行单行查询
select * from t where name="shenjian";hash时间复杂度是O(1),tree时间复杂度是O(lg(n)),哈希确实比树快多了(如果业务仅仅需要查询单行记录,确实可以使用hash索引,效率更高) - 但是如果查询中存在
group by, order by, between, <、>时,hash时间复杂度会退化为O(n),而有序型的tree时间复杂度是O(log(n)),而范围查询在sql的时间里是很多的,所以索引选择了使用tree而不是hash作为索引的数据格式(另外InnoDB不支持哈希索引)
- 二叉搜索树
- 当数据量大的时候,树的高度会比较高,数据量大的时候,查询会比较慢
- 每个节点只存储一个记录,可能导致一次查询有很多次磁盘IO
- B树(被创造出来就是为了解决索引的数据结构)(B for balance)
- 不再是二叉搜索,而是m叉搜索
- 叶子节点,非叶子节点,都存储数据
- 中序遍历,可以获得所有节点
- B+树(在B-tree基础上做了优化的数据结构)
- 和b-tree一样是m叉搜索
- 仅叶子节点存储数据,非叶子节点不储存数据(仅储存在同一层的叶子节点中)
- 叶子之间,增加了链表,获取所有节点,不再需要中序遍历
B+树比B树更优的原因:
- 范围查找更优: 定位
min与max之后,链表两端的中间叶子节点,就是结果集,不用中序回溯(范围查询在SQL中用得很多,这是B+树比B树最大的优势) - 储存更加紧密: 叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储
- 索引更小适合放进内存: 非叶子节点存储记录的PK,用于查询加速,适合内存存储.不存储实际记录,而只存储记录的KEY的话,那么在相同内存的情况下,B+树能够存储更多索引
- 很适合磁盘存储,能够充分利用局部性原理,磁盘预读
- 局部性原理: 软件设计要尽量遵循"数据读取集中"与"使用到一个数据,大概率会使用其附近的数据",这样磁盘预读能充分提高磁盘IO
- 磁盘预读的思路: 磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载更多的数据,以便未来减少磁盘IO
- 很低的树高度,能够存储大量数据
- 索引本身占用的内存很小
- 能够很好的支持单点查询,范围查询,有序性查询
- 索引名的作用域是每个表,不能在同一个表中有相同的索引名称,但是可以在不同表中使用相同的索引名
- 索引名对性能没有影响
- 索引名对可读性影响很大,建议使用可读性更好的索引名
根据可知,主键和唯一所以都是可以更新的,原则上说关系型数据库的全部数据都是允许更新的,但是这个操作一般是没有意义的(因为大部分的主键是使用无意义的数字作的),另外修改主键会导致聚集索引重建浪费性能
InnoDB发音方式是in-no-dee-bee,MyISAM发音方式是my-eye-sam
InnoDB和MyISAM都是使用b+树实现索引的,索引的类别分成主键索引(Primary Inkex)与普通索引(Secondary Index),两个data engine都是比较常用的引擎,
-
InnoDB支持事务,MyISAM不支持事务(MySQL将默认存储引擎从MyISAM 变成InnoDB的重要原因之一) -
InnoDB最小的锁粒度是行锁,MyISAM最小的锁粒度是表锁.一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限.(MySQL将默认存储引擎从MyISAM 变成InnoDB的重要原因之一) -
InnoDB支持外键,而MyISAM不支持 -
InnoDB是聚集索引,MyISAM是非聚集索引,详情见1分钟了解MyISAM与InnoDB的索引差异-
MyISAM: 索引与行记录是分开存储的,叫做非聚集索引(UnClustered Index),MyISAM可以没有主键,其主键索引与普通索引没有本质差异:- 有连续聚集的区域单独存储行记录(主键和数据分开存储)
- 主键索引的叶子节点,存储主键,与对应行记录的指针
- 普通索引的叶子节点,存储索引列,与对应行记录的指针(普通索引和主键索引没有太大区别)
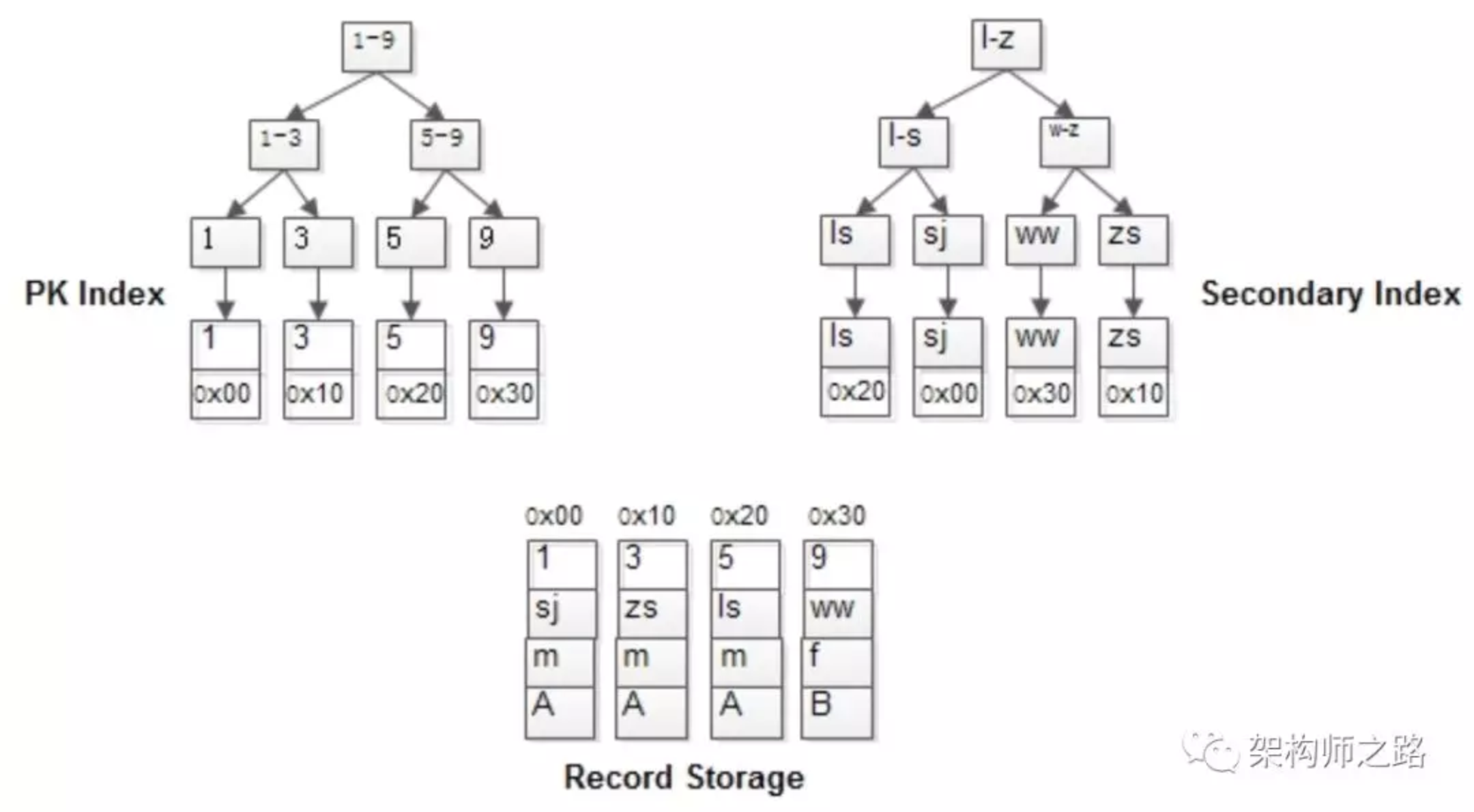
-
InnoDB: 主键索引与行记录是存储在一起的,故叫做聚集索引(Clustered Index)- 没有单独区域存储行记录(主键和数据统一存储)
- 主键索引的叶子节点,存储主键与对应行记录(而不是指针,InnoDB的主键查询是非常快的)
- InnoDB的表有且只有一个聚集索引(因为每一个叶子节点都对应一行数据),这个特性导致:
- 如果表定义了PK,则PK就是聚集索引
- 如果表没有定义PK,则第一个非空unique列是聚集索引
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引
- 由上面的特性产生了一个建议: 建议使用趋势递增的key做主键,由于数据行与索引一体,这样不至于插入记录时,有大量索引分裂,行记录移动
- 普通索引可以有多个,普通索引的叶子节点存储的是主键(innodb不建议使用较长的列做主键 会导致普通索引过于庞大),所以innodb在普通所以查询的时候其实是差了两次索引树(先从普通索引查找记录的主键, 然后查找聚集索引中的实际数据)

-
-
InnoDB不保存表的具体行数,MyISAM用一个变量保存了整个表的行数,select count(*) from table时InnoDB需要全表扫描,而MyISAM只需要读出该变量即可,速度很快 -
InnoDB在磁盘中保存成同一个文件其大小受制于操作系统,一般为2GB,MyISAM存储成三个文件: 表定义文件.frm,数据文件.MYD(MYData),索引文件.MYI(MYIndex)
在数据库优化上有两个主要方面: 即安全与性能
- 安全: 数据可持续性
- 性能: 数据的高性能访问
硬件、系统配置、数据库表结构、SQL及索引,其中优化选择为:
- 优化成本: 硬件 > 系统配置 > 数据库表结构 > SQL及索引
- 优化效果: 硬件 < 系统配置 < 数据库表结构 < SQL及索引
GRANT ALL ON my_db.* TO 'new_user'@'localhost';
REVOKE ALL PRIVILEGES ON phpmyadmin.* FROM 'phpmyadmin'@'localhost';
show processlist;如何加载内置/第三方插件,如何限制插件不被卸载。参考
MySQL 里面的锁大致可以分成全局锁、表级锁和行锁三类
全局锁就是对整个数据库实例加锁。MySQL 提供了一个加全局读锁的方法,命令是Flush tables with read lock(FTWRL)。加了全局读锁后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。其中一个场景是 全局锁的典型使用场景是,做全库逻辑备份。通过全局读锁来备份数据库可能面临如下风险
- 如果在主库备份,在备份期间不能更新,业务停摆
- 如果在从库备份,备份期间不能执行主库同步的binlog,导致主从延迟
为了解决上面的问题,mysql官方提供了mysqldump工具,如果使用--single-transaction导数据之前就会启动一个事务,来确保拿到一致性视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的。既然有了mysqldump这个参数,为什么还要FTWRL?是因为--single-transaction仅适用与支持事务的存储引擎,也就是MyISAM不支持,所以这个主要是用来备份MyISAM的,保证其在备份的时候不会导致数据不一致
分成两种:表锁、元数据锁。
表锁是在Server层实现的。ALTER TABLE之类的语句会使用表锁,忽略存储引擎的锁机制。表锁的语法是lock tables … read/write。与FTWRL类似,可以用unlock tables主动释放锁,也可以在客户端断开的时候自动释放。需要注意,lock tables 语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象。
有时候数据库没有响应,运行show processlist发现有部分状态是Waiting for table metadata lock,为了查找是什么事务导致,查看这里
SHOW ENGINE INNODB STATUS \G
-- Look for the Section -
TRANSACTIONS
-- 或者查找 INFORMATION_SCHEMA 数据库
-- all the locks transactions are waiting
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
-- list of blocking transactions
SELECT * FROM INNODB_LOCKS WHERE LOCK_TRX_ID IN (SELECT BLOCKING_TRX_ID FROM INNODB_LOCK_WAITS);
--
SELECT INNODB_LOCKS.*
FROM INNODB_LOCKS
JOIN INNODB_LOCK_WAITS
ON (INNODB_LOCKS.LOCK_TRX_ID = INNODB_LOCK_WAITS.BLOCKING_TRX_ID);
-- 查看特定的标
SELECT * FROM INNODB_LOCKS
WHERE LOCK_TABLE = db_name.table_name;-- 新建用户并设置密码
create user 'username'@'localhost' identified by 'password'; -- 如果想要都能访问就 'username'@'%'
-- 刷新
flush privileges;
-- 新建数据库并指定数据库编码以及字符序 CHARSET指定数据库编码 COLLATE指定字符序
-- mysql的字符序遵从命名惯例.以_ci(表示大小写不敏感),以_cs(表示大小写敏感),以_bin(表示用编码值进行比较)
create database test DEFAULT CHARSET utf8 COLLATE utf8_general_ci;通用的方式
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(create_definition,...)]
[table_options]
[partition_options]
[IGNORE | REPLACE]
[AS] query_expression
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
{ LIKE old_tbl_name | (LIKE old_tbl_name) }例子
CREATE TABLE person (
number INT(11) AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
birthday DATE
);一般的语法
DROP [TEMPORARY] TABLE [IF EXISTS]
tbl_name [, tbl_name] ...
[RESTRICT | CASCADE]外键约束更新/删除一般有四个可选的参数no action set null set default cascade
restrict: 当在主键表中删除对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除
no action: 表示不做任何操作
set null: 表示在外键表中将相应字段设置为null
set default: 表示设置为默认值
cascade: 表示级联操作,就是说,如果主键表中被参考字段更新,外键表中也更新,主键表中的记录被删除,外键表中改行也相应删除
外键on cascade约束,当对应主键表的字段改变时同时改变外键表中的字段,一般常用的为on update cascade(级联更新)和on delete cascade(级联删除)
- 级联更新: 当主键表中的记录更新时候更新外键表
- 级联删除: 当主键表中的记录删除时删除外键表
- insert 多条记录
insert into table_name values (1),(2),(3),(4),(5); - Mysql条件语句in与or效率对比:
- 如果in和or所在列有索引或者主键的话,or和in没啥差别,执行计划和执行时间都几乎一样
- 如果in和or所在列没有索引的话,性能差别就很大了,in胜出
-
set命令:SET @var_name = value或者使用SET @var := value
查看sql语句的执行计划使用: explain <sql-statement>,返回字段对应的类型如下,详情见:
| Column | JSON Name | Meaning |
|---|---|---|
| id | select_id | The SELECT identifier |
| select_type | None | The SELECT type |
| table | table_name | The table for the output row |
| partitions | partitions | The matching partitions |
| type | access_type | The join type 从好到差的连接类型为const、eq_reg、ref、range、indexhe和all |
| possible_keys | possible_keys | The possible indexes to choose |
| key | key | The index actually chosen |
| key_len | key_length | The length of the chosen key |
| ref | ref | The columns compared to the index |
| rows | rows | Estimate of rows to be examined |
| filtered | filtered | Percentage of rows filtered by table condition |
| Extra | None | Additional information |
- 整除:
5 div 2= 2 - 取余:
5 mod 2= 1 - 四舍五入:
round(1.5)= 2 - 创建一个一定范围内的随机数:
floor(rand() * (<max> - <min> + 1)) + <min>
-
last_insert_id():表中含自增字段(auto_increment),向表insert一条记录后,可以调用last_insert_id()来获得最近insert的那行记录的自增字段值- 向含auto_increment字段的表中正常插入一条记录后,last_insert_id()会返回表中自增字段的当前值
- 若在同一条insert语句中插入多行
insert into table_name(col_a, col_b) values('aa', 'bb'), ('aaa', 'bbb'),则last_insert_id()返回的自增字段的"当前值"只在旧值的基础上加1,这与事实不符,应该会是增加插入的条数 - 指定自增id的值后last_insert_id()的值不变,
insert into table_name(id, name) values(11, 'test3');如果此时id是auto_increment但是值指定,则last_insert_id的值不变 - 如果sql语句执行出错,事务因执行出错回滚,则last_insert_id()的值不会恢复到事务执行前的那个值
- order by rand(): You cannot use a column with RAND() values in an ORDER BY clause, because ORDER BY would evaluate the column multiple times.
- 日期加减相应的值:
date(date_add("date_time", INTERVAL -1 DAY)) - select正则字段,mysql 8.0之前不支持,如果8.0之前需要使用可以通过
length及location方法合并使用select CAST(RIGHT(url, LENGTH(url) - 3 - LOCATE('&id=', url)) from table_name
-
convert str to date:
str_to_dateselect str_to_date('2017-10-01', '%Y-%m-%d') from dual;
-
监测mysql记录是否存在 best way to test if a row exists in a mysql table
select exists(select 1 from table_name where ...)- 记录不存在insert存在update
# 指定插入的值
insert into table_name (a,b,c) values (1,2,3) on duplicate key update c=c+1;
# 从表中选择插入的值
insert into table_name (a,b,c) select a,b,c from table_name_1 on duplicate key update c=c+1;------------------
-- 索引相关
------------------
-- 创建主键
alter table tablename add primary key (`column`);
-- 创建unique索引
alter table tablename add unique index (`key`);
-- 创建普通索引
alter table tablename add index index_name (`column`);
-- 创建全局索引
alter table tablename add fulltext (`column`);
-- 添加多列索引
alter table tablename add index index_name (`column1`, `column2`, `column3`);
-- 删除key键 unique索引
alter table tablename drop index `key`;
------------------
-- 表相关
------------------
-- 修改表名
alter table old_tablename rename to new_tablename;
rename table old_table to new_table;
------------------
-- 字段相关
------------------
-- 修改字段类型 modify 只改除了字段名的别的约束
alter table tablename modify column char(10);
alter table tablename modify column bigint not null default 100; -- 改变字段类型 not null约束 默认值
-- 增加普通字段
alter table tablename add new_column varchar(10) not null default 'defaultValue';
-- 增加主键 增加唯一索引只需要将 primary key 改成
alter table tablename add id int unsigned not null auto_increment primary key;
-- 修改字段
alter table tablename change old_column new_column int not null;
-- 删除普通字段
alter table tablename drop column;
-- 调整字段顺序 使用 after 或者 before 关键字
alter table table_name modify column column_name varchar(100) comment 'comment' after column_name1;# 更新单个字段
update table_name set col = val where col1 = 123
# 更新多个字段
update table_name set col1 = val1, col2 = val2 where col3 = 123;
# 多表联合更新
update table_name_1 t1, table_name_2 t2
set t1.col = t1.col + t2.col
where t1.col1 = '2017-09-20'
and t2.col1='2017-09-19'
and t1.uid = t2.uid;
update table_name_1 t1
inner join table_name_2 t2
on t1.uid = t2.uid
set t1.col = t1.col + t2.col
where t1.col1 = '2017-09-20'
and t2.col1='2017-09-19';一个表建立了唯一索引,当我们再向这个表中使用已经存在的键值insert一条记录,那将会抛出一个主键冲突的错误.如果想要用新记录的值来覆盖原来的记录值.方法一是使用delete语句删除原先的记录,然后再使用insert新的记录.方法二是使用replace语句.
使用replace插入一条记录时,如果不重复,replace就和insert的功能一样,如果有重复记录,REPLACE就使用新记录的值来替换原来的记录值.使用REPLACE的最大好处就是可以将delete和insert合二为一,形成一个原子操作.这样就可以不必考虑在同时使用DELETE和INSERT时添加事务等复杂操作了.
**注意:**在使用REPLACE时,表中必须有唯一索引,而且这个索引所在的字段不能允许空值,否则REPLACE就和INSERT完全一样的
# 单条记录
replace into users (id,name,age) values(123, '赵本山', 50);
# 多条记录
replace into users(id, name, age) values(123, '赵本山', 50), (134,'mary',15);-
使用mysqldump时报错 Warning: World-writable config file '/etc/mysql/my.cnf' is ignored,是使用 docker-compose 运行 mysql 的,在这里看到是配置文件的权限不对,对外部卷的配置文件进行修改
sudo chmod 0644 /etc/mysql/my.cnf,重启 mysql 后正常运行 -
用
load data infile导入数据报错: The MySQL server is running with the --secure-file-priv option so it cannot execute this statement,最简单的方法是增加一个local关键字load data local infile -
local data local infile报错:The used command is not allowed with this MySQL versionMySQL: Enable LOAD DATA LOCAL INFILE -
查看mysql的警告:
show warnings; -
求表里分组的最大值的记录: SQL select only rows with max value on a column
-
如果要求的只有两列数据
select id , max(rev) from yourtable group by id
-
如果除了分组列和值列还有别的列
select a.id , a.rev , a.contents from yourtable a inner join ( select id , max(rev) rev from yourtable group by id ) b on a.id = b.id and a.rev = b.rev -- left joining with self, tweaking join conditions and filters -- 较快 select a.* from yourtable a left outer join yourtable b on a.id = b.id and a.rev < b.rev where b.id is null ---------------------------------------- -- 额外的方式 ---------------------------------------- -- 关联子查询 (较慢,有max) select name,course,score from yourtable a where rev = ( select max(rev) from yourtable b where a.id = b.id ) -- no exists select * from yourtable a where not exists ( select 1 from yourtable b where a.id = b.id and a.score < b.score );
-
-
查看表里的
top n条记录,MySQL获取分组后的TOP 1和TOP N记录-- 数据分析较小的话直接用union all将多个分组的值拼接起来 select name,course,score from test1 where course='语文' order by score desc limit 2 union all select name,course,score from test1 where course='数学' order by score desc limit 2 union all select name,course,score from test1 where course='英语' order by score desc limit 2
-
链接mysql时报错
MySQL无法连接[MySql Host is blocked because of many connection errors]: 同一个ip在短时间内产生太多(超过mysql数据库max_connection_errors的最大值)中断的数据库连接而导致的阻塞,解决方法mysqladmin flush-hosts -h192.168.1.1 -P3308 -uroot -ppassword
可以将复杂sql拆分成多个简单sql进行查询,例如统计里面有部分维度是空导致统计结果缺失,第一次查询可以先查询所有的维度,然后生成一个所有维度为key,0为value的Map,第二次查询统计数据库的值,然后更新这个Map得到最后的结果.
Map<String, Long> hourStatsMap = new HashMap<>();
for (int i = 0; i <= 23; i++) {
hourStatsMap.put(Integer.toString(i), 0L);
}
hourStats = appMonitorService.getHourStats(year, month, day, appId);
for (Map m : hourStats) {
String key = m.get("hour").toString();
Long count = (Long) m.get("count");
hourStatsMap.put(key, count);
}in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询.不能认为exists比in的效率高
- 如果查询的两个表大小相当,那么用in和exists差别不大
- 如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in
可以将要累/减的主键自关联,并通过聚合得到累加/减的情况
-- 初始化
drop table if exists cum_demo;
CREATE TABLE cum_demo (id INT,money INT,starttime int,PRIMARY KEY (id));
insert into cum_demo(id,money,starttime) values (1,10, 201901),(2,20, 201902),(3,30, 201903),(4,40, 201904);-- 自关联及其结果
select *
from cum_demo a
left outer join cum_demo b
on a.starttime >= b.starttime;-- 统计的结果
select a.starttime
, sum(b.money) as asum
from cum_demo a
left outer join cum_demo b
on a.starttime >= b.starttime
group by a.starttime看看这个问题, 详细的解释有这个, 但是如果插入多行记录中有null值就没问题,见这里
-- 创建一张有default value的表
create table table_name(
id int,
name varchar(100) not null,
sex char(1) not null defalut 'M'
);
-- 下面的insert语句会报错 sex不能为null值 因为ddl中声明了不能为null
insert into table_name(id, name, sex) value(1, 'myName', null);
-- 正确的做法应该是用default关键字声明使用默认值 或者在table后面不加对应的字段
insert into table_name(id, name, sex) value(1, 'myName', default);
insert into table_name(id, name) value(1, 'myName');
-- 不会报错但是有2个warning
-- 这是另外一个问题了
-- 这时 mysqld 的配置问题 sql_mode 没有声明成 strict_all_tables, 声明了之后也会报错 见[21]
insert into table_name(id, name, sex) values(1, 'myName', 'F'), (2, 'yourName', null);
-- 如果想要实现我们预想的情况 可以写一个插入前的触发器 就能处理在插入前转换值了
CREATE TRIGGER `trg_table_name_sex_default_value` BEFORE INSERT ON `table_name`
FOR EACH ROW
BEGIN
IF (NEW.`sex` IS NULL) THEN
SET NEW.`sex` := (
SELECT `COLUMN_DEFAULT`
FROM `information_schema`.`COLUMNS`
WHERE `TABLE_SCHEMA` = DATABASE()
AND `TABLE_NAME` = 'table_name'
AND `COLUMN_NAME` = 'sex'
);
END IF;
END
-- 或者在应用的层名做 每次调用插入的时候先检查插入的字段是否有空值 有的话将其变成设置的默认值(推荐)- 匹配数字:
[0-9]或者[[:digit:]] - 匹配前面多个数字:
[0-9]{10}或者[[:digit:]]{10}
- 在mysql里面时.使用
INTO OUTFILE到指定的文件,然后source文件,详见这里
SELECT CONCAT('OPTIMIZE TABLE `', ist.TABLE_SCHEMA,'`.', ist.TABLE_NAME, ';')
FROM INFORMATION_SCHEMA.TABLES ist
WHERE table_schema = 'my_schema'
INTO OUTFILE '/tmp/my_optimization';
SOURCE 'tmp/my_optimization';- 如果想要直接在shell中调用
# 这个会产生很多无用的输入 如果仅想要保存自己需要的文件到 /path/to/results.txt 可以在重定向前增加 grep -E 进行正则过滤
mysql -vv -u usr -p pwd < sql_file_name > /path/to/results.txtThe DATETIME type is used when you need values that contain both date and time information. MySQL retrieves and displays DATETIME values in 'YYYY-MM-DD HH:MM:SS' format. The supported range is '1000-01-01 00:00:00' to '9999-12-31 23:59:59'.
...
The TIMESTAMP data type has a range of '1970-01-01 00:00:01' UTC to '2038-01-09 03:14:07' UTC. It has varying properties, depending on the MySQL version and the SQL mode the server is running in.
-
datetime是一个常量,timestamp是一个随着time_zone变化的变量,是一个确切的时间(相对UTC)的时间 - 应该使用
datetime作为元数据的记录字段,因为范围更加广,且是固定值,不会随着时区变化而变化.如果想要配置插入和更新的默认值,使用datetime not null default current_timestamp on update current_timestamp -
timestamp经常用于追踪记录的变化,记录每次更新他也会更新.如果想要储蓄具体的时间请使用datetime -
datetime代表日期(如日历所见)和时间(如时钟所见),timestamp代表具体的带有时区的时间点 - 对
datetime查询不会被缓存,但是对timestamp查询会被缓存 - 如果想在应用中使用
unixtime,还是应该使用datetime类型,因为可以方便的使用select unix_timestamp('2019-01-01')
-
突然的业务办理卡顿,无法进行正常的业务处理
-- 查看进程列表 show processlist -- 查看执行计划 explain select id ,name from stu where name='clsn'; -- 查看表的索引 show index from table; -- 通过执行计划判断,索引问题(有没有、合不合理)或者语句本身问题 -- 查看锁状态 show status like '%lock%'; -- 杀掉有问题的session kill SESSION_ID;
MySQL NOT IN query giving wrong results: 如果not in遇到null,会返回0条结果
通过show processlist获取了进程id后,通过kill id命令删除了进程但是再次运行show processlist还能看到id,不过状态是killed,那是因为数据库可能在回滚事务,参考这里
mysql分区表使用了range to_days,如果第一个分区有很多记录,可能会带来性能问题,原因是这里,mysql的查询优化器无论查询的条件如果都会检索第一个分区,解决办法设置一个条件将第一个分区记录数变成0,这样即使检索第一个分区也不会影响性能。相关的链接
mysql8.0.13之前的都不支持,仅有8.0.13以及之后的才支持,这里
在《高性能Mysql》这本书的‘如何使用分区’这一小章中,列举的常见问题中。有以下一个问题:分区列和索引列不匹配如果定义的索引列和分区列不匹配,会导致查询无法进行分区过滤。
假设在列a上定义了索引,而在列b上定义的分区。因为每个分区都有其独立的索引,所以扫描列b上的索引就需要扫描每个分区内对应的索引。要避免这个问题,应该避免建立和分区列不匹配的索引,除非查询中还同时包含了可以过滤分区的条件。
- 计算资源不足
- 系统层面未进行基本的优化,或不同进程间资源抢占
- MySQL 配置不科学附神器
- 垃圾 SQL 满天飞
-
top查看整体负载情况,快速确认哪个进程系负载高 -
free查看内存情况,是否有内存泄露和用了swap等风险 -
vmstat/sar查看当前系统瓶颈到底在哪,如 CPU、IO、网络等 - 终极神器
perf top查看 cpu 消耗在哪些系统调用函数
- 观察
show processlist输出中是否有临时表、排序、大量逻辑读、锁等待等状态 - 观察
show engine innodb status输出中是否有大事务、长事务、锁等待等状态
- 用
explain、desc观察执行计划 - 用 profiling 定位 sql 执行的瓶颈
- 用 pt-query-digest 分析慢 sql
- mysqld 进程消耗 CPU 长时间超过 90% 的话,99.9% 是因为没用好索引
- cpu 的 %sys 高的话,大概率是 swap 或中断不均衡导致,也可能是有多个索引且超高并发写入(更新),或者有很严重的锁等待事件
- 最⼤的瓶颈通常是在磁盘 I/O 上,因此尽量用高速磁盘设备
- 如果物理磁盘无法再升级,则通过增加内存提升性能容量
- 遇到无法诊断的问题时,试试⽤ perf top 来观测跟踪
- SQL 执行慢,有时未必是效率低,也可能是因为锁等待,甚⾄是磁盘满了
EXPLAIN
SELECT *
FROM sszpay_order
-- 这个组合的in查询会导致 sku_id 和 user_id 的索引失效
WHERE (sku_id, user_id) IN ((12067, 5), (12583, 5))