HDFS - zhongjiajie/zhongjiajie.github.com GitHub Wiki
全部的命令行参考Hadoop-The File System (FS) shell
查看目录下的文件
-
hdfs dfs -ls /path: 查看/path下面有什么文件 -
hdfs dfs -ls -t -r /path: 按时间倒序 -
hdfs dfs -ls /path | awk '{ print $8 }' | xargs -I % echo 'hdfs dfs -du -s %' | sh: 查看指定路径下各个文件夹的容量大小
相关的option:
-
-h: 人更易读懂的描述 -
-r: 反转,倒序 -
-t: 按照时间排序 -
-R: 递归文件夹,知道显示文件
删除指定文件或文件夹
相关的option:
-
-r: 删除文件夹 -
-skipTrash: 跳过回收站,直接删除文件
读取文件hdfs dfs -cat <HDFS_FILE_PATH>
查看文件/文件夹大小hdfs dfs -du <HDFS_PATH>
相关option:
-
-h: 人更易读懂的描述
-
hdfs dfs -expunge: 清空回收站
difference between "hadoop fs" and "hdfs dfs" shell commands
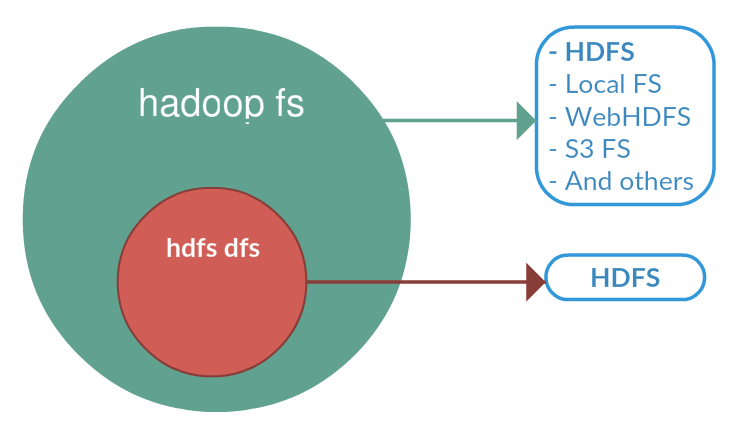
- 根据官网The File System (FS) shell includes various shell-like commands that directly interact with the Hadoop Distributed File System (HDFS) as well as other file systems that Hadoop supports, such as Local FS, WebHDFS, S3 FS, and others.
bin/hadoop fs <args>- All FS shell commands take path URIs as arguments. The URI format is scheme://authority/ path. For HDFS the scheme is hdfs, and for the Local FS the scheme is file. The scheme and authority are optional. If not specified, the default scheme specified in the configuration is used. An HDFS file or directory such as /parent/child can be specified as hdfs://namenodehost/parent/child or simply as /parent/child (given that your configuration is set to point to hdfs://namenodehost).
- 如果File System使用的是HDFS,则
hadoop fs等同于hdfs dfs
hive或者spark的文件保存到HDFS时,会产生了_SUCCESS以及_metadata和_common_metadata文件夹,如果不想要产生这些文件夹(因为这些文件夹没有用并且会导致sql报错).可以调整相关配置:
-
mapreduce.fileoutputcommitter.marksuccessfuljobs=false: 不产生_SUCCESS文件 -
parquet.enable.summary-metadata=false: 不产生_metadata及_common_metadata文件
如果是spark-on-yarn的情况,运行spark-thrift-server相关的配置是:
spark.hadoop.mapreduce.fileoutputcommitter.marksuccessfuljobs=false-
spark.hadoop.parquet.enable.summary-metadata=false(parquet的配置仅需要在spark2.0之前配置,因为2.0之后已经默认是不产生_metadata以及_common_metadata的了,相关jira)
如果使用sparkContext,相关的配置是:
sc.hadoopConfiguration.set("mapreduce.fileoutputcommitter.marksuccessfuljobs", "false")sc.hadoopConfiguration.set("parquet.enable.summary-metadata", "false")
Non DFS used的计算公式是: Non DFS Used = Configured Capacity - Remaining Space - DFS Used
- 因为Configured Capacity = Total Disk Space - Reserved Space,所以Non DFS used = (Total Disk Space - Reserved Space) - Remaining Space - DFS Used
- reserved space对应的配置是
dfs.datanode.du.reserved
下面是一个具体例子:
Let's take a example. Assuming I have 100 GB disk, and I set the reserved space (
dfs.datanode.du.reserved) to 30 GB.In the disk, the system and other files used up to 40 GB, DFS Used 10 GB. If you run df -h , you will see the available space is 50GB for that disk volume.
In HDFS web UI, it will show
Non DFS used = 100GB(Total) - 30 GB(Reserved) - 10 GB (DFS used) - 50GB(Remaining) = 10 GB也可以理解成40 GB - 30 GB(Reserved)So it actually means, you initially configured to reserve 30G for non dfs usage, and 70 G for HDFS. However, it turns out non dfs usage exceeds the 30G reservation and eat up 10 GB space which should belongs to HDFS!
The term "Non DFS used" should really be renamed to something like
How much configured DFS capacity are occupied by non dfs use
详细查看这里
- Over-replicated blocks: These are blocks that exceed their target replication for the file they belong to. Normally, over-replication is not a problem, and HDFS will automatically delete excess replicas.
- Under-replicated blocks: These are blocks that do not meet their target replication for the file they belong to. HDFS will automatically create new replicas of under-replicated blocks until they meet the target replication. You can get information about the blocks being replicated (or waiting to be replicated) using hdfs dfsadmin -metasave .
- Misreplicated blocks: These are blocks that do not satisfy the block replica placement policy (see Replica Placement). For example, for a replication level of three in a multirack cluster, if all three replicas of a block are on the same rack, then the block is misreplicated because the replicas should be spread across at least two racks for resilience. HDFS will automatically re-replicate misreplicated blocks so that they satisfy the rack placement policy.
- Corrupt blocks: These are blocks whose replicas are all corrupt. Blocks with at least one noncorrupt replica are not reported as corrupt; the namenode will replicate the noncorrupt replica until the target replication is met.
- Missing replicas: These are blocks with no replicas anywhere in the cluster.