NLP_wordEmbedding - yunfanfan/Notes GitHub Wiki
是一种词的类型表示,具有相似意义的词具有相似的表示,是将词汇映射到实数向量的方法总称。
什么是词嵌入
词嵌入实际上是一类技术,单个词在预定义的向量空间中被表示为实数向量,每个单词都映射到一个向量。举个例子,比如在一个文本中包含“猫”“狗”“爱情”等若干单词,而这若干单词映射到向量空间中,“猫”对应的向量为(0.1 0.2 0.3),“狗”对应的向量为(0.2 0.2 0.4),“爱情”对应的映射为(-0.4 -0.5 -0.2)(本数据仅为示意)。像这种将文本X{x12345……xn12345……yn },这个映射的过程就叫做词嵌入。
之所以希望把每个单词都变成一个向量,目的还是为了方便计算,比如“猫”,“狗”,“爱情”三个词。对于我们人而言,我们可以知道“猫”和“狗”表示的都是动物,而“爱情”是表示的一种情感,但是对于机器而言,这三个词都是用0,1表示成二进制的字符串而已,无法对其进行计算。而通过词嵌入这种方式将单词转变为词向量,机器便可对单词进行计算,通过计算不同词向量之间夹角余弦值cosine而得出单词之间的相似性。
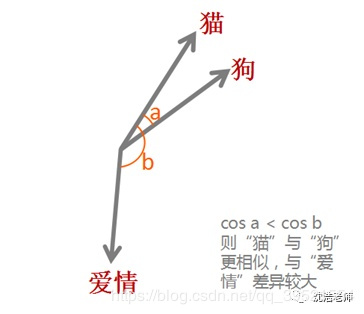
此外,词嵌入还可以做类比,比如:v(“国王”)-v(“男人”)+v(“女人”)≈v(“女王”),v(“中国”)+v(“首都”)≈v(“北京”),当然还可以进行算法推理。有了这些运算,机器也可以像人一样“理解”词汇的意思了。
主要算法
Embedding Layer
该嵌入方法将清理好的文本中的单词进行one hot编码(热编码),向量空间的大小或维度被指定为模型的一部分,例如50、100或300维。向量以小的随机数进行初始化。Embedding Layer用于神经网络的前端,并采用反向传播算法进行监督。
这种学习嵌入层的方法需要大量的培训数据,可能很慢,但是可以学习训练出既针对特定文本数据又针对NLP的嵌入模型。
Word2Vec(Word to Vector)/ Doc2Vec(Document to Vector)
Word2Vec是由Tomas Mikolov 等人在《Efficient Estimation of Word Representation in Vector Space》一文中提出,是一种用于有效学习从文本语料库嵌入的独立词语的统计方法。其核心思想就是基于上下文,先用向量代表各个词,然后通过一个预测目标函数学习这些向量的参数。Word2Vec 的网络主体是一种单隐层前馈神经网络,网络的输入和输出均为词向量。
该算法给出了两种训练模型,CBOW (Continuous Bag-of-Words Model) 和 Skip-gram (Continuous Skip-gram Model)。CBOW将一个词所在的上下文中的词作为输入,而那个词本身作为输出,也就是说,看到一个上下文,希望大概能猜出这个词和它的意思。通过在一个大的语料库训练,得到一个从输入层到隐含层的权重模型;而Skip-gram它的做法是,将一个词所在的上下文中的词作为输出,而那个词本身作为输入,也就是说,给出一个词,希望预测可能出现的上下文的词,2-gram比较常用。

Word2Vec虽然取得了很好的效果,但模型上仍然存在明显的缺陷,比如没有考虑词序,再比如没有考虑全局的统计信息。
Doc2Vec与Word2Vec的CBOW模型类似,也是基于上下文训练词向量,不同的是,Word2Vec只是简单地将一个单词转换为一个向量,而Doc2Vec不仅可以做到这一点,还可以将一个句子或是一个段落中的所有单词汇成一个向量,为了做到这一点,它只是将一个句子标签视为一个特殊的词,并且在这个特殊的词上做了一些处理,因此,这个特殊的词是一个句子的标签。如图所示,词向量作为矩阵W中的列被捕获,而段落向量作为矩阵D中的列被捕获。
GloVe(Global Vectors for Word Representation)
GloVe是Pennington等人开发的用于有效学习词向量的算法,结合了LSA矩阵分解技术的全局统计与word2vec中的基于局部语境学习。
LSA全称Latent semantic analysis,中文意思是隐含语义分析,LSA算是主题模型topic model的一种,对于LSA的直观认识就是文章里有词语,而词语是由不同的主题生成的,比如一篇文章包含词语:计算机,另一篇文章包含词语:电脑,在一般的向量空间来看,这两篇文章不相关,但是在LSA看来,这两个词属于同一个主题,所以两篇文章也是相关的。该模型不依赖本地上下文,是对全局字词同现矩阵的非零项进行训练,其中列出了给定语料库中单词在彼此间共同出现的频率。
词嵌入案例
可以选择采用开源的预先训练好的词嵌入模型,研究人员通常会免费提供预先训练的词嵌入,例如word2vec和GloVe词嵌入都可以免费下载。