(2次翻译及理解)Hierarchical Attention Networks for Document Classification - yunfanfan/Notes GitHub Wiki
Hierarchical Attention Networks for Document Classification 论文第二次翻译及理解
二月份的时候啥也不懂,为了完成翻译论文的任务,就配合着谷歌翻译把这篇论文翻译了一遍。现在对自然语言处理及TensorFlow都有初步的理解了,所以现在再重新读一遍论文,顺便修改一下当初翻译的一些错误。
我们提出一种用于文档分类的分层注意力网络。我们的模型具有两个鲜明的特征:(i) 具有反映文档层次结构的层次结构;(ii) 它在单词和句子级别上应用了两个级别的注意机制,使它在构建文档表示形式时能够分别处理更重要和不重要的内容。在六个大型文本分类任务上进行的实验表明,所提出的体系结构在很大程度上优于以前的方法。注意层的可视化说明该模型选择了本质信息丰富的单词和句子。
文本分类是自然语言处理中的基础任务之一。目的是将标签分配给文本。它有着广泛的应用,包括主题标签(Wang 和 Manning,2012 年),情感分类(Maas 等,2011 年;Pang 和 Lee,2008 年),以及垃圾邮件监测(Sahami 等人,1998 年)。文本分类传统的方法代表具有稀疏词汇特征(例如 n-gram)的文档,然后在此表示形式上使用线性模型或者核方法(Wang 和 Manning,2012;Joachims,1998)。最近一些方法使用深度学习,如卷积神经网络(Blunsom 等,2014)和基于长短期记忆(LSTM)的递归神经网络(Hochreiter 和 Schmidhuber,1997)来学习文本表示。尽管基于神经网络的文本分类方法非常有效(Kim,2014;Zhang 等,2015;Johnson 和 Zhang,2014;Tang 等,2015),但在本文中,我们检验了通过将文档结构的知识纳入模型体系结构,可以获得更好的表示的假设。我们模型所基于的直觉是,并非文档的所有部分对于回答查询都具有同等的相关性,并且确定相关部分涉及对单词的交互进行建模,而不仅仅是对单词在交互中单独存在进行建模。(加粗处不理解)

图 1: Yelp 2013 的一个简单示例回顾由 5 个句子组成,以句点,问号分隔。第一个和第三个句子提供了更强的含义,而在内部,单词 delicious,a-m-az-i-n-g 在确定这两个句子的情感方面贡献最大。
我们的主要贡献是新的神经体系结构(第 2 节),即分层注意力网络(HAN),旨在捕获有关文档结构的两个基本理解。首先,由于文档具有层次结构(单词构成句子,句子构成文档),我们构造文档表示形式同样地首先通过构建句子的表示形式,然后将其汇总为文档表示形式。其次,可以观察到文档中的不同单词和句子在携带的信息量上具有差异性。此外,单词和句子的重要性在很大程度上取决于上下文,即,相同的单词或句子在不同的上下文中可能具有不同的重要性(第 3.5 节)。为了包括对这一事实的敏感性,我们的模型包括两个级别的注意力机制(Bahdanau 等,2014;Xu 等,2015)——一个在单词级别,另一个在句子级别——使模型在构建文档表示形式时付出更多或更少的注意力来关注单个单词和句子。为了说明这一点,请考虑图 1 中的示例,该示例是 Yelp 的简短回顾,其任务是以 1-5 的等级预测评级。从直觉上讲,第一句话和第三句话在帮助预测评估上具有更实际的信息;在这些句子中,delicious,a-m-a-z-i-n-g 在暗示本评论中所包含的积极态度上起了更大的作用。注意力有两个好处:不仅经常可以带来更好的性能,而且还可以看出单词和句子对分类决策的贡献,这在应用和分析中是有价值的(Shen 等,2014)。; Gao 等,2014)。与以前的工作的主要区别在于,我们的系统使用上下文来发现一系列令牌何时相关,而不是简单地过滤掉上下文中的(一些系列的)令牌。为了评估模型与其他常见分类体系结构相比的性能,我们查看了六个数据集(第 3 节)。我们的模型大大优于以前的方法。
分层注意力网络(HAN)的总体架构如图 2 所示。它由几个部分组成:一个单词序列编码器,一个单词级注意力层,一个句子编码器和一个句子级注意力层。在以下各节中,我们将描述不同组件的细节。
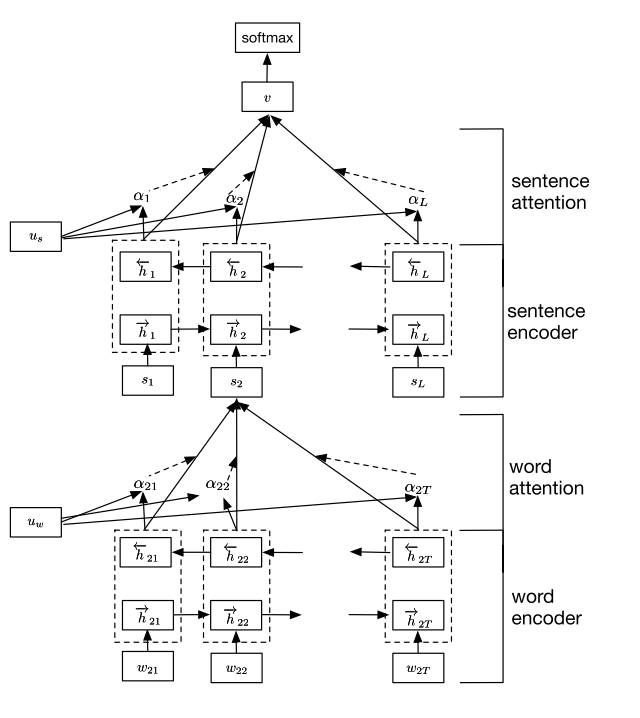
图 2: 层次注意力网络
GRU(Bahdanau 等人,2014)使用门控机制来跟踪序列状态,而无需使用单独的存储单元。门有两种类型:重置门
我们在这项工作中专注于文档级分类,假设一个文档有L个句子s$_i$,每个句子包含T$i$个词。w${it}$且$t\in[1,T]$表示第i个句子中的单词。提出的模型将原始文档投影到矢量表示中,在此基础上我们建立分类器以表现文档分类。接下来,我们将介绍如何通过使用层次结构从单词向量逐步构建文档级向量。
给定一个带有单词w${it}$,$t\in[0, T]$的句子,我们首先通过嵌入矩阵W$e$,$x{ij} = W{e}w_{ij}$将单词嵌入向量中。我们使用双向GRU(Bahdanau等人,2014)通过总结单词两个方向的信息来获取单词注释,从而将上下文信息纳入注释中。双向GRU包含从w${i1}$到w${iT}$读取句子s$i$的正向GRU$\overrightarrow{f}$和从w${iT}$到w${i1}$读取句子s$i$的反向GRU$\overleftarrow{f}$: $$ \begin{aligned} x{i t} &=W{e} w_{i t}, t \in[1, T]\ \overleftarrow{h}{i t} &=\overrightarrow{\operatorname{GRU}}\left(x{i t}\right), t \in[1, T]\ \overleftarrow{h}{i t} &=\overleftarrow{\operatorname{GRU}}\left(x{i t}\right), t \in[T, 1] \end{aligned} $$ 我们通过将前向隐藏状态$\overrightarrow{h_{it}}$和后向隐藏状态$\overleftarrow{h_{it}}$串联在一起,从而获得给定单词w$i$的注释,即$h{it} = [\overrightarrow{h_{it}},\overleftarrow{h_{it}}]$,它概括了以w$_{it}$为中心的整个句子的信息。请注意,我们直接使用词嵌入。 对于更完整的模型,类似于(Ling等人,2015),我们可以使用GRU直接从字符中获取单词向量。 为了简单起见,我们省略了它。
并非所有单词都对句子含义的表达具有同等作用。 因此,我们引入了注意力机制来提取对句子的意义很重要的单词,并聚合这些信息性单词的表示形式以形成句子向量。 具体而言, $$ u_{i t}=\tanh \left(W_{w} h_{i t}+b_{w}\right) $$
就是说,我们首先通过一层MLP(多层感知器)来提供单词注释h${it}$,以获取u${it}$作为h${it}$的隐藏表示,然后我们将单词的重要性作为u${it}$与单词级别上下文向量u$w$的相似性进行度量,并通过softmax函数获得归一化的重要性权重 $\alpha{i t}$。之后,我们根据权重计算句子向量s$_i$(此处滥用注释)作为单词注释的加权和。 上下文向量u$_w$可以看作是固定查询“什么是信息性单词”的高级表示,类似于存储网络中使用的单词(Sukhbaatar等,2015; Kumar等,2015)。 单词上下文向量u$_w$在训练过程中随机初始化并共同学习。
多层感知器(Multilayer Perceptron,缩写MLP)是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以被看作是一个有向图,由多个的节点层所组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。一种被称为反向传播算法的监督学习方法常被用来训练MLP。MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。
给定句子向量s$i$,我们可以以类似的方式获得文档向量。 我们使用双向GRU对句子进行编码: $$ \begin{aligned} &\overrightarrow{h}{i}=\overrightarrow{\mathrm{GRU}}\left(s_{i}\right), i \in[1, L]\ &\overleftarrow{h}{i}=\overleftarrow{\operatorname{GRU}}\left(s{i}\right), t \in[L, 1] \end{aligned} $$ 我们将$\overrightarrow{h_{i}}$和$\overleftarrow{h_j}$连接起来,得到句子i的注释,即$h_i = [\overrightarrow{h_{i}}, \overleftarrow{h_j}]$。 h$_{i}$概述了句子i周围的邻居句子,但仍然专注于句子i。
为了奖励作为正确分类文档线索的句子,我们再次使用注意机制并引入句子级别上下文向量,然后使用该向量来衡量句子的重要性。这就产生了 $$ \begin{aligned} u_{i} &=\tanh \left(W_{s} h_{i}+b_{s}\right) \ \alpha_{i} &=\frac{\exp \left(u_{i}^{\top} u_{s}\right)}{\sum_{i} \exp \left(u_{i}^{\top} u_{s}\right)} \ v &=\sum_{i} \alpha_{i} h_{i} \end{aligned} $$ 其中$v$是总结文档中句子所有信息的文档向量。类似地,句子级上下文向量可以在训练过程中随机初始化和联合学习。
文档向量$v$是文档的高级表示,可以用作文档分类的特征: $$ p=\operatorname{softmax}\left(W_{c} v+b_{c}\right) $$ 我们使用正确标签的负对数似然作为训练损失: $$ L=-\sum_{d} \log p_{d j} $$ 其中j是文档d的标签。
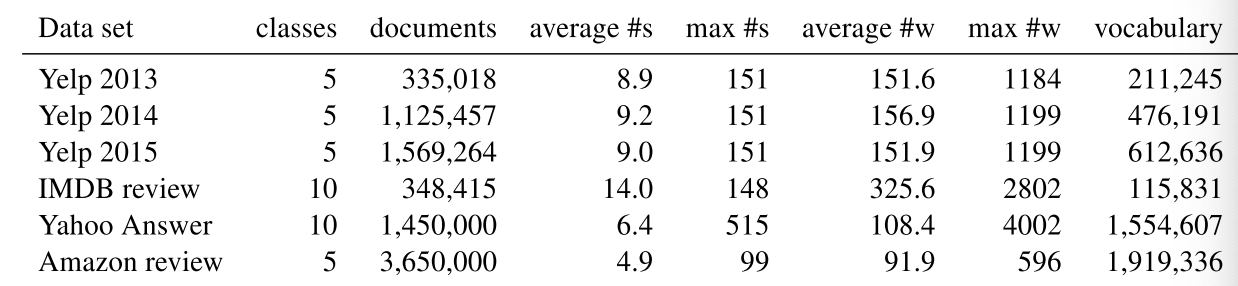
表1:数据统计:#s表示句子数(每个文档的平均数和最大值),#w表示单词数(每个文档的平均数和最大值)
我们在六个大型文档分类数据集上评估了模型的有效性。 这些数据集可以分为两种类型的文档分类任务:情感估计和主题分类。 数据集的统计信息总结在表1中。除非另有说明,否则我们将80%的数据用于训练,10%的数据用于验证,将其余10%的数据用于测试。
- Yelp评论 来自2013年,2014年和2015年的Yelp数据集挑战赛(Tang等人,2015年)。评分分为5级(从1到5)(越高越好)。
- IMDB评论来自(Diao等人,2014)。评分范围从1到10。
- Yahoo的答案来自(Zhang等人,2015)。这是一个主题分类任务,分为10个班级:社会与文化,科学与数学,健康,教育与参考,计算机与互联网,体育,商业与金融,娱乐与音乐,家庭与关系以及政治与政治。政府。我们使用的文档包括问题标题,问题上下文和最佳答案。有140,000个训练样本和5000个测试样本。原始数据集不提供验证样本。我们随机选择10%的训练样本作为验证。
- 亚马逊评论来自(Zhang等人,2015)。评分从1到5。3,000,000条评论用于培训,650,000条评论用于测试。同样,我们使用10%的训练样本作为验证。
我们将HAN与几种基线方法进行了比较,包括使用神经网络,LSTM,基于单词的CNN,基于字符的CNN和Conv-GRNN,LSTM-GRNN的线性方法,SVM和段落嵌入等传统方法。这些基线方法和结果在(Zhang 等人,2015; Tang 等人,2015)
线性方法(Zhang等人,2015)使用构造统计量作为特征。基于多项式逻辑回归的线性分类器用于使用特征对文档进行分类。
- BOW和BOW + TFIDF 从训练集中选择了50,000个最常见的单词,并且每个单词的计数都被用作特征。顾名思义,Bow + TFIDF使用计数的TFIDF作为特征。
- n-gram和n-gram + TFIDF 最多使用500,000 n-gram(最多5克)。
- Bag-of-means 平均word2vec嵌入(Mikolov等人,2013)用作功能集。
在(Tang等人,2015)中报告了基于SVM的方法,包括SVM+Unigram,Bigrams,TextFeatures,AverageSG,SSWE。详细地说,
- Unigram和Bigrams分别使用bag-of-unigrams和bag-of-bigrams作为各自的特征。
- Text Features是根据(Kiritchenko等人,2014)构造的,包括单词和字符n-gram,情感词典特征等。
- AverageSG使用word2vec构造200维单词矢量,并使用每个文档的平均单词嵌入。
- SSWE根据(Tang 等人,2014)使用特定于情感的单词嵌入。
基于神经网络的方法在(Tang等人,2015)和(Zhang等人,2015)中报告。
-
CNN-word 使用基于单词的CNN模型,如(Kim,2014)的模型。
-
CNN-char字符级CNN模型被报告在(Zhang等人,2015)。
-
LSTM将整个文档作为一个序列,利用所有单词隐藏状态的平均值作为特征进行分类。
-
Conv GRNN和LSTM-GRNN由提出(Tang等人,2015)。他们还探索了层次结构:CNN或LSTM提供一个句子向量,然后门控递归神经网络(GRNN)结合来自文档级向量表示的句子向量进行分类。
我们将文档分成句子,并使用斯坦福大学的CoreNLP标记每个句子(Manning等人,2014)。在构建词汇表时,我们只保留出现5次以上的单词,并将出现5次的单词替换为一个特殊的UNK标记。我们通过在训练和验证分割上训练一个无监督的word2vec(Mikolov等人,2013)模型来获得词嵌入,然后使用单词嵌入来初始化W$_e$。
模型的超参数是在验证集上调整的。在我们的实验中,我们将词嵌入维度设为200,GRU维度设为50。 在这种情况下,前向和后向GRU的组合为单词/句子注释提供了100个维度。单词/句子上下文向量的维数也为100,随机初始化。
对于训练,我们使用64个为一小批,长度相似的文档(根据文档中的句子数)被组织为一批。我们发现长度调整可以使训练加速三倍。我们使用随机梯度下降来训练所有动量为0.9的模型。我们使用验证集上的网格搜索来选择最佳学习率。
所有数据集的实验结果如表2所示。我们称我们的模型为 HN-{AVE,MAX,ATT}。这里HN表示层次网络,AVE表示平均,MAX表示最大池,ATT表示我们提出的高层次注意模型。结果表明,在所有数据集上,HN-ATT的性能最好。
改进的程度与数据大小无关。对于较小的数据集,如Yelp2013和IMDB,我们的模型的性能分别比以前最好的基线方法好3.1%和4.1%。这个发现在其他较大的数据集中是一致的。在Yelp 2014、Yelp 2015、Yahoo Answers和Amazon。Reviews上,我们的模型比以前最好的模型分别高出3.2%、3.4%、4.6%和6.0%。无论任务类型如何,都会有改进:情绪分类,包括Yelp2013-2014、IMDB、亚马逊评论和雅虎问答的主题分类。
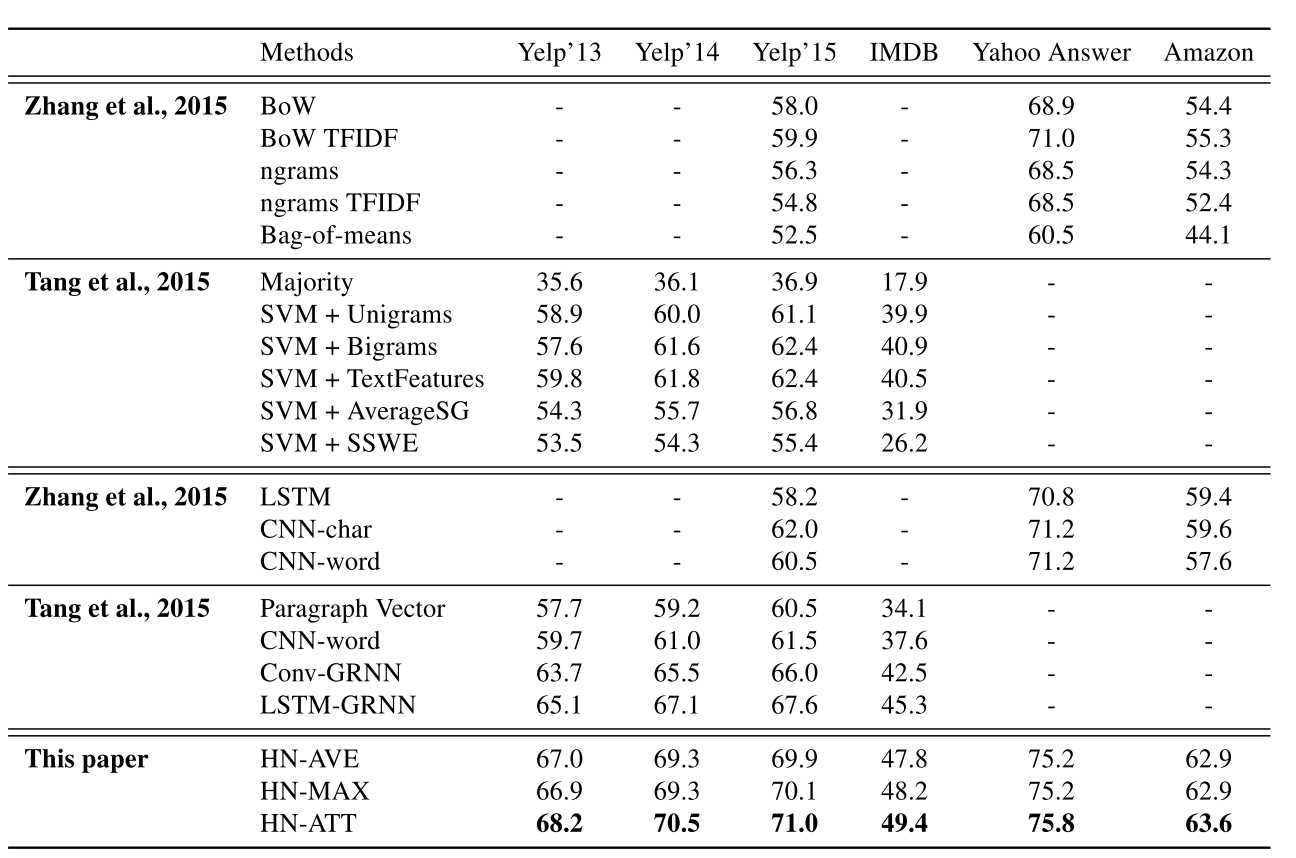
表2:文档分类,百分比
从表2我们可以看出,基于神经网络的方法,不探索层次文档结构,如LSTM,CNN word,CNN-char,在大规模文本分类(就文档大小而言)方面没有传统方法的优势。例如,SVM+TextFeatures分别为Yelp 2013、2014、2015和IMDB提供了59.8、61.8、62.4、40.5的性能,而CNN word的精度分别为59.7、61.0、61.5、37.6。
在HN-AVE,HN-MAX中,只探索层次结构可以显著地改善LSTM,CNN-word和CNN-char。例如,我们的HN-AVE在Yelp 2013、2014、2015和IMDB上分别比CNN word高7.3%、8.8%、8.5%和10.2%。进一步利用注意机制和层次结构相结合的HN-ATT模型比以前的模型(LSTM-GRNN)分别提高了3.1%、3.4%、3.5%和4.1%。更有趣的是,在实验中,HN-AVE等价于使用非信息性的全局单词/句子上下文向量(例如,如果它们都是零向量,则等式6和9中的注意权重变为均匀权重)。与HN-AVE相比,HN-ATT模型具有更高的性能。这清楚地证明了所提出的全局单词和句子重要性向量对HAN的有效性。
如果单词本质上有重要与否的区分,那么没有注意机制的模型可能工作得很好,因为模型可以自动为不相关的单词分配低权重,反之亦然。然而,单词的重要性与上下文高度相关。例如,good这个词可能出现在评分最低的评论中,要么是因为用户只对产品/服务的一部分感到满意,要么是因为他们用它来否定,比如not good。为了验证我们的模型能够捕获上下文相关的单词重要性,我们绘制了Yelp2013数据集的测试分割中单词的注意力权重的分布,如图3(a)和图4(a)所示。我们可以看到,分布有一个从0到1的单词的注意力权重。这表明我们的模型捕获了不同的上下文,并为单词分配了上下文相关的权重。
为了进一步说明这一点,我们根据评论的评分来绘制分布图。图3和图4中的子图3(b)-(f)分别对应于等级1-5。特别是,图3(b)显示,在评级为1的评审中,良好的权重集中在低端。随着评分的增加,权重分布也随之增加。 这意味着good这个词对于评价更高的评论起着更重要的作用。我们可以观察图4中单词bad的相反趋势。这证实了我们的模型能够捕获上下文相关的单词重要性。
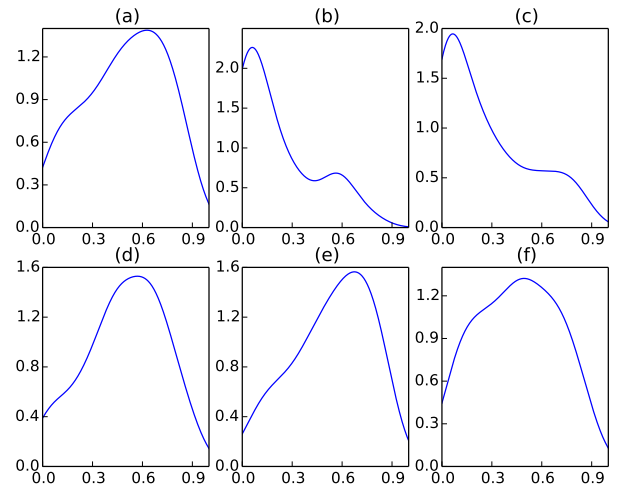
图三:good的注意力权重分布。 (a)——测试分片的总分布; (b)-(f)分别针对评分为1-5的评论进行了分层。 我们可以看到,随着评级的提高,权重分布向更高端转移。
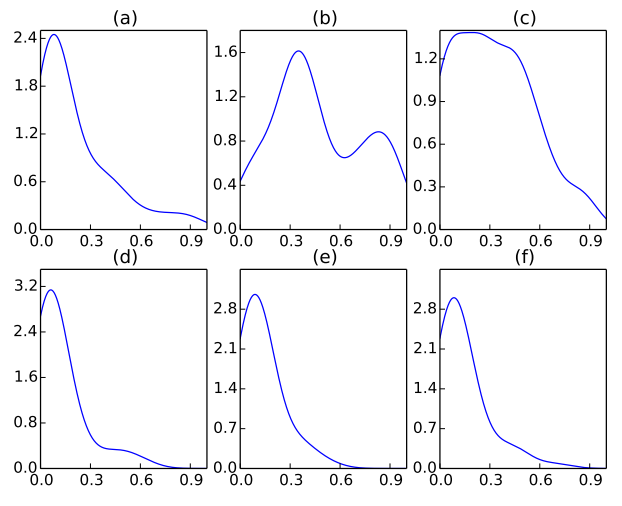
图4:单词“bad”的注意力分布。 设置如上所述:(a)包含汇总分布,而(b)-(f)包含分别对评分为1-5的评论的分层。 与以前相反,单词bad被认为对不良评级很重要,而对于良好评级则不那么重要。
为了验证我们的模型能够在文档中选择信息含义高的句子和单词,我们对Yelp 2013和Yahoo Answers数据集中的几个文档的图5和图6中的分层注意力层进行了可视化。
每一行都是一个句子(有时句子会因为长度而溢出几行)。红色表示句子的权重,蓝色表示单词的权重。由于层次结构的存在,我们通过句子权重来对单词权重进行规范化,以确保只强调重要句子中的重要单词。为了可视化,我们展示$
\sqrt{p_{S}} p_{w}
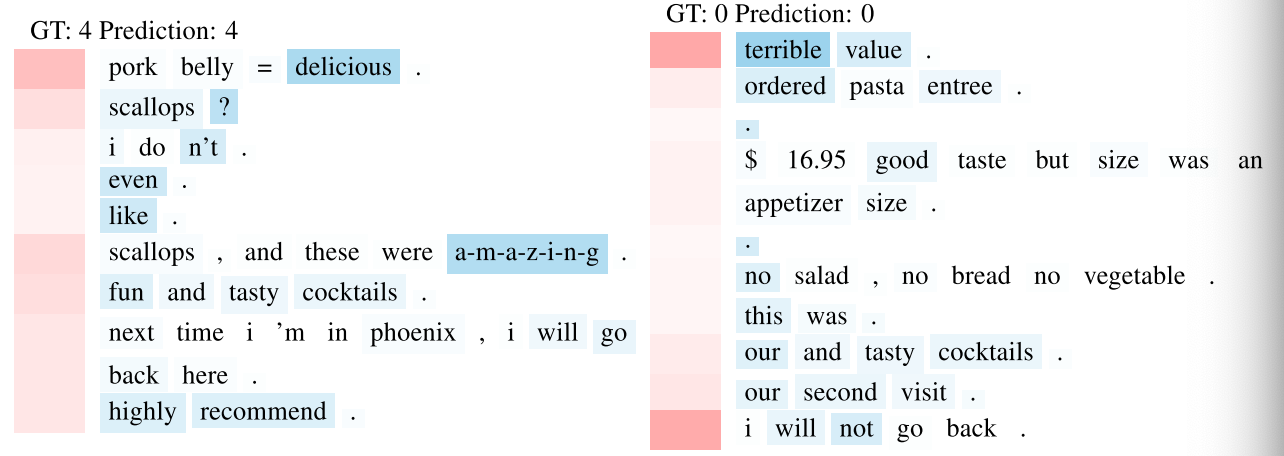
图5:来自Yelp 2013的文档。标签4表示5星,标签0表示1星。
图5显示,我们的模型可以选择带有强烈情感的单词,如美味、惊人、可怕以及它们对应的句子。含有许多单词的句子,如鸡尾酒,意大利面,主菜都是被忽视的。值得注意的是,我们的模型不仅可以选择带有强烈情感的词,还可以处理跨句子上下文的复杂情况。**例如,在图5的第一个文档中,有一些句子像“我甚至不喜欢扇贝”,如果仅仅看单个句子,我们可能会认为这是负面的评论。**然而,我们的模型从这个句子的上下文出发,发现这是一个积极的评价,并选择忽略这个句子。

图6:来自Yahoo Answers的文档。 标签1代表科学和数学,标签4代表计算机和互联网。
我们的分层注意机制也适用于Yahoo Answer数据集中的主题分类。例如,对于图6中标签为1的左侧文档(表示科学和数学),我们的模型精确地定位了单词斑马、条纹、伪装、捕食者及其对应的句子。对于带有标签4(表示计算机和因特网)的右侧文档,我们的模型主要关注网页、搜索、浏览器及其对应的句子。注意,这发生在多类集合中,也就是说,检测发生在主题选择之前!
Kim(2014)使用神经网络进行文本分类。尽管有NLP解释,该体系结构是CNNs在计算机视觉中的直接应用(LeCun等人,1998)。Johnson和Zhang(2014)探究了直接使用一个高维热向量作为输入的情况。他们发现它表现得很好。与单词级别的修改不同,Zhang等人(2015)采用字符级CNN进行文本分类,取得竞争性成果。Socher等人(2013)使用递归神经网络进行文本分类。Tai等人(2015)探索了句子结构,并使用树状结构的LSTM进行分类。还有一些工作将LSTM和CNN结构结合起来用于句子分类(Lai等人,2015;Zhou等人,2015)。Tang等人(2015)在情感分类上采用层次结构。他们首先使用CNN或LSTM得到句子向量,然后使用双向门控递归神经网络合成句子向量得到文档向量。还有一些其他工作在序列生成(Li 等人,2015)和语言建模(Lin 等人,2015)中使用了层次结构。
注意力机制由(Bah-danau等人,2014)在机器翻译中提出。采用了解码译码器框架,并采用注意力机制对外文翻译前的参考词进行选择。Xu等人(2015)在字幕中生成单词时,使用字幕生成中的注意力机制选择相关的图像区域。注意力机制的进一步使用包括解析(Vinyals等人,2014)、自然语言问答(Sukhbaatar等人,2015;Kumar等人,2015;Hermann等人,2015)和即时问答(Yang等人,2015)。与这些作品不同,我们探索了一种分层的注意机制(据我们所知,这是第一个这样的例子)。
本文提出了一种用于文档分类的层次注意网(HAN)。作为一种便利的意外效果,我们使用文档的高信息量组件获得了更好的可视化效果。我们的模型通过将重要的词聚合到句子向量,然后将重要的句子向量聚合到文档向量,逐步构建文档向量。实验结果表明,我们的模型明显优于以前的方法。这些注意层次的可视化说明我们的模型能够有效地识别出重要的单词和句子。