1. Residual Attention Network for Image Classification - yspaik/pytorch_study GitHub Wiki
- 논문 제목: Residual Attention Network for Image Classification
- 논문 링크: https://arxiv.org/abs/1704.06904
- 소스코드: https://github.com/fwang91/residual-attention-network
- Introduction
- 배경
- Attention 모델은 시계열 모델에 대해 잘 사용되고 있지만, 이미지 인식 등의 feedforward network에는 잘 사용되지 않음
- 최근 이미지 인식 기술 향상으로 ResNet을 이용하여 층을 깊게 할 수 있음
→ ResNet을 이용한
깊은CNN 대해 attention을 적용 하고 정밀도 향상을 도모
- 모델 구조와 성과
1. Stacked network structure
- 여러 Attention Module을 쌓아 만든 모델 구조. Attention Module은 다른 종류로도 연결될 수 있음
2. Attention Residual Learning
- 단순히 Attention Module을 연결하는 것만으로는 정확도가 떨어짐.
- Residual Network를 고려하여 hundreds of layers의 네트워크를 연결
3. Bottom-up top-down feedforward attention
-
Bottom-up (배경의 차이 등) attention 하는 방법
-
Top-down (사전 지식 등) attention 하는 방법
→ 안정 층을 늘리고 정확도 향상, End-to-End 깊은 네트워크에 쉽게 적용, 효율적인 계산

-
그림에서 주목할 점
- 다른 Attention Module에서는 다른 attention mask
- 층이 얕은 attention module에서는 배경의 빈 공간을 소거
- 층이 깊은 attention module에서는 풍선을 강조
-
Related Work
-
Residual Attention Network - 제안 모델
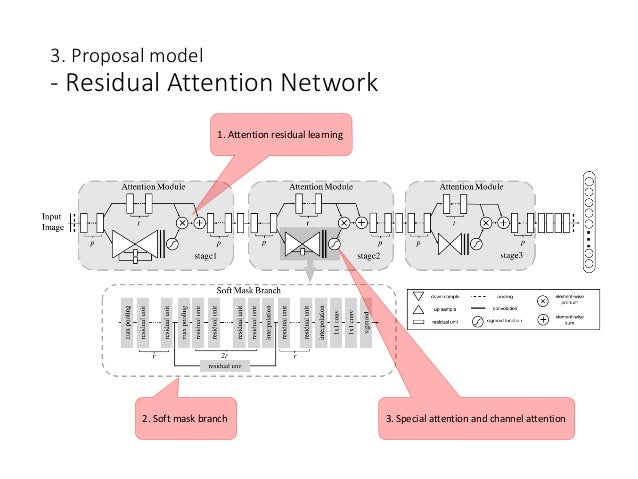
3.1. Attention Residual Learning
-
단순히 Attention Module을 CNN출력과 곱하기만 하면 정밀도가 떨어짐
- 층이 깊어 질수록 gradient decent가 사라짐
- CNN의 중요한 value of features를 약화 될 가능성
-
Attention Residual Learning 도식
-
Soft mask branch 𝑀 𝑥 ∈ [0, 1] 역할
- enhance good features
- trunk features로부터 noise deduction
-
Stacked Attention Modules가 장단점을 보완하여 feature map을 정교하게 다듬게 됨 → 풍선그림 Layer가 깊어질수록 정교해짐
-

3.2. Soft Mask Branch
- 두 가지 기능을 간직하는 구조
-
- Fast feed-forward sweep -> 이미지 전체의 정보를 파악
-
- Top-down feedback step -> 원래 feature map과 이미지 전체의 정보를 결합
-
- Sigmoid : normalize output range [0,1]
3.3 Spatial Attention and Channel Attention
- Activation function 변경 → Attention 제약을 추가 가능
-
- Mixed Attention → sigmoid
-
- Channel Attention → 모든 영역의 channlel에 대한 L2 normalization → spatial 정보 삭제
-
- Spatial Attention → 각 channel에서 feature map 안에서 정규화 → sigmoid를 통해서 spatial 정보만 관계된 mask 획득
-
