RNN(LSTM) with Attention による文章翻訳(日→英) - you1025/my_something_flagments GitHub Wiki
LSTM を用いて文章翻訳(日→英)を試してみる。
データは 参考書籍 を参考に small_parallel_enja から取得する。
データが格納されたリポジトリを clone する。
git clone https://github.com/odashi/small_parallel_enja.git登録単語をキーに単語 ID が格納され、日英ともにそれぞれ 4,096 アイテムが登録されている。
def make_id_word_converter(path):
id = 1
word2id = {}
id2word = {}
with open(path, "r") as f:
for line in f:
word = line.strip()
word2id[word] = id
id2word[id] = word
id += 1
return (word2id, id2word)ja_word2id, ja_id2word = make_id_word_converter("small_parallel_enja/train.ja.vocab.4k")
en_word2id, en_id2word = make_id_word_converter("small_parallel_enja/train.en.vocab.4k")
ja_word2id
#{1: '<unk>',
# 2: '<s>',
# 3: '</s>',
#︙
#}import numpy as np
def make_sentence_data(path, word2id):
WORD_UNKNOWN = "<unk>"
WORD_START = "<s>"
WORD_END = "</s>"
sentences = []
with open(path, "r") as f:
for line in f:
word_ids = [
word2id[word] if word in word2id else word2id[WORD_UNKNOWN]
for word
in line.strip().split(" ")
]
sentences.append(np.hstack([word2id[WORD_START], word_ids, word2id[WORD_END]]).tolist())
return sentencesja_train_data = make_sentence_data("small_parallel_enja/train.ja", ja_word2id)
en_train_data = make_sentence_data("small_parallel_enja/train.en", en_word2id)
ja_train_data
#[[2, 92, 14, 230, 7, 155, 29, 22, 18, 7, 5, 277, 38, 21, 41, 30, 4, 3],
# [2, 290, 10, 703, 14, 705, 7, 35, 20, 11, 1, 52, 54, 8, 4, 3],
# [2, 18, 5, 224, 1, 12, 19, 4, 3],
#︙
#]import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, from_sequences, to_sequences):
self.from_sequences = from_sequences
self.to_sequences = to_sequences
def __len__(self):
return len(self.from_sequences)
def __getitem__(self, index):
from_sequence = torch.tensor(self.from_sequences[index], dtype=torch.long)
to_sequence = torch.tensor(self.to_sequences[index], dtype=torch.long)
return (from_sequence, to_sequence)train_dataset = MyDataset(ja_train_data, en_train_data)
train_dataset[0]
#(tensor([ 2, 92, 14, 230, 7, 155, 29, 22, 18, 7, 5, 277, 38, 21, 41, 30, 4, 3]),
# tensor([ 2, 6, 42, 21, 151, 137, 30, 732, 234, 4, 3]))DataLoader の collate_fn に下記 my_collate_fn 関数を指定する事により、ミニバッチ全体で from_sequences, to_sequences 毎に 1 つの Tensor に変換しようとして発生するエラー(サンプル毎にサイズが異なる事による)を回避する。
def my_collate_fn(batch):
from_sequences, to_sequences = list(zip(*batch))
return (from_sequences, to_sequences)from torch.utils.data import DataLoader
BATCH_SIZE = 3
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=my_collate_fn)
ja_trains, en_trains = next(iter(train_loader))
# BATCH_SIZE(=3) 件のそれぞれサイズの異なるデータを取得
ja_trains
#(tensor([ 2, 122, 14, 183, 17, 71, 7, 5, 31, 166, 5, 119, 173, 17, 4, 3]),
# tensor([ 2, 18, 5, 851, 237, 6, 71, 9, 2225, 17, 4, 3]),
# tensor([ 2, 15, 33, 10, 254, 9, 78, 20, 11, 6, 17, 478, 12, 5, 13, 6, 4, 3]))
# BATCH_SIZE(=3) 件のそれぞれサイズの異なるデータを取得
en_trains
#(tensor([ 2, 6, 408, 226, 32, 912, 4, 3]),
# tensor([ 2, 16, 61, 5, 720, 345, 121, 25, 236, 4, 3]),
# tensor([ 2, 7, 101, 11, 105, 227, 443, 24, 305, 82, 456, 4, 3]))from torch.nn import Module, Sequential, Embedding, LSTM, Linear, Tanh, Dropout
from torch.nn.functional import softmax
class MyAttentionNMT(Module):
def __init__(self, ja_vocab_size, en_vocab_size, embedding_dim, num_layers=2, dropout=0):
super(MyAttentionNMT, self).__init__()
# 単語の分散表現
self.ja_embedding = Embedding(ja_vocab_size, embedding_dim)
self.en_embedding = Embedding(en_vocab_size, embedding_dim)
# LSTM
self.lstm_encoder = LSTM(embedding_dim, embedding_dim, num_layers=num_layers, dropout=dropout, batch_first=True)
self.lstm_decoder = LSTM(embedding_dim, embedding_dim, num_layers=num_layers, dropout=dropout, batch_first=True)
# Decoder 側の最上位層
# LSTM および Attention による特徴量を単語 ID の分布へ変換する
self.classifier = Sequential(
# Attention の適用により contexts の分(=embedding_dim)だけサイズが増える
Linear(2 * embedding_dim, embedding_dim),
Tanh(),
Dropout(p=0.5),
Linear(embedding_dim, en_vocab_size)
)
def forward(self, ja_sentence, en_sentence):
# Encoder
ja_embedded = self.ja_embedding(ja_sentence)
ja_hs, (ja_h, ja_c) = self.lstm_encoder(ja_embedded)
# Decoder
en_embedded = self.en_embedding(en_sentence)
en_hs, (en_h, en_c) = self.lstm_decoder(en_embedded, (ja_h, ja_c))
# Attention
context = self.calc_contexts(ja_hs, en_hs)
hs_concatenated = torch.cat([context, en_hs], dim=2)
y = self.classifier(hs_concatenated)
return y
# 推論処理
def inference(self, input_sequence, start_id, end_id):
# Encoder
ja_embedded = self.ja_embedding(ja_input)
ja_hs, (h, c) = self.lstm_encoder(ja_embedded)
pred_sequence = []
predicted_id = start_id
for _ in range(30):
predicted_ids = torch.tensor([[ predicted_id ]], dtype=torch.long).to(device)
# Decoder
en_embedded = net.en_embedding(predicted_ids)
en_hs, (h, c) = net.lstm_decoder(en_embedded, (h, c))
# Attention
context = net.calc_contexts(ja_hs, en_hs)
hs_concatenated = torch.cat([context, en_hs], dim=2)
y = net.classifier(hs_concatenated)
# ID の特定
predicted_id = torch.argmax(y[0, 0]).item()
pred_sequence.append(predicted_id)
# 推定された ID が終了文字の場合は処理を抜ける
if predicted_id == end_id:
break
return pred_sequence
# Attention による context データ生成処理
def calc_contexts(self, hs_encoder, hs_decoder):
score = torch.bmm(hs_encoder, hs_decoder.permute(0, 2, 1))
alpha = softmax(score, dim=1)
context = torch.bmm(alpha.permute(0, 2, 1), hs_encoder)
return contextMyAttentionNMT(
# サイズはパディング用に +1 した値を指定する
ja_vocab_size=len(ja_id2word)+1,
en_vocab_size=len(en_id2word)+1,
dropout=0.5,
embedding_dim=200
)
#MyAttentionNMT(
# (ja_embedding): Embedding(4097, 200)
# (en_embedding): Embedding(4097, 200)
# (lstm_encoder): LSTM(200, 200, num_layers=2, batch_first=True, dropout=0.5)
# (lstm_decoder): LSTM(200, 200, num_layers=2, batch_first=True, dropout=0.5)
# (classifier): Sequential(
# (0): Linear(in_features=400, out_features=200, bias=True)
# (1): Tanh()
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=200, out_features=4097, bias=True)
# )
#)集計単位ごとに関数を用意しておく
def calc_minibatch_loss(outputs, labels, criterion):
# データ全体のロスの総和を算出
loss = None
for output, label in zip(outputs, labels):
if loss is None:
loss = criterion(output, label)
else:
loss += criterion(output, label)
return lossDataLoader 全体でのロスのサンプル平均を算出する
import torch
def calc_avg_loss(model, criterion, data_loader, device):
total_loss = 0.0
total_count = 0
net.eval()
with torch.no_grad():
for ja_sequences, en_sequences in data_loader:
ja_inputs = [ sequence[1:] for sequence in ja_sequences ]
en_inputs = [ sequence[:-1] for sequence in en_sequences ]
answers = [ sequence[1:] for sequence in en_sequences ]
ja_inputs = pad_sequence(ja_inputs, batch_first=True).to(device)
en_inputs = pad_sequence(en_inputs, batch_first=True).to(device)
answers = pad_sequence(answers, batch_first=True, padding_value=-1).to(device)
outputs = net(ja_inputs, en_inputs)
# ミニバッチにおけるロスの総和を算出
loss = calc_minibatch_loss(outputs, answers, criterion)
total_loss += loss.item()
total_count += outputs.size(dim=0)
avg_loss = total_loss / total_count
return avg_lossエポック毎に算出した 学習/テスト それぞれのロスを csv として出力する
import csv
def save_losses(csv_path, scores):
header = scores.keys()
rows = [
[epoch, train_loss, test_loss]
for (epoch, train_loss, test_loss)
in zip(
scores["epoch"],
scores["train_loss"],
scores["test_loss"]
)
]
with open(csv_path, "a") as f:
writer = csv.writer(f)
writer.writerow(header)
writer.writerows(rows)from torch.utils.data import DataLoader
from torch.nn import CrossEntropyLoss
from torch.optim import AdamW
from torch.optim.lr_scheduler import MultiStepLR
from torch.nn.utils.rnn import pad_sequence
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 変換辞書の作成
ja_word2id, ja_id2word = make_id_word_converter("small_parallel_enja/train.ja.vocab.4k")
en_word2id, en_id2word = make_id_word_converter("small_parallel_enja/train.en.vocab.4k")
# DataLoader の作成
BATCH_SIZE = 32
# train
ja_train_data = make_sentence_data("small_parallel_enja/train.ja", ja_word2id)
en_train_data = make_sentence_data("small_parallel_enja/train.en", en_word2id)
train_dataset = MyDataset(ja_train_data, en_train_data)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=my_collate_fn)
# test
ja_test_data = make_sentence_data("small_parallel_enja/test.ja", ja_word2id)
en_test_data = make_sentence_data("small_parallel_enja/test.en", en_word2id)
test_dataset = MyDataset(ja_test_data, en_test_data)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, collate_fn=my_collate_fn)
# モデル
net = MyAttentionNMT(len(ja_word2id)+1, len(en_word2id)+1, 200, dropout=0.5)
# 損失関数
# 教師データをパディングする際(pad_sequence)の padding_value=-1 に対応
criterion = CrossEntropyLoss(ignore_index=-1)
# Optimizer
optimizer = AdamW(net.parameters(), weight_decay=0.05)
# 25, 40 エポック目で学習率を 0.1 倍する
scheduler = MultiStepLR(optimizer, milestones=[25, 40], gamma=0.1)
net.to(device)
num_epochs = 50
avg_test_losses = []
scores = {
"epoch": [],
"train_loss": [],
"test_loss": []
}
for epoch in range(num_epochs):
iteration = 0
avg_losses = []
net.train()
for ja_sequences, en_sequences in train_loader:
ja_inputs = [ sequence[1:] for sequence in ja_sequences ]
en_inputs = [ sequence[:-1] for sequence in en_sequences ]
answers = [ sequence[1:] for sequence in en_sequences ]
# パディング処理
# answers に指定している padding_value=-1 は criterion(CrossEntropyLoss) の ignore_index=-1 に対応
ja_inputs = pad_sequence(ja_inputs, batch_first=True).to(device)
en_inputs = pad_sequence(en_inputs, batch_first=True).to(device)
answers = pad_sequence(answers, batch_first=True, padding_value=-1).to(device)
outputs = net(ja_inputs, en_inputs)
# ミニバッチにおけるロスの総和を算出
loss = calc_minibatch_loss(outputs, answers, criterion)
# 平均ロスを算出
avg_loss = loss.item() / outputs.size(dim=0)
avg_losses.append(avg_loss)
# 一定イテレーション毎にログを表示
if (iteration+1) % 100 == 0:
avg_avg_loss = np.mean(avg_losses)
print(f"epoch: {(epoch+1):2d}, iteration: {(iteration+1):4d}, loss: {avg_avg_loss:.3f}")
avg_losses = []
optimizer.zero_grad()
loss.backward()
optimizer.step()
iteration += 1
scheduler.step()
# エポック毎に 訓練/テスト 誤差を算出
avg_train_loss = calc_avg_loss(net, criterion, train_loader, device)
avg_test_loss = calc_avg_loss(net, criterion, test_loader, device)
print(f"epoch: {(epoch+1):2d}, avg_train_loss: {avg_train_loss:.3f}, avg_test_loss: {avg_test_loss:.3f}")
scores["epoch"].append(epoch+1)
scores["train_loss"].append(avg_train_loss)
scores["test_loss"].append(avg_test_loss)
# ロスを csv へ出力
save_losses("losses.csv", scores)
# モデルの保存
torch.save(net.state_dict(), f"nmt_minibatch_with_attention_{epoch+1}.pth")import pandas as pd
import matplotlib.pyplot as plt
_, ax = plt.subplots(figsize=(10, 5))
pd.DataFrame(scores).set_index("epoch").plot(marker="o", ax=ax)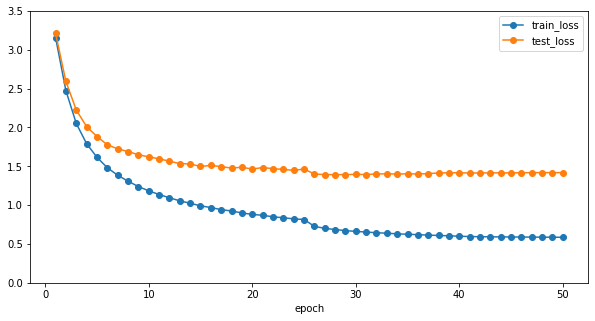
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 変換辞書の作成
ja_word2id, ja_id2word = make_id_word_converter("small_parallel_enja/train.ja.vocab.4k")
en_word2id, en_id2word = make_id_word_converter("small_parallel_enja/train.en.vocab.4k")
# テストデータ
ja_test_data = make_sentence_data("small_parallel_enja/test.ja", ja_word2id)
en_test_data = make_sentence_data("small_parallel_enja/test.en", en_word2id)
# モデルの作成
# 学習済みのパラメータを適用
net = MyAttentionNMT(len(ja_word2id)+1, len(en_word2id)+1, 200).to(device)
state_dict = torch.load("nmt_minibatch_with_attention_50.pth", map_location=torch.device(device))
net.load_state_dict(state_dict)
en_start_id = en_word2id["<s>"]
en_end_id = en_word2id["</s>"]
net.eval()
with torch.no_grad():
for ja_sequence, en_sequence in zip(ja_test_data, en_test_data):
# 変換対象と教師文
print("JPN:", " ".join([ ja_id2word[id] for id in ja_sequence[1:-1] ]))
print("ENG:", " ".join([ en_id2word[id] for id in en_sequence[1:-1] ]))
# 推論
ja_input = torch.tensor([ja_sequence[1:]], dtype=torch.long).to(device)
pred_sequence = net.inference(ja_input, en_start_id, en_end_id)
print("PRD:", " ".join([ en_id2word[id] for id in pred_sequence[:-1] ]))
print()それなりに良い感じの訳文が生成されている模様
JPN: 彼 ら は つい に それ が 真実 だ と 認め た 。
ENG: they finally acknowledged it as true .
PRD: they finally acknowledged it .
JPN: 彼 は 水泳 が 得意 で は な かっ た 。
ENG: he didn 't care for swimming .
PRD: he was not good at swimming .
JPN: 彼 は お 姉 さん に 劣 ら ず 親切 だ 。
ENG: he is no less kind than his sister .
PRD: he is not as kind as to have his sister .
JPN: 10 時 前 に 戻 ら な けれ ば な ら な い 。
ENG: you must be back before ten .
PRD: you must return to ten o 'clock .
JPN: 成功 を 祈 る わ 。
ENG: break a leg .
PRD: i hope the success of success .
︙