算法图解 - yiyixiaozhi/readingNotes GitHub Wiki
date: 2018-1-11 20:02:13 description: 作者:Aditya Bharagava 译者:袁国忠 算法是一组完成任务的指令。本书介绍的算法要么速度快,要么能解决有趣的问题,要么兼而有之。
该使用合并排序算法还是快速排序算法,或者该使用数组还是链表。仅仅改用不同的数据结构就可能让结果大不相同。
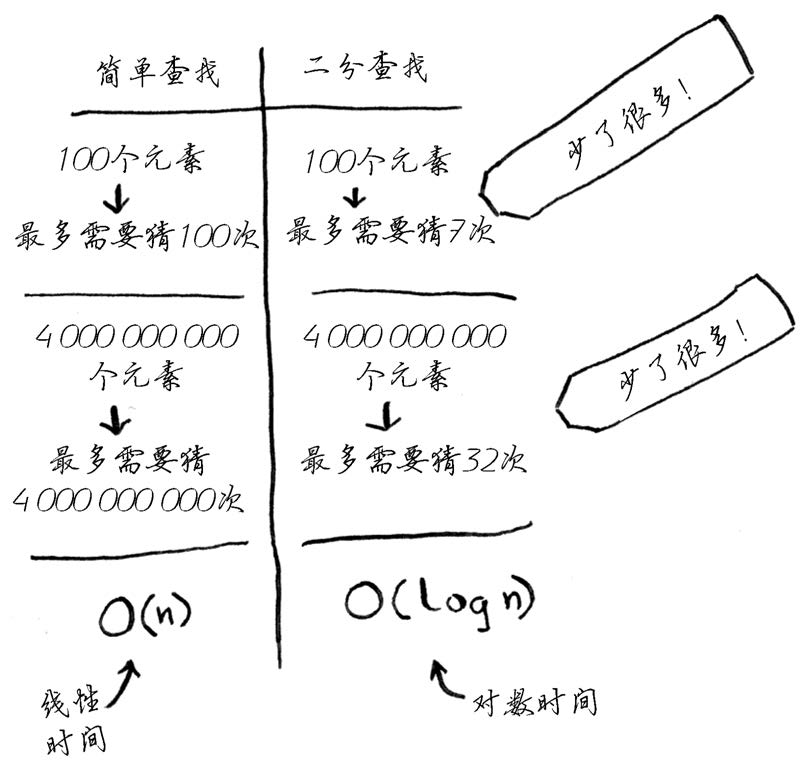
使用二分查找时,你猜测的是中间的数字,从而每次都将余下的数字排除一半。

一般而言,对于包含n个元素的列表,用二分查找最多需要
接下来,我们用
来表示
。
仅当列表是有序的时候,二分查找才管用。例如,电话簿中的名字是按字母顺序排列的,因此可以使用二分查找来查找名字。
知道算法需要多长时间才能运行完毕还不够,还需知道运行时间如何随列表增长而增加。这正是大O表示法的用武之地。
大O 表示法指出了最糟情况下的运行时间。
一些常见的大O 运行时间:
-
,也叫对数时间,这样的算法包括二分查找。
-
,也叫线性时间,这样的算法包括简单查找。
-
,这样的算法包括第4章将介绍的快速排序——一种速度较快的排序算法。
-
,这样的算法包括第2章将介绍的选择排序——一种速度较慢的排序算法。
-
,这样的算法包括接下来将介绍的旅行商问题的解决方案——一种非常慢的算法。
算法的速度指的并非时间,而是操作数的增速。
总结:
-
二分查找的速度比简单查找快得多。
-
-
算法运行时间并不以秒为单位。
-
算法运行时间是从其增速的角度度量的。
-
算法运行时间用大O表示法表示。

有一位旅行商。他需要前往5个城市。这位旅行商(姑且称之为Opus吧)要前往这5个城市,同时要确保旅程最短。为此,可考虑前往这些城市的各种可能顺序。

对于每种顺序,他都计算总旅程,再挑选出旅程最短的路线。5个城市有120种不同的排列方式。因此,在涉及5个城市时,解决这个问题需要执行120次操作。涉及6个城市时,需要执行720次操作(有720种不同的排列方式)。涉及7个城市时,需要执行5040次操作!

推而广之,涉及n个城市时,需要执行
这种算法很糟糕!Opus应使用别的算法,可他别无选择。这是计算机科学领域待解的问题之一。对于这个问题,目前还没有找到更快的算法,有些很聪明的人认为这个问题根本就没有更巧妙的算法。面对这个问题,我们能做的只是去找出近似答案。
本章内容: 学习两种最基本的数据结构——数组和链表。 学习第一种排序算法。本章将介绍选择排序。
需要将数据存储到内存时,你请求计算机提供存储空间,计算机给你一个存储地址。需要存储多项数据时,有两种基本方式——数组和链表。
链表的优势在插入元素方面。数组的优势在于读取元素方面。

数组和链表哪个用得更多呢?显然要看情况。但数组用得很多,因为它支持随机访问。
你要将这个列表按播放次数从多到少的顺序排列,从而将你喜欢的乐队排序。该如何做呢?一种办法是遍历这个列表,找出作品播放次数最多的乐队,并将该乐队添加到一个新列表中。 要找出播放次数最多的乐队,必须检查列表中的每个元素。正如你刚才看到的,这需要的时间为O(n)。因此对于这种时间为O(n)的操作,你需要执行n次。

需要的总时间为
选择排序是一种灵巧的算法,但其速度不是很快。快速排序是一种更快的排序算法,其运行时间为O(n log n),这将在下一章介绍。
-
计算机内存犹如一大堆抽屉。
-
需要存储多个元素时,可使用数组或链表。
-
数组的元素都在一起。
-
链表的元素是分开的,其中每个元素都存储了下一个元素的地址。
-
数组的读取速度很快。
-
链表的插入和删除速度很快。
-
在同一个数组中,所有元素的类型都必须相同(都为int、double等)。
# Finds the smallest value in an array
def findSmallest(arr):
# Stores the smallest value
smallest = arr[0]
# Stores the index of the smallest value
smallest_index = 0
for i in range(1, len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index
# Sort array
def selectionSort(arr):
newArr = []
for i in range(len(arr)):
# Finds the smallest element in the array and adds it to the new array
smallest = findSmallest(arr)
newArr.append(arr.pop(smallest))
return newArr
print selectionSort([5, 3, 6, 2, 10])
本章内容:
-
学习递归。递归是很多算法都使用的一种编程方法,是理解本书后续内容的关键。
-
学习如何将问题分成基线条件和递归条件。第4章将介绍的分而治之策略使用这种简单的 概念来解决棘手的问题。
递归是我最喜欢的主题之一,它将人分成三个截然不同的阵营:恨它的、爱它的以及恨了几年后又爱上它的。 本章还包含大量伪代码。伪代码是对手头问题的简要描述,看着像代码,但其实更接近自然语言。
每个递归函数都有两部分:基线条件(base case)和递归条件(recursive case)。递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。
调用栈(call stack)。调用栈不仅对编程来说很重要,使用递归时也必须理解这个概念。