深度学习自定义组件用法 - xuelang-group/suanpan-docs GitHub Wiki
深度学习自定义组件用法
使用自定义组件,您可以通过加载自定义的Python脚本,通过复用您现有的代码,完成更灵活的模型搭建和训练。
Keras自定义层
一些新型网络层还未被收录到Keras 深度学习库,我们以GroupNormalization为例,演示如何将其加入到模型中。
如果您想了解更多如何定义自定义层的信息,可以参考Keras官方文档,但需注意所有自定义代码中import keras时候请用import tensorflow.keras,因为所有Keras深度学习组件底层使用的是TensorFlow 版本的Keras库。
当您拖出一个Keras自定义层时候可以在其右面板“概览”中修改其名称。
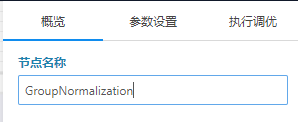
然后在参数设置列配置其他信息,
customObject:GroupNormalization层的源码,即GroupNormalization class定义和相关的import,有关 Group Normalization 的源码可以参考这个GitHub 链接。
layerConfig:GroupNormalization class初始化函数带的参数和实例化网络层的名称(name)。
classString:“GroupNormalization”即自定义层class的名称。
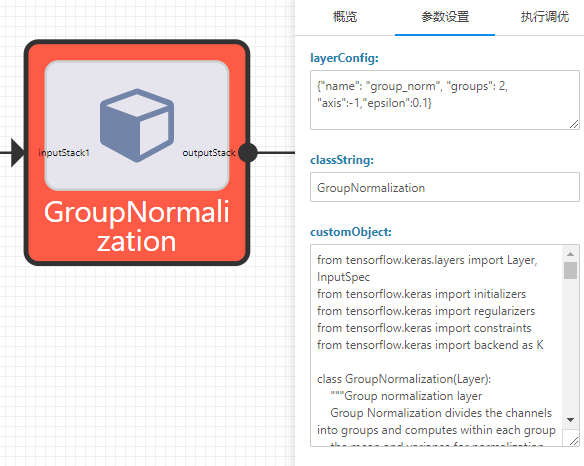
自定义层GroupNormalization
Keras自定义代码
自定义代码,对输入tensor操作,输出tensor。
以下我们以引用预训练的MobileNetV2为例演示如何使用自定义代码组件。
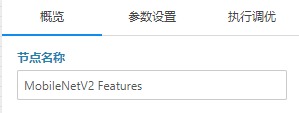
当您拖出一个Keras自定义代码时候可以在其右面板“概览”中修改其名称。
在 “customCode”中填写自定义代码,实例中人口函数名称为“custom_code”,与在functionString定义的名称对应。
人口函数的第一个参数“input_tensor”为必选参数,其他参数为用户自定义参数。
人口函数的自定义参数通过“functionArgs”传入。
根据输入端子连接数量不同,人口函数第一个参数“input_tensor”可以为单个tensor或一列tensors,在人口函数中将对这个变量做操作,并返回一个tensor作为节点输出。
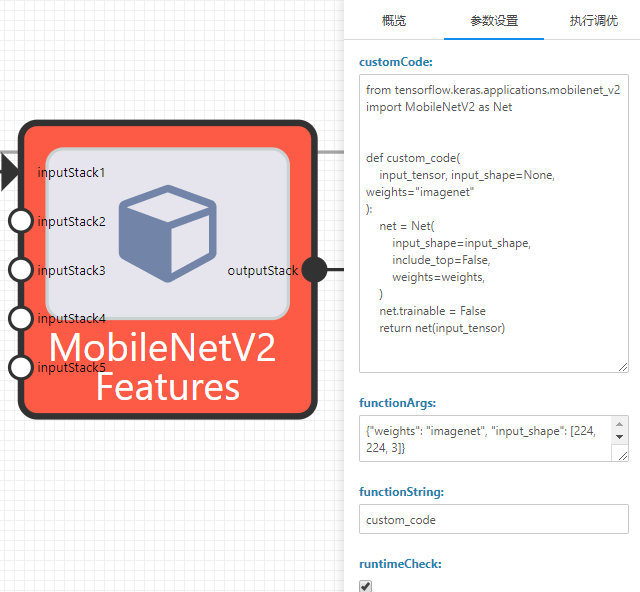
Keras自定义代码
Keras自定义模型训练
Keras自定义模型训练中你可以向如下方式调用model.fit函数,利用输入的Numpy数据训练模型,你可以在训练前冻结/解冻部分网络层实现例如迁移学习/模型微调的高级操作。

Keras自定义模型训练
Keras模型自定义训练文件夹数据
类似Keras自定义模型训练,区别是输入的训练数据为文件,比如图片文件/或压缩的文件夹。
learnerCode中定义的代码可以使用下列3个变量。
• data [字符串] -- 数据集文件夹的路径,即dataFolder输入端子上传的数据。
• model_weights [字符串] -- 如果提供,则路径到预先训练的模型权重 HDF5 文件,即h5Model输入端子输入的文件,可以为空(None)。如果其不为空,您可以用代码model.load_weights(model_weights)方式加载。
• model [Keras模型] -- 输出模型。

Keras模型自定义训练文件夹数据
下列为完整的learnerCode内容案例,您可以适当修改以完成不同的操作。
# data {str} -- Path to the dataset folder.
# model_weights {str} -- Path to the pre-trained model weight HDF5 file if provided.
# model {Model} -- your output model
import zipfile
import os
import tempfile
print("data:", data)
folder_items = os.listdir(data)
print("model_weights: ", model_weights)
# Locate a zip file first.
zip_fnames = [
item for item in folder_items if "zip" in os.path.splitext(item)[1].lower()
]
if len(zip_fnames) > 0:
zip_file = os.path.join(data, zip_fnames[0])
extract_dir = tempfile.mkdtemp()
print("extracting zip.")
with zipfile.ZipFile(zip_file, "r") as zip_ref:
zip_ref.extractall(extract_dir)
data = extract_dir
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import optimizers
# Hyper parameters.
batch_size = 20
height = 224
width = 224
epochs = 2
lr = 2e-5
steps_per_epoch = 100
validation_steps = 50
def get_dirs(base_dir):
"""Get the train, test ,validation data folder paths.
Arguments:
base_dir {str} -- node input data folder path.
Raises:
ValueError: Expect one input folder.
Returns:
list -- a list of 3 elements, train, test ,
validation data folder paths, or Nones
"""
outputs = []
folders = os.listdir(data)
folders = [folder.replace("_$folder$", "") for folder in folders]
folders = list(set(folders))
if len(folders) != 1:
raise ValueError("Expect one input folder, but got: {}".format(folders))
else:
data_dir = os.path.join(base_dir, folders[0])
dir_names = ["train", "test", "validation"]
for dir_name in dir_names:
dir_path = os.path.join(data_dir, dir_name)
if os.path.isdir(dir_path):
outputs.append(dir_path)
else:
outputs.append(None)
return outputs
train_dir, test_dir, validation_dir = get_dirs(data)
print("dataset split folders:", train_dir, test_dir, validation_dir)
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode="nearest",
)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1.0 / 255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized.
target_size=(height, width),
batch_size=batch_size,
# Since we use binary_crossentropy loss, we need binary labels
class_mode="categorical",
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(height, width),
batch_size=batch_size,
class_mode="categorical",
)
model.compile(
loss="categorical_crossentropy",
optimizer=optimizers.RMSprop(lr=lr),
metrics=["acc"],
)
history = model.fit_generator(
train_generator,
steps_per_epoch=steps_per_epoch,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_steps,
verbose=1,
)