NLU算法实现简介 - wyz1989/ailbaba GitHub Wiki
简介
NLU(natural language understanding)-自然语言理解模块, 改模块主要负责:领域分类、意图识别和词槽抽取, 为智能对话系统的核心模块。本文主要介绍xx公司智能对话系统NLU算法实现。本文主要从算法总体进行把握,具体细节不进行深纠。
算法流程
xx公司对话系统NLU算法主要分为离线和在线两部分。离线部分主要完成分类模型训练、模板生成等工作;在线部分完成NLU模块领域分类、意图识别和词槽抽取任务。可以看出离线部分工作均是为了在线服务的。算法整体实现如下图所示:
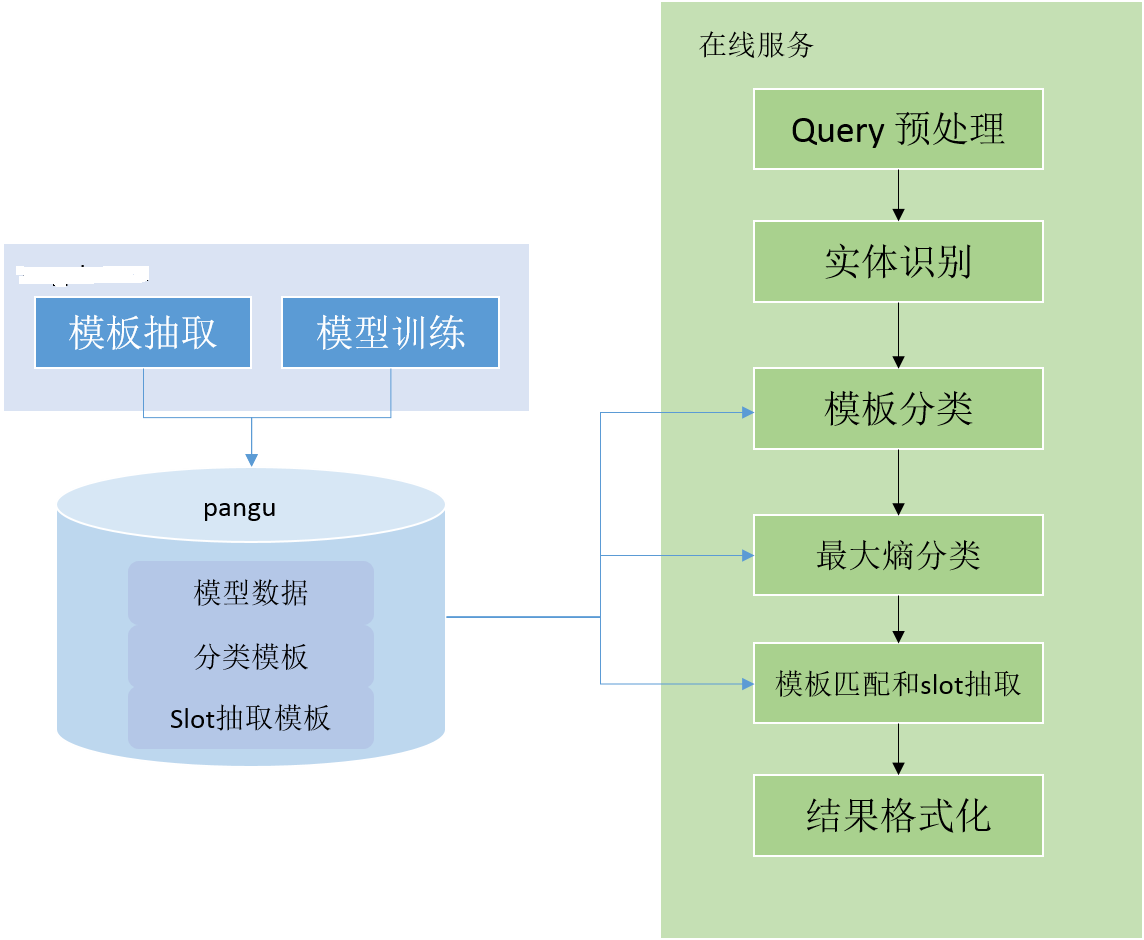
在线部分
- query预处理
对query进行预处理操作, 主要报告切词、纠错等
- 实体识别
利用CRF算法进行实体识别
- 领域分类
该模块完成将输入的query分到特定的领域(如:天气、NBA、日历等),算法主要通过两种方式进行领域分类:
- 基于模板匹配
- 基于最大熵模型
- 最大熵模型分类
最大熵模型选取的特征主要包括:词特定、bigram特征和实体特征。 如对于query:"我想听刘德华的哥", 生成的特征有:
- 词级别的特征:我 想 听 刘德华 的 歌
- Bigram特征:我_想 想_听 听_刘德华 刘德华_的 的_歌
- 实体特征:听_per per_的 听_singer singer_的 song_听
- 模板匹配和slot抽取
通过领域模板对意图进行识别和slot(词槽)抽取, 如下图所示为: calendar(日历领域)模板的格式,

离线部分
离线部分由离线计算平台完成, 主要工作包括:分类模型训练、pattern模板抽取工作。
- 模型训练
模型训练:最大熵分类模型训练, 离线流程如下图所示:
- CC根据前端用户发布的训练需求产生相应Task消息写入Swift;
- reader插件读取swift消息,生成相应record发往下游模块;
- feature_processor主要功能是根据用户提供的语料生成特征,并填充record中相应字段发往下游模块;
- feature_optimizer主要功能是对特征进行筛选,更新record中字段并发往下游;
- model_traing插件的主要功能根据特征生成模型;
- finalizer主要功能是将模型数据写入盘古,并通知cc和apphub-server;
- checkpoint插件主要功能是更新swift的消息读取进度点,避免swift中的消息的重复读取。

- 模板抽取
模板抽取流程如下图所示:
