Home - wom-ai/inference_results_v0.5 GitHub Wiki
MLPerf5.0
https://github.com/mlperf/inference_results_v0.5
MLPerf5.0 for NVIDIA
-
https://github.com/mlperf/inference_results_v0.5/tree/master/closed/NVIDIA
-
Specification
-
DEVELOPER BLOG: MLPerf Inference: NVIDIA Innovations Bring Leading Performance
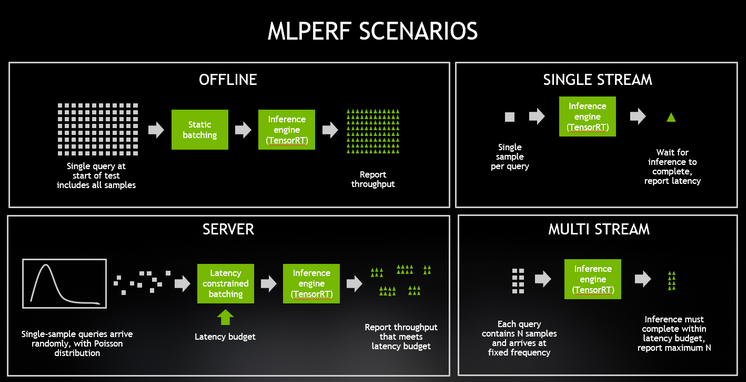
References
-
devblog article about MLPerf 5.0 and TensorRT (Link)
- SSD-MobileNetV1 300x300
Single Stream Multi Stream SSD MobileNet-v1 665 fps 102 fps SSD ResNet-34 34 2 -
devblog article about MLPerf 5.0 and TensorRT and SSD-MobileNetV2 (Link)
About 2500fps
Jetson Xavier NX achieves up to 15X higher performance than Jetson TX2, with the same power and in a 25% smaller footprint. During these benchmarks, each platform was run with maximum performance (MAX-N mode for Jetson AGX Xavier, 15W for Xavier NX and TX2, and 10W for Nano). The maximum throughput was obtained with batch sizes not exceeding a latency threshold of 16ms, otherwise a batch size of one was used for networks where the platform exceeded this latency threshold. This methodology provides a balance between deterministic low-latency requirements for realtime applications and also maximum performance for multi-stream use-case scenarios. On Jetson Xavier NX and Jetson AGX Xavier, both NVDLA engines and the GPU were run simultaneously with INT8 precision, while on Jetson Nano and Jetson TX2 the GPU was run with FP16 precision. The Volta architecture GPU with Tensor Cores in Jetson Xavier NX is capable of up to 12.3 TOPS of compute, while the module’s DLA engines produce up to 4.5 TOPS each.
Comparisions between int8_chw4 and fp32
GeforceRTX2080Ti + ssd-small (SSDMobileNet) + SingleStream
| inference time | Accuracy | |
|---|---|---|
| int8_chw4 | 0.65 - 0.75ms | |
| fp32 | 1.6 ms |
Trouble Shootings
Preprocess
python3 scripts/preprocess_data.py --data_dir="$$DATA_DIR" --output_dir="$$PREPROCESSED_DATA_DIR" --benchmark=ssd-small
libcublas10 initialization failed
- solution: downgrade libcublas-dev, libcublas10 == 10.1.x from 10.2.x
# apt-get install libcublas-dev=10.1.0.105-1
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages will be DOWNGRADED:
libcublas-dev
0 upgraded, 0 newly installed, 1 downgraded, 0 to remove and 256 not upgraded.
Need to get 39.9 MB of archives.
After this operation, 1112 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
Get:1 http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64 libcublas-dev 10.1.0.105-1 [39.9 MB]
Fetched 39.9 MB in 1s (39.1 MB/s)
debconf: unable to initialize frontend: Dialog
debconf: (No usable dialog-like program is installed, so the dialog based frontend cannot be used. at /usr/share/perl5/Debconf/FrontEnd/Dialog.pm line 76, <> line 1.)
debconf: falling back to frontend: Readline
dpkg: warning: downgrading libcublas-dev from 10.2.2.89-1 to 10.1.0.105-1
(Reading database ... 23030 files and directories currently installed.)
Preparing to unpack .../libcublas-dev_10.1.0.105-1_amd64.deb ...
Unpacking libcublas-dev (10.1.0.105-1) over (10.2.2.89-1) ...
Setting up libcublas-dev (10.1.0.105-1) ...
# apt-get install libcublas10=10.1.0.105-1
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following package was automatically installed and is no longer required:
cuda-license-10-2
Use 'apt autoremove' to remove it.
The following packages will be DOWNGRADED:
libcublas10
0 upgraded, 0 newly installed, 1 downgraded, 0 to remove and 257 not upgraded.
Need to get 42.4 MB of archives.
After this operation, 17.6 MB of additional disk space will be used.
Do you want to continue? [Y/n] y
Get:1 http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64 libcublas10 10.1.0.105-1 [42.4 MB]
Fetched 42.4 MB in 1s (34.1 MB/s)
debconf: unable to initialize frontend: Dialog
debconf: (No usable dialog-like program is installed, so the dialog based frontend cannot be used. at /usr/share/perl5/Debconf/FrontEnd/Dialog.pm line 76, <> line 1.)
debconf: falling back to frontend: Readline
dpkg: warning: downgrading libcublas10 from 10.2.2.89-1 to 10.1.0.105-1
(Reading database ... 23030 files and directories currently installed.)
Preparing to unpack .../libcublas10_10.1.0.105-1_amd64.deb ...
Unpacking libcublas10 (10.1.0.105-1) over (10.2.2.89-1) ...
Setting up libcublas10 (10.1.0.105-1) ...
Processing triggers for libc-bin (2.29-0ubuntu2) ...
FP32 inference for ssd-small
//set config for fp32
cd measurements/GeforceRTX2080Ti/ssd-small
rm ./Offline
ln -s ./Offline_fp32 Offline
rm ./SingleStream
ln -s ./SingleStream_fp32 SingleStream
//generete new engine for fp32
make generate_engines RUN_ARGS="--benchmarks=ssd-small --scenarios=SingleStream"
Platforms
-
Cuda compute capability Table
-
deviceQuerycommand$ apt install cuda-samples-XX-X $ cd /usr/local/cuda/samples $ make $ ./bin/x86_64/linux/release/deviceQuery -
Persistence Mode
Geforce RTX 2080 Ti
# deviceQuery
deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce RTX 2080 Ti"
CUDA Driver Version / Runtime Version 10.1 / 9.0
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 10989 MBytes (11523260416 bytes)
MapSMtoCores for SM 7.5 is undefined. Default to use 64 Cores/SM
MapSMtoCores for SM 7.5 is undefined. Default to use 64 Cores/SM
(68) Multiprocessors, ( 64) CUDA Cores/MP: 4352 CUDA Cores
GPU Max Clock rate: 1545 MHz (1.54 GHz)
Memory Clock rate: 7000 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 5767168 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 2 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 9.0, NumDevs = 1
Result = PASS
Geforce GTX 1080 Ti
# deviceQuery
deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1080 Ti"
CUDA Driver Version / Runtime Version 10.1 / 9.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 11177 MBytes (11720130560 bytes)
(28) Multiprocessors, (128) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 1633 MHz (1.63 GHz)
Memory Clock rate: 5505 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 2883584 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 9.0, NumDevs = 1
Result = PASS