Training an Ocropus OCR model 中文 - wanghaisheng/awesome-ocr GitHub Wiki
上一篇文章Extracting text from an image using Ocropus 使用Ocropus从图片中提取文本,我们了解了 Ocropus OCR 处理的过程.从如下的图片中提取到文字:

使用默认的模型得到的结果说得过去但不是很理想:
O1inton Street, aouth from LIYingston Street.
Auguat S, 1934.
P. L. Sperr.
NO REPODUCTIONS.
对于larger corpus 中的图片,识别错误率大约在10%左右。默认模型没有遇到过打印字体,也没用处理过ALLCAPS 文本,而在这个语料库里却占了相当的比重。因此识别的准确率低是理所应当的。
这篇文章我会介绍如何训练一个Ocropus 模型来识别我们的图片语料库中的印刷体文本。文章的最后,可以看到识别的效果特别好
Generating truth data
Ocropus 使用supervised learning方法来训练模型:需要一行行的文本图片外加正确的文本。如果你试图识别一种已知的字体,你可以使用ocropus-linegen生成任意数量的标记数据。但在我们的案例中,必须手动标记图片。
标记工作是很冗长的,需要进行大量的输入。亚马逊的Mechanical Turk适合此类任务,但我们更倾向于使用localturk手动完成。
耗时并不像你所想像的那么夸张,我输入了800行花了大约1小时二十分钟。同时标记工作的好处在于你不得不浏览大量的数据样本,也能帮助你更好的理解数据。

(localturk in action)
我使用该模板来完成转录。 Ocropus 要求真实数据保存在后缀为 .gt.txt的文件,且和原始PNG图片同名,比如:
book/0001/010001.pngbook/0001/010001.gt.txt
你只转录单行文本,而非整个页面是很重要的。最开始我是转录的整个页面。想让 Ocropus 学习这些页面,但根本行不通。
Training a model
Ocropus 通过从它犯的错中学习来训练模型。在转录单行文本中的字符时,然后在神经网络中调整权重来弥补错误。然后在这样处理下一行,以此往复。当处理到标记数据的最后一行,又重头开始。随着对训练数据不断的迭代,所得到的模型会越来越好。
ocropus-rtrain -o modelname book*/????/*.bin.png
过程中会产生大量如下的输出:
2000 70.56 (1190, 48) 715641b-crop-010002.png
TRU: u'504-508 West 142nd Street, adjoining and west of Hamilton'
ALN: u'504-5088 West 422nd Street, adjoining and west of Hammilton'
OUT: u'3od-iS est 4nd Street, doning nd est of Sarilton'
2001 32.38 (341, 48) 726826b-crop-010003.png
TRU: u'NO REPRODUCTIONS'
ALN: u'NO REPRODUCTIONS'
OUT: u'sO EROCoOri'
...
TRU 代表真实数据。 OUT 是输出的模型。 ALN 是输出的模型与真实数据对齐之后的变种。用来更加精确的来调整模型的权重。通常该模型会比输出模型看起来效果要好,特别是在初期的迭代过程中。你可以从中得知你的模型是在进步的。
下面的视频是 Ocropus 的开发者Thomas 整理的,演示了在学习单张图片时的输出。
Here's a video that Thomas, the Ocropus developer, put together. It shows the network's output for a single image as it learns (see the YouTube page for explanations of the different charts):
在我的第一个模型里,我把400行标记数据作为训练数据,其他400行作为测试数据。每经过1000次迭代,Ocropus就把模型保存到硬盘上,因此在学习过程中要评估模型的效果是很方便的:
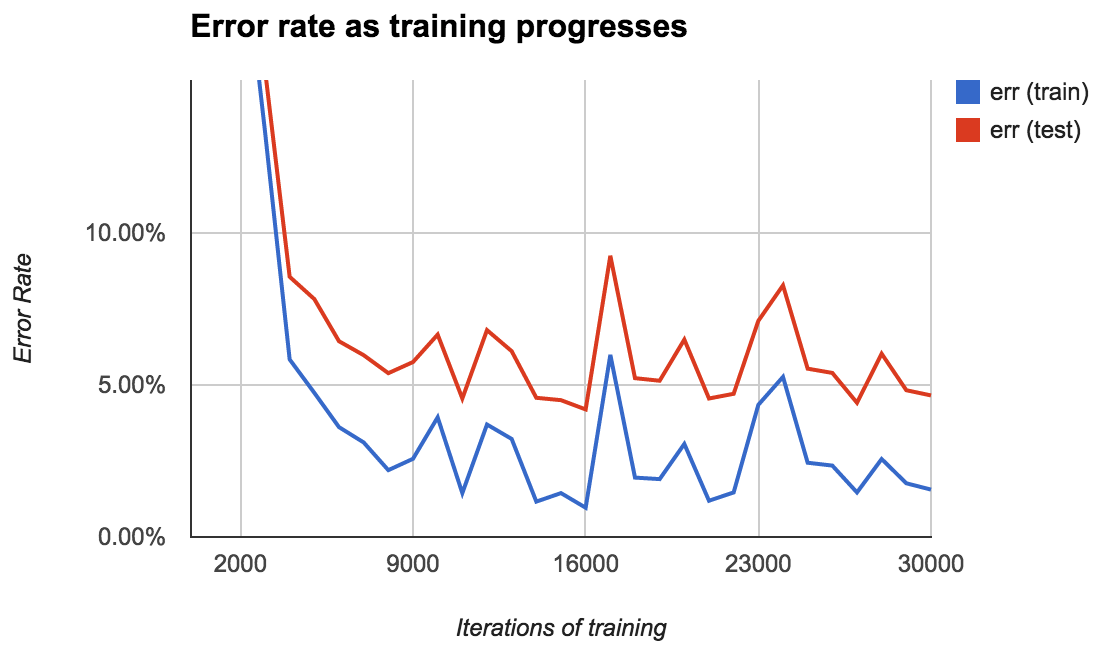
起初错误率很高(超过50%),但在迭代10000次之后很快降到2%,在16000次迭代之后最终降到0.96$%。
对于测试集错误率一直比训练集要高3%或者更多。对于测试集错误率最低是4.2%/
错误率存在诸多变数。你可能期望其随着时间慢慢降低,但并不总是这样子. 我也不确定该如何来解释。I'm not quite sure how to interpret this. Does the error rate spike at 17,000 iterations because the model tries to jolt itself out of a local minimum? Is it just randomness?
任何案例中,都应该生成类似这样的图表。选择一个错误的模型会带来无休止的很差的效果。
Training with more data.
你可能会认为在更多数据基础上进行训练会得到一个更好的模型。于是,在后面的模型里,我用了所有800张标记图片来训练,这样子就没有测试集了。错误率如下所示:
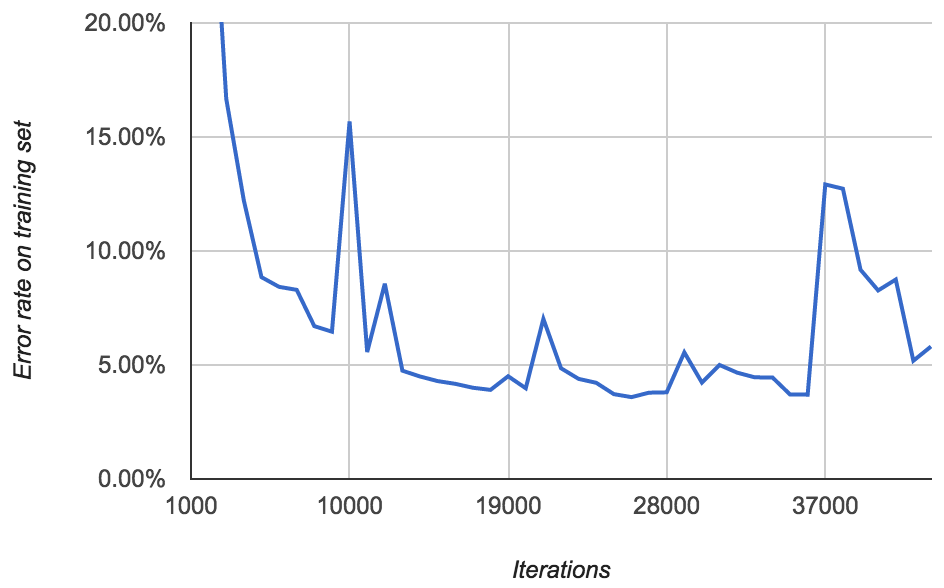
完全不能理解。用800张图片训练得到的最低错误率为3.59%.但 上一次训练得到的模型错误率为2.58% (average of 0.96% and 4.20%).而且只用了一半的数据,这是什么原因呢。也许只是模型自己运气不好。
There's the same pattern as before of occasional spikes in error rate. More disturbing, after around 40,000 iterations, I started seeing lots of FloatingPointErrors. It's unclear to me exactly what this means. Perhaps the model is diverging?
下面的模型我训练了更长时间:
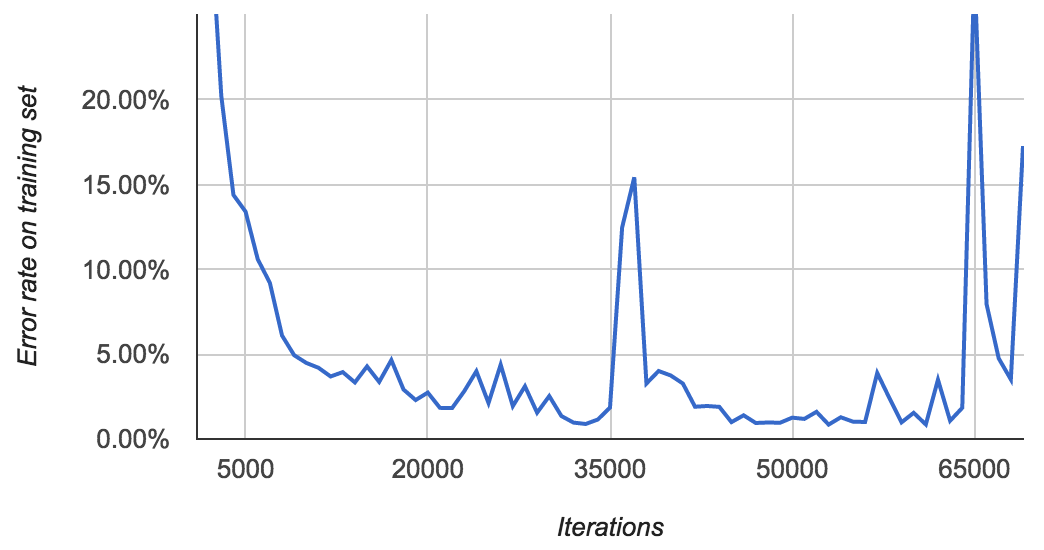
在迭代33,000次时达到了0.89%的错误率,然后在37,000次时跳到15%。最终在53,000次时下降到0.85%,接着又反复。在我停止训练的时候,,我又看到大量的 FloatingPointErrors.
The point of all this is that the error rates are quite erratic, so you need to look at them before choosing which model you use!
Training with the default model
到目前为止,我们从头开始构建了自己的模型。但我们也可以在现成模型的基础上进行构建自己的模型。
即使默认的Ocropus model 并没有遇到过印刷体或ALLCAPS,它也处理了很多拉丁字符和英语单词之间关联关系。我觉得 Ocropus的作者训练出来的模型是要比我自己的好。
使用 --load 参数可以在现有模型基础上进行训练:
ocropus-rtrain --load en-default.pyrnn.gz -o my-model *.png
错误率如下所示:
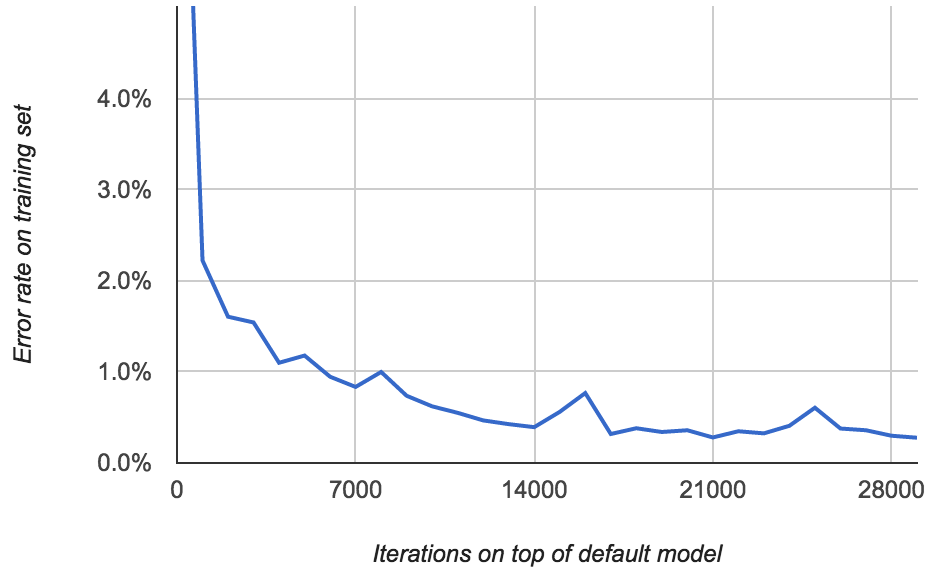
这样我们看到:错误率一路降到0.277%以下
当错误率下降到1%以下的时候是很有意思的。模型所犯的那些"错误"大多是当你在转录真实数据时所产生的错误!我注意到自己拼写错误了一些单词,甚至添加了新的词"the" 到某些行里面。
甚至还有那种原始图片中包含的印刷错误:
(Look at the second to last word.)
错误率0.2%的模型能够产生相当好的文本,比如,如下是从上一篇文章中得到的结果:

→ Clinton Street, south from Livingston Street.
→ P. L. Sperr.

→ NO REPRODUCTIONS.
→ August 5, 1934.
i.e. it's perfect. Here's the output of the Neural Net for the last line:
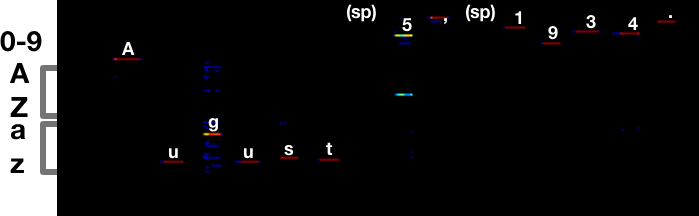
Compare that to what it was before:
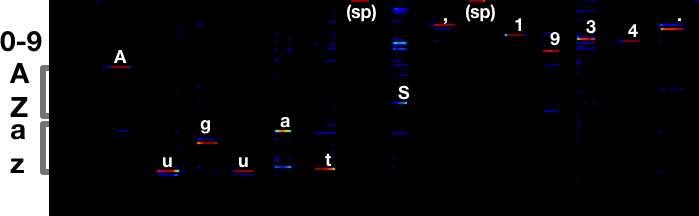
There's still some ambiguity around 5/S, but it makes the right call. The a vs s error is completely gone.
Conclusions
这样子看模型已经很不错。如果我想进一步改进的话,我宁愿改进 image cropper 或者整合一些后处理的步骤来做拼写检查。
在训练过程中模型的效果是飘忽不定的。找到一个合适的模型需要大量的试验和错误。 The behavior of the models as they're trained is sometimes inscrutable. Finding a good one involves a lot of trial and error. To avoid flailing, measure your performance constantly and keep a list of ideas to explore. "Train a model starting with the pre-built one" was item #6 on my list of ideas and it took me a while to get around to trying it. But it was the solution!
If you're feeling lost or frustrated, go generate some more training data. At least you'll be doing something useful.
At the end of the day, I'm very happy with the OCR model I built. Ocropus has some rough edges, but it's simple enough that you can usually figure out what's going on and how to fix problems as they come up. And the results speak for themselves!