核心词的提取 - wanghaisheng/awesome-ocr GitHub Wiki
Relation Schema Induction using Tensor Factorization with Side Information
摘要Given a set of documents from a spe- cific domain (e.g., medical research jour- nals), how do we automatically identify the schema of relations, i.e., type signa- ture of arguments of relations (e.g., un- dergo(Patient, Surgery) ) – a necessary first step towards building a Knowledge Graph (KG) out of the given set of doc- uments? We refer to this problem as Relation Schema Induction (RSI) . While Open Information Extraction (OIE) tech- niques aim at extracting surface-level text triples of the form (John, underwent, Angioplasty) , they don’t induce the yet unknown schema of the relations them- selves. Tensors provide a natural repre- sentation for such triples, and factoriza- tion of such tensors provide a plausible solution for the RSI problem. To the best of our knowledge, tensor factoriza- tion methods have not been used for the RSI problem. We fill this gap and pro- pose Coupled Non-Negative Tensor Fac- torization (CNTF), a tensor factorization method which is able to incorporate ad- ditional side information in a principled way for more effective Relation Schema Induction. We report our findings on mul- tiple real-world datasets and demonstrate CNTF’s effectiveness over state-of-the-art baselines both in terms of accuracy and speed. We hope to make all datasets and code publicly available upon publication of the pape
https://github.com/ysc/word 该分词库中提供的相关词的思路可以用于寻找关键词 核心词
核心词、关键词提取
短文本串的核心词提取。对短文本串分词后,利用上面介绍的term weighting方法,获取term weight后,取一定的阈值,就可以提取出短文本串的核心词。
长文本串(譬如web page)的关键词提取。这里简单介绍几种方法。想了解更多,请参考文献[69]。
采用基于规则的方法。考虑到位置特征,网页特征等。
基于广告主购买的bidword和高频query建立多模式匹配树,在长文本串中进行全字匹配找出候选关键词,再结合关键词weight,以及某些规则找出优质的关键词。
类似于有监督的term weighting方法,也可以训练关键词weighting的模型。
基于文档主题结构的关键词抽取,具体可以参考文献[71]。
今天有同志提到这个问题,说说我的看法
@丕子
大神们 问个简单的问题, 两篇topic很相似的文章(都是体育的),一篇讲李娜,一篇讲莎拉波娃, 余弦相似度很高,但是显然不是重复的文章,有什么最简单有效的方法可以解决下? 直接检测出描述主语是李娜和莎娃,容易么? 谢谢。
首先,核心问题是怎么定义核心词和龙套词
通常我们认为一篇文章,或者一个新闻,是围绕一个主体展开的。这个主体不一定是一个人,可能是围绕李娜的一个新闻,也可能是围绕一项网球技术发展的新闻。前者李娜是核心词,网球术语是龙套。后者网球术语是核心,李娜,莎娃等采用这项技术的球星是龙套。
其次,一个核心技术问题是,怎么区分龙套词和核心词
我们都知道一个新闻来了,首先词袋模型,向量化一把,这样一个文章就变成了类似
新闻1 -> 李娜:4 失误:1 犯规:1
新闻2 -> 莎娃:5 失误:1 犯规:2
有人可能会说,哪个词出现多次,哪个就是核心词,大错啊,有的新闻,李娜就出现一次,其他都用她指代;而且有些词比如网球好多次,肿么办?
正确的方法(我个人认为)是这样的;
每个词都找出其相关词list
会发现李娜的相关词,在新闻1中出现不多。
而龙套词的相关词,往往在新闻1的向量list中有出现(龙套自己暴露了其他龙套)
比如李娜的相关词,可能是一些其他名人,或者他的特别属性
而龙套词的相关词还是龙套词,比如失误的相关词,是犯规什么的。
如果是一个围绕网球技术的新闻
新闻3 -> 上网打法:4 桑普拉斯:1 李娜:2
再用这个方法,就会发现,李娜的相关词有桑普拉斯,说明李娜是龙套词,在这个情况下。
如果一个词出现次数多,且他的平行相关词没有出现在文章中,这个词就是核心词
如果一个词出现次数一般,且他的平行相关词大量出现在文章中,这个词就是龙套词
另新闻标题也是一个重要的特征,考察新闻标题的词在文中的出现次数,也可以作为选择核心词的特征。
最后核心词的发现,肯定是监督学习得到的一个候选list,选好的,就齐了。
某人做的一个词库API,大家可以看看,体会一下。
李娜:http://cikuapi.com/index.php?content=李娜
莎拉波娃:http://cikuapi.com/index.php?content=莎拉波娃
失误:http://cikuapi.com/index.php?content=失误
犯规:http://cikuapi.com/index.php?content=犯规
微博评论
jeankeim:一套模版
回复
2013-11-2 09:23
机器学习那些事儿
机器学习那些事儿:学习//@52nlp://@梁斌penny: 我记得最早是听@kingdy9 说过,09年吧,美军研究的很系统,我的路子不同 //@鲁东东胖: 受教:O网页链接 //@Super_Jiju: 真是你的能量超乎你想像啊 搜搜基于随机游走的kp抽取 textrank啥的 都搞很多年了 //@白硕SH: 嗯,简化描述一下,实际上词被贴上了两种不同的
回复
2013-11-2 09:14
raogaoqi
raogaoqi:嗯哪,介事儿很重要的说呢~
回复
2013-11-1 22:09
raogaoqi
raogaoqi:营养贴,那相关词的list是其他同质语料训练出来的还是本体建设的结果呢?//@鲁东东胖:是否可以这样理解,当一个词和它的同类词一起出现时,往往泛指一个概念,比如当苹果和橘子香蕉同时出现的时候往往指是水果,当李娜和莎拉波娃同时出现时往往指的是网球运动员,等等。这种时候个……
回复
2013-11-1 21:50
白硕SH
白硕SH:回复@鲁东东胖:两个词之间笼统论距离,肯定不如细分差距更有益。温度是天气的一个方面,如果一定要列一个比例式“北京:x=天气:温度”的话,无论上海天津都不是x的最优解,反而是x等于“故宫、中关村、回龙观……”这些北京的“子区域”时更为贴切。这时替换就没有答非所问的感觉。
查看对话
回复
2013-11-1 18:18
鲁东东胖
鲁东东胖:回复@白硕SH: 李航建议从 topic/focus theme/rheme,角度去看这个问题,白老师对此有什么见解呢
查看对话
回复
2013-11-1 18:01
白硕SH
白硕SH:回复@鲁东东胖:更一般的解释是有的。语用学上,确实有人主张,如果不考虑重音等因素,一般来说先说的内容是“given information”,后说的内容是“new information”。所以先说的部分相似而不同,就有答非所问的感觉,但后说的部分相似而不同,答非所问的感觉就弱一些。
查看对话
回复
2013-11-1 17:57
鲁东东胖
鲁东东胖:回复@白硕SH: 基本上是这样,假设我的问题是”北京的温度怎么样?“, 然后去百度知道上找一个类似的问题,用它的答案来回答我这个问题。这是一个古老的问题,对于这个例子也应该有解决方案,但是我想知道有没有更一般的解释
查看对话
回复
2013-11-1 17:48
vinW
vinW:赞。可能得想好自己想要的 相似度 是怎样的,这里是想构造一种能区分新闻当事人的 相似度,那放到有监督特征选择下可能比较好弄。
回复
2013-11-1 17:47
白硕SH
白硕SH:回复@鲁东东胖:这要看你的QA是摘句还是替换疑问词。如果是摘句,问北京而答天津是不可接受的。如果是替换疑问词,拿天津天气的取值替换关于北京天气的疑问词,是可以接受的。退一步说,如果说“反正天津下雨,北京如何,你懂的”,也挺好。
查看对话
回复
2013-11-1 17:45
鲁东东胖
鲁东东胖:回复@白硕SH: 如果从wordnet上的距离来看,北京和上海(或天津)的距离,以及 天气和温度的距离,都很近,但是后者的替换是可接受的,但是前者是不可接受的,也许从命名实体的角度可以解释,但也许还有很多命名实体无法解释的
查看对话
回复
2013-11-1 17:38
白硕SH
白硕SH:回复@梁斌penny:性别是先天的,可以在词典里确定,核心和龙套是后天的,要根据文本动态确定。
查看对话
回复
2013-11-1 17:32
白硕SH
白硕SH:回复@鲁东东胖:把上海换成天津呢?这其实是自变量距离与函数距离的可比性问题。
查看对话
回复
2013-11-1 17:31
梁斌penny
梁斌penny:回复@白硕SH: 有点这个意思,老大和其他人都不同,其他人互相可替换。
查看对话
回复
2013-11-1 15:55
白硕SH
白硕SH:一山不容二虎。
回复
2013-11-1 15:37
谢剑Richard
谢剑Richard:其实key思想还是tf和idf..只是泛义的idf~BTW:顶下楼下的童鞋,词袋model的确需要突破!
回复
2013-11-1 15:11
梁斌penny
梁斌penny:回复@湘阳puck: 当然了,做好不容易,我也只是提供一个思路。。结构性的东西肯定保持下来,比词袋更丰富,路还很长
查看对话
回复
2013-11-1 13:45
湘阳puck
湘阳puck:回复@梁斌penny:这未见得吧,很多随机提及的情况很难通过简单的词带模型解决,不管使用什么trick,idea本身的限制就在那里,突破词带模型本身,才是关键。
查看对话
回复
2013-11-1 13:38
梁斌penny
梁斌penny:李开复,马云,马化腾等大佬一起开会,核心肯定是某个主题。如果李开复发表一个讲话,那核心词肯定是李开复。
https://www.zhihu.com/question/28627372 参考这个回答了解能做什么 不能做什么 大体思路
谢邀。我是做知识图谱和搜索的PhD,我之前一半的基金来自CMU机器学习系的never ending language learning(NELL)组,NELL的目标就是在非结构的文本,网页上用自动的方法来构建知识图谱;另一半的基金来自Google的Knowledge group。哪个组就是做Google自己… [显示全部](/question/28627372/answer/41625214)</div>
<div class="zm-editable-content clearfix">谢邀。
我是做知识图谱和搜索的PhD,我之前一半的基金来自CMU机器学习系的never ending language learning(NELL)组,NELL的目标就是在非结构的文本,网页上用自动的方法来构建知识图谱;另一半的基金来自Google的Knowledge group。哪个组就是做Google自己的知识图谱的构建和在Google产品线上的应用,以及开源的知识图谱Freebase的应用。 在读PhD之前,我在Baidu做过大概一年的命名实体识别,目的就是自动识别出用户搜索词条里面的命名实体。
所以我应该是懂中文+懂搜索+懂知识图谱+有工业界经验的一部分人之一。
不过之前我对 [@季逸超](//www.zhihu.com/people/7b426b1afe45c18850b2342854e09745) 和他们的产品都不了解,也是看到这个问题后才去试验了一下demo。由于是同行,我会尽量避免,但是可能还是会不自觉的有一定的偏见。大家见谅。
-------------评价开始----------------------------------------------------------
**正面评价:**
[@季逸超](//www.zhihu.com/people/7b426b1afe45c18850b2342854e09745) 团队的工程能力非常强,少数几个人在一年里可以搭起来可用的demo,水准不输于我见过的任何一个优秀的工程师。有这样高效的团队,相信往后会越来越顺利。
知识图谱的构建和应用也会是文本相关的各种任务上下一个增长点。Google花了很大力气在做,M$也是,学术界对这方面的关注和投入也在持续增长。我相信往后的几年,即使是这块没能出现类似Uber, Airbnb这样的颠覆型产品,起码能把我们日常使用到的各种工具,例如搜索,siri等,的效果提升到一个新的级别。
最后,Maji找准了国内这块市场的空白,抓到了很好的切入点,原先团队的积累也让Magi在资本市场上一帆风顺,最后这个问题和36氪的PR(宣传)也做得很好。例如和PR成功案例,watson,的联系,以及各种超出科研基金申请报告中描绘的科幻远景。这些都是每一个有志创业的年轻人需要思考和学习的。
总之,我觉得magi能成功,以后如果没有被Baidu抄了去,就会被Baidu买了去。我猜会倾向于买了去,毕竟Baidu自己从头开始做,要花的人力成本也不低了。国内也很难找到对应的人才。
**同时也有很多怀疑:**
疑惑1:
是demo里的那些长query(搜索词条)。长query得理解是非常非常难的问题。更不提理解中文的这种毫无固定格式的问句了。demo中出对几个复杂长query出一些好结果很简单,真正应用做的好么?去试了插件的demo后,我觉得做不好。从demo的效果反推的技术来说,离真的做好demo中提到的那类长query,我个人感觉不是量的差距,是质的差距。
为什么?类比的话,Watson无数工程师,不差钱的IBM毫无业绩要求的完全当做一个PR项目来做,目的就是为了Jeopardy。才能对英语这种,有W和H的显示问句意图表达的语言,且是Jeopardy固定格式的问题,能够做到比较好的效果。这个过程大概花了5年。除了有很多QA领域的专家以外,还有很多工程师的hard code提效果。
而Watson至今离真正商用遥遥无期。我甚至不觉得watson可以真的商用。(我个人对QA的感觉是往后这个东西会真的商用,做到满足大多数日常问答需求。但这个过程可能要5年起步。而且这件事情可能发生在Google,可能在Apple的Siri,也可能是MSR先有paper,但是如果是IBM,我会很吃惊。)
如果Magi能够做到demo中显示的长query的分析效果,甚至不需要做其他的任何事情,就可以有大概让两位创始人一起高科技人才引进的Eb1A类绿卡这种级别的论文,然后也可以被Google,IBM或者Baidu二话不说的收购。
所以我觉得要么是Magi的团队是不世出的天才,一年时间,没有用户训练数据,几个人,还是中文,可以做到demo里长query的效果,要么这个就是为了PR目的的夸大。
疑惑2:
Magi所谓的自动从非结构化信息中抽取知识图谱。Magi主页上写的是:
> Magi 日益增长的结构化数据库中目前拥有950个大类3300个子类的2100万个对象, 囊括从电子游戏到天体物理、从AV女优到美国总统的方方面面信息, 并抽象出了超过1亿6000万条事实的知识网络
这个效果非常惊人。
非常惊人。
非常惊人。
(重复表示强调)
惊人到什么程度呢?如果这是真的,这950个大类,3399个子类,2100万个对象都是真的可用级别的话,那么:
1,创始人把这个写出来可以拿任何一个相关领域顶会的Best Paper,会成为Information Extraction领域的新的明星。
类比:Open Information Extraction和我们学校的NELL是比较有名的自动从非结构化信息抽取知识图谱的工作。前者是University of Washington at Seattle的,后者是CMU的。两个组光做这两个系统,都做了超过5年。CMU的直接是机器学习系的系主任领头,抓取和分析程序几年来没有停止过,但是还是做不到Magi的1/10的级别,噪声也特别多,尚未达到可用级别。数量和质量都不如直接用Wikipedia的dump。而Wikipedia的对象大概有多少呢?500万左右。
2,Google或者MS会直接愿意买,别的什么都不要,就只是这个系统。
类比:Freebase [Freebase](//link.zhihu.com/?target=http%3A//www.freebase.com/browse) (需翻墙...) 是知识图谱里最好用的。2010年Google花了大价钱买了下来。花了多少钱没有公布,但是Freebase之前已经拿了$57M的融资,Google花的钱应该是这个的两倍起,那就是一亿美金往上。
Google买了下来之后花了很多人力去提升Freebase的质量和数量,还有社区的贡献,自动和非自动的方法都上了。4年之后,Freebase的量级是多少呢?
> 3700万个对象,5亿的事实,**77**个大类
和几百个小类(具体没有数了)。
而这3700万个对象里面,可用的部分,即信息全面,有名称,文本描述的有多少呢?
还是500万。这是Google和我们组合作发布的网页实体标注里用到的对象集的大小。
而且,这些统计都是英语。
所以如果Magi主页上宣传的是真的,那么几个人,一年时间,通过在已有的Wiki,百科之类的地方之外,在中文这个比英文更难得语言上,做出了超过Google花了$57M以上收购,并作为下一个核心增长点耕耘了4年的Freebase的效果。
同时,甚至可以说Magi凭借几个人的力量,解决了中文分词剩下5%的问题里的一大半,从此中文分词甚至可以说是一个solved problem。众所周知现在分词95%的情况下已经可以做到非常好了,剩下的5%是罕见词的问题。而这里面绝大部分是命名实体,也就是所谓的对象。
而2100万的命名实体是什么概念呢?一般中文分词能够切分出来的词的数量,大概在几十万的量级。在这几十万的基础上,一下子加了2100万的命名实体,想必从此之后:
* 任何一家中文信息处理公司都基本不用再为分词担心,
* 所有在线广告可以直接通过这2100万的命名实体效果提升一个量级,
* 所有中文输入法不会再出现需要一个个选单字的问题,不需要再选择download神马行业词库,只靠这2100万,似乎就够了。
如果这些都是真的话:
跪求公布数据... 跪求深度合作... 跪求不要卖给不开源的黑心大企业。
同时真心为我的怀疑道歉,并求Magi给面试机会......
为了人类文明的进步,前进!前进!前进!
---------------------评价完毕, 技术讨论开始----------------------------------------------
我们系的几个做搜索和信息抽取的同学,以及MIT的做NLP的同学今天讨论的时候,认为如果靠Wikipedia,Dbpedia,百度百科,加上从特定行业的网站上做一下table之类的信息抽取,再用开源软件来搭,那么大概一个我们这样做算法的PhD,加一个后端工程师,做出Magi目前的效果半年左右似乎可以。
如果要demo,那就再要一个会前端的人,1-2个月做一下。
我猜测MaGi大概也是类似的团队配置,如果只有2-3个人的话。
下面大概YY一下,如果要我一年内做出Magi的demo插件的效果,应该怎么做。
声明:我下文会提到非常多的开源实现,由于我只是YY,所以并不需要担心使用授权的问题。
我之所以会用到那么多开源是由于人力和时间限制(2-3人,一年),不大量使用已有工具从轮子开始根本不可行。
至于实际Magi用了哪些,不在通过我得到的信息可以讨论的范畴。
**背景知识:**
知识图谱是一种对人类知识的进行存储和表示的半结构化数据集。一般知识图谱的信息中心是命名实体,也叫entity,object,对象,等等。然后常见的信息有:
* 对象的分类信息(ontology),例如:知乎 是一个 网站,
* 对象的属性(attribute),例如:知乎 的女神数有 xxx万,
* 对象之间的关系(relationship), 例如:知乎 CEO是 黄继新,
* 对象的文本描述(description),例如:知乎“是一个好网站,但是有些人居然在上面约来约去,这样是不合适的。尤其是只约别人不约我的话。”
例如下图是英文最大的公开知识图谱Freebase的一个对象:Barack Obama:
<noscript>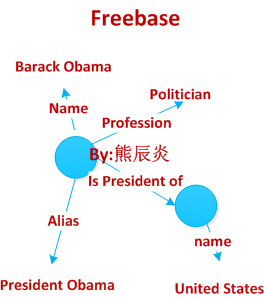</noscript>

而Magi做的事情,基本上可以理解为对用户的查询query,在有确定置信度的情况下直接返回知识图谱中的结果。
<div class="highlight">
Input: query “郭敬明的身高是?”
do:
1,转为structured query “郭敬明[entity]->身高[attribute]”
2,从知识图谱中找到结果 "163cm"
3,评估结果置信度 p(郭敬明身高=163cm) < 0.5
4, 如果置信度足够高,输出结果
output: 知识图谱中的结果(163cm),或者None(转为关键词匹配结果)
</div>
-------------------------------------开始YY实现,非技术党可以跳到最后-----------------------------------
**首先,我需要一个中文的知识图谱:**
我会先从官网上下载Wikipedia和Dbpedia的中文dump,然后再去抓或者其他渠道获取百度百科,或者互动百科。然后把他们页面里的table抽出来,和Dbpedia或者其他的严格定义好的semantic数据库信息一起,作为命名实体(entity,对象)之间的关系。同时把百度百科和Wiki的分类树(ontology)拿出来,作为基本的类别定义。
这些对于中文可能并不够,我还需要抓取**指定**的几个网站,从里面用**给定模板**抽取里面的命名实体和关系。主要目标是分类信息(ontology),以及表格,列表上的命名实体,关系,属性,分类信息。然后谨慎的加入Wiki或者百科的数据里。
这样我就有了初版的知识图谱。根据现有学术界的进展,靠社区**人工编辑**形成的知识图谱(Wikipedia, Freebase),在质量,覆盖率,精准度上都**远超**任意一个公开的全自动生成的知识图谱(NELL,OpenIE,DeepDive)。所以我会主要依靠中文Wiki和百科,然后辅助定向抓取的自动生成的结果。
这部分是最花时间,也是最关键的工作。数据的清洗,不同信息源结果的合并,以及自动抓取和模板分析都有很多dirty work在里面。这也是我对Magi主页说的
> Magi 日益增长的结构化数据库中目前拥有950个大类3300个子类的2100万个对象, 囊括从电子游戏到天体物理、从AV女优到美国总统的方方面面信息, 并抽象出了超过1亿6000万条事实的知识网络
最吃惊的部分。我觉得如果做到百度百科和中文Wiki的数据全部清洗好,然后再加一点点固定网站上的结果就已经非常不错了。能做到2100万个**可用**的命名实体,实在是太出色了。在看到他们向学术界发布的公开数据前我表示难以置信。
一个命名实体想要可用,光有这个词是不够的,你还需要有:
* 分类信息(ontology)
* 描述(description)
* 一些属性(attribute)
* 和他的主要的相关对象之间的关系(relationship)
目前最大的公开知识图谱Freebase的达到这个要求的命名实体数是500万,还是英文。
有了这个知识图谱后,剩下的部分都是可以靠在已有的技术上做一些工程开发和优化可以解决的了。
**我还需要一个中文分词系统:**
尽管在多年前,可能是近10年前,百度的”百度更懂中文“的广告系列给大家建立了中文分词是一个很高大上的技术这个印象。现在经过中国科学家们的努力,中文分词已经做的非常非常好了。对于**绝大多数**query,分词不再是效果的瓶颈。
所以我会直接使用现有的工具,例如中科院的ICTCLAS,哈工大的LTP。
他们对于我的需求基本足够。
为了更好的效果,我会外挂一些行业词库,然后自己再把分词切碎的长短语通过entity词表粘贴起来。这可以解决绝大多数问题。
至于进一步的效果提升,需要更多的人工标注预料,或者更好的统计模型,这些都很困难,而且可能在N年内都不会是整个系统的效果瓶颈,所以我会先忽略这些。
PS:其他答案里提到的Magi分词做到了baidu的效果其实并没有什么,对于手工尝试的query们,开源分词已经可以做到和baidu不太看的出区别了。
**然后,我要对这个中文知识图谱建立索引:**
建立索引的目的是为了对搜索词条(query)快速响应。有两种方法可以选择:
1,Graph Datebase,或者直接Database。例如Neo4j,或者直接MySQL。这样的话就是把知识图谱当作严格的结构化信息,然后当作图,或者简单的columns存到Graph DB/DB里。
这样的好处是支持严格的结构化query查找,例如:
<div class="highlight">
find 苹果->首席执行官
-------结果---------
库克
</div>
但是这样要求query必须**严格**匹配,其实非常受限。这个问题叫做semantic search,已经被学术界研究了很多年,但是并没有成熟应用。
而且,由于一般graph db支持的query结构过于复杂,导致速度很难上的去。而复杂的结构化query和Magi的需求并不太合适,所以我会选择第二种。
2,搜索引擎的反向索引,例如Lucene,Indri。这样就是把每个entity的信息作为一个文档,所有的信息都待着xml tag放进去,然后搜索的时候按照关键词来匹配,拿到结果后再重新结构化,再和query做匹配。
为了支持对名字,描述,关系,类别,属性的匹配,我把它们各自封装到对应的xml tag,或者field里,然后每来一个query,我会对这几个field都做关键词匹配的检索。
**有了这些数据,我就可以对query进行在知识图谱中的搜索了:**
**1,**先要明确的是,我不知道如何在超过一阶关系的长query上**在保证recall和覆盖率的情况下做到可用级别**的效果。例如:
<div class="highlight">
query:美国的总统的老婆
转为structured query: 美国->总统->配偶
返回:米歇尔奥巴马
</div>
这个问题我没有解决方案,学术界没有,Google没有,百度没有,Magi的视频和主页上说的有,demo插件里没有。
截图:
Google:
<noscript>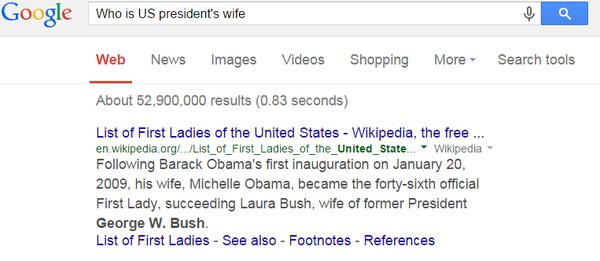</noscript>

Baidu和Magi插件
<noscript>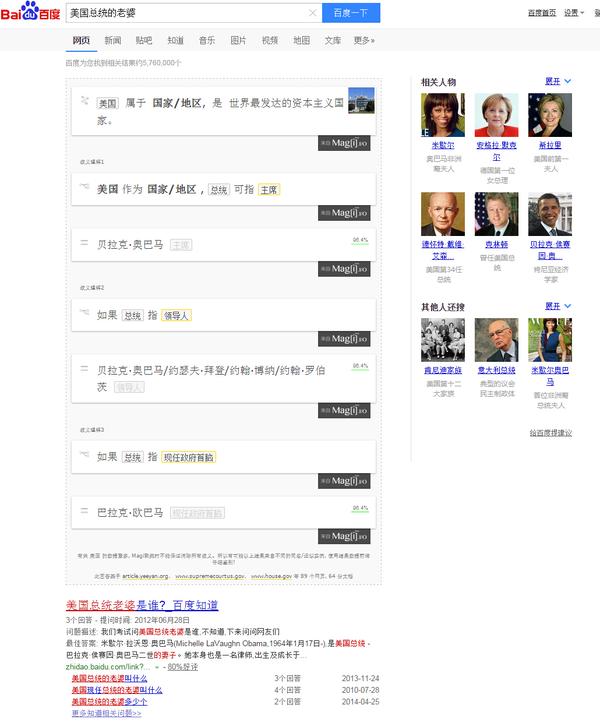</noscript>

可以看出这三者都没有分析出这个query的结构信息:
* Google似乎没分析出来,但是通过关键词匹配返回了Wiki结果
* Baidu似乎没分析出来,但是通过关键词匹配找到了百度知道,以及右侧的相关人物(这个我不确定怎么做,猜测是垂直搜索+搜索日志中的相关query)
* Maji只返回了"美国","总统",”美国加总统“这三个关键词匹配的结果,丢掉了”的老婆“,把美国放在了第一位,且没有去重。
可以看出**基于目前技术**在这种长query里,直接做关键词匹配是比转结构化query,再直接返回结果要更可信的。
(根据和季大帅哥讨论)对于一些长query,例如
"美国总统是谁?他的老婆是谁?"
这个Magi有找到结果,猜测是用pattern,或者是转为了某种structure,然后在知识图里做了推理。
截图如下(图中最后):
<noscript></noscript>

但是
”"美国总统的老婆是谁?" 就不行了。
然后
”中国首都在哪里?它的面积是?“ 这个推理不对。
”中国的首都在哪里?它的面积是?“就可以。
这些例子反映了长query理解的难点:
* 从文本query->structure query的转化非常难,一点语言的变化就会带来新的挑战。
* 长query往往对应着高阶关系,这里面的noise是**乘数**关系,每一部一点小小的失误累加起来就会使得结果完全不靠谱
而搜索是一个对精确度要求特别高的应用,如何在**保证召回**说得过去的情况下(例如1%的网页query),达到足够高的precision?
这是学术界和工业界都没能解决的问题,我对Magi在能看到的1-3年内能否解决持怀疑态度。
**2,**但是,我可以做到对直接的命名实体的查询,以及一部分命名实体+关系的查询。
前者是:
<div class="highlight">
query:苹果公司
返回:[苹果公司] 是 一家消费电子公司
</div>
后者是:
<div class="highlight">
query:苹果公司首席执行官
structured:苹果公司->首席执行官
返回:库克
</div>
2.a,首先解决单个命名实体的查询
这个是可行的,也是学术界工业界已经做到了的。
这个问题可以定义为entity linking问题,既,给定一个文本,如何找出其中的entity,然后match到知识图谱中的对象,目前学术界最新的结果大概是50-60%的F值,具体见最新的比赛结果:
[Microsoft Research](//link.zhihu.com/?target=http%3A//web-ngram.research.microsoft.com/erd2014/)
大概做法是收集足够的别名,给定一个query后做一次精准匹配,然后把匹配到的名称的对象拿出来,然后用上下文进行消歧。
这个任务主要有三个问题:
* 消除歧义:苹果是水果,还是电脑?
* 别名,(Alias,surface form)的处理:既如何做到“春哥”->李宇春的识别
* 覆盖率:知识图谱够不够大,够不够全。
我相信Magi以后做得好这个。目前的demo上,还不够好。我个人感觉这应该是最先解决的问题。
例如:
消岐上:“苹果的首席执行官是谁” 已然匹配到了水果的苹果。为了大家的流量,我就不截图了。
而surface form和覆盖率已然要靠足够大和全的知识图谱。而目前已知的做法离自动构建超过人工编辑的知识图谱距离很远。
2.b, 然后是基于命名实体的结果之后的一阶关系查询
这个通过关键词来hit到知识图谱中的关系即可,对于明显的类似两个词的query是做得到的。
我试了一些query,各选三个好的和不好的。
好的:
<div class="highlight">
微软创始人
苹果公司创始人
北京面积
</div>
不好的有(包括我猜测的原因)
<div class="highlight">
“李宇春 性别” 性别没有match到对应关系
“科比在哪个队”/“科比 球队” 知识图谱里没有科比的球队信息
“北京 邮编” 没有邮编信息
“苹果创始人” 没有利用创始人这个词对苹果进行消岐
</div>
根据这些结果,我觉得是先做了命名实体匹配,然后用剩下的部分做一次对关系的几种名称的exact match之类的方法。离能够解决自然语言多种variance,然后给出和关键词匹配一样级别的模糊查找,相距甚远。当然这不是Magi的问题,而是整个学术界工业界都尚未解决的问题。
**最后,我需要做一个UI界面来展示结果**
这个需要去找一个好的前端来帮我做这个事情=。=
--------------------------------------------总结-------------------------------------------------------------
辛辛苦苦总算是答完了。在回答了如何评价之后又新加了很多我对知识图谱和搜索现有技术的理解和猜测。通过过程中和大家的讨论,以及demo的试用,我个人觉得Magi两三个人能够在一年内实现这些技术的应用转化,非常了不起。但是并没有看到“颠覆性”的技术进步。
关于magi的总结:
**我认为大家Magi的合理期望是什么?**
* 通过对Wiki和百科的收集和处理,建立起中文语料里第一个正经意义上的知识图谱,
* 做好中文命名实体的识别和消岐,做到可用级别的precision recall,
* 做好一定覆盖率的高精度的一阶关系查询“苹果->CEO”
如果Magi能够在最近的几年做到这些合理期望,那么Magi就一定会成功的。
**我对Magi声称的目标表示怀疑地方是:**
* 从无结构的文本中自动抽取大于中文百科的量级的对象和关系,
* 根据已有知识图谱做自动推理,从而“一生二,二生三,三生万物”。实际问题里一般这就是“garbage in, garbage out”,
* 对长文本query的自动理解,生成高阶关系的structured query和查询。
我对这些表示谨慎怀疑。
个人倾向是把这些当作是面向普通用户,而不是投资人或圈内同仁,的宣传手段。当然这无可厚非,可能大家还要好好学习 :P
最后,
我个人相信往后的5-10年将是文本理解的一次新的革命性的发展,deep learning的新的表示方法,和知识图谱带来的全局知识信息,将会大大提升计算机对自然语言的理解和处理能力。
但是这个革命的时间并不是此时此刻,所需要的技术进步也不是靠一个英雄人物,或者一个英雄团队就可以完成的,而是需要整个工业界学术界的同仁们共同的努力。
共勉。</div>
参考
1.语义分析的一些方法(一)
69.Brian Lott. Survey of Keyword Extraction
71.刘知远. 基于文档主题结构的关键词抽取方法研究
新闻的核心词和龙套词
微博上的相关评论"新闻的核心词和龙套词"
Schema Extraction for Tabular Data on the Web
Unsupervised Approach to Deduce Schema and Extract Data From Template Web Pages
Page-Level Web Data Extraction from Template Pages
Review paper on “Optimized approaches for web data harvesting
WEB SCHEMA DETECTION AND DATA EXTRACTION SYSTEM
Representation Learning -A Review and New Perspectives
https://en.wikipedia.org/wiki/Keyword_extraction
NLP keyword extraction tutorial with RAKE and Maui https://www.airpair.com/nlp/keyword-extraction-tutorial
https://github.com/lavizhao/keyword
https://github.com/lvsh/keywordfinder
