Apache Kafka - w4111/w4111.github.io GitHub Wiki
- qy2314 John Yang
- Set up the page
- The key challenges
- How did Kafka solve the problem
- Tutorial: A client streaming data using Kafka API
- ajl2315 Amanda Li
- Relating Kafka to W4111
- API
- Transaction
- Recovery
- Concurrency Control
- shp2156 Sarah Park
- Relating Kafka to W4111
- Storage and Files: Data Storage Design; How Kafka Brokers Handle Data; How Clients Access Kafka Design; Memory Access and Caching
- Indexing
- Security/Privacy
- Relating Kafka to W4111
- zz3306 Lucas Zheng
- Tutorial 2: Producing Streaming Data Using Kafka API (Follows after Tutorial: A client streaming data using Kafka API)
- Alternatives (RabbitMQ; Amazon Kinesis; Apache Pulsar; ActiveMQ; Redis Streams)
- Pros and cons of the technology compared with alternatives
- What makes Kafka unique
- hje2113 Hans Encarnacion
- Performance optimization with denormalized data
- Alternatives (Google Pub/Sub)
- Example of Kafka used for a Music Review Application
The Problem and Solution
Key Challenges Apache Kafka Aim to Solve
In the lectures, we discussed how traditional databases like Postgres are optimized for batch insert, modification, and deletion of records. However, there’s a mismatch between the operations they are optimized for and what modern analytics software needs. There are two main challenges traditional databases face when addressing modern real-time analytics needs.
First, In many use cases, data are often produced in large quantities, ingested by multiple applications for analytics, and act on events as they happen. Traditional databases don't perform well when handling large volumes and high throughput data generated by modern systems, especially when this data needs to be processed in real-time. For example, for Agoda, a large travel booking website and Kafka’s client, real-time data processing is critical to provide users with personalized search experience and targeted deals. Every second, millions of Users’ click, browse, and search action data need to be processed, analyzed, and acted upon to give users real-time recommendations. Traditional databases like PostgreSQL are optimized for transactional workloads such as recording bookings or updating availability. But they struggle with real-time, event-driven processing.
Second, traditional databases struggle when data needs to be shared by multiple systems at the same time on a large scale. When many services, like processing event logs, running recommendations, or detecting fraud, try to access the same data stream at once, concurrency issue occurs, and implementing Strict 2PL slows down the application. Databases like PostgreSQL aren't built to handle this kind of heavy, simultaneous use efficiently. As more systems try to read and process data, the database can slow down, creating delays and bottlenecks that make real-time processing difficult.
How Does Kafka Solve These Two Challenges Faced By Modern Commercial Analytics Applications?
Kafka provides a event streaming platform that helps users manage real-time data at scale and share it efficiently across different applications (clients). On a lower level, it splits data into smaller parts (partitions) and distributes them across multiple brokers (servers). This architecture enables Kafka to handle high throughput of events with low latency. Kafka is different from traditional databases like Postgres because it treats all data as a continuous stream of events that can be processed immediately (as opposed to batches). Kafka also ensures durability and reliability by saving data to disk and saving multiple copies of data across servers. This design keeps the data safe even in the case of hardware failures.
More specifically, for the first challenge of handling large amounts of real-time data, Kafka’s distributed architecture makes it capable of managing huge volumes of data at very low latency. Unlike traditional databases, which are usually optimized for handling large chunks of data in batches, Kafka’s event-driven approach processes data as it comes in (almost instantly). This makes it ideal for use cases like personalized recommendations or pricing that change on the fly, where it’s important to respond quickly to user actions.
To solve the second challenge—concurrency of data sharing across different systems—Kafka uses a public-subscribe model that decouples data producers (systems generating data) from consumers (applications using the data). Producers send data to Kafka topics, and multiple consumers can subscribe to these topics and process the data independently without getting in each other’s way. This design reduces the performance hit seen in traditional databases related to concurrency, where multiple systems trying to access the same data/tables can create bottlenecks. Kafka is designed to support many consumers reading from the same stream. Thus, it allows applications like a recommendation engine, a fraud detection tool, and an analytics dashboard to all use the same data at the same time. Its scalability means Kafka can continue to perform well even as more systems are added.
 Credit for visual illustration: Emre Akın
Credit for visual illustration: Emre Akın
- What are the alternatives, and what are the pros and cons of the technology compared with alternatives? (what makes it unique?)
- How it relates to concepts from 4111.
- NOTE: illustrating the relationship with concepts from this class IS BY FAR THE MOST IMPORTANT ASPECT of this extra credit assignment
Remember, the more detailed and thorough you contrast the technology with the topics in class the better. We've discussed the relational model, constraints, SQL features, transactions, query execution and optimization, and recovery. Pick a subset of topics to really dive deep and compare and contrast the similarities and differences between our discussion in class and the technology.
Relating Kafka to COMS4111
API
In class, we talked about API and how servers interact with clients. Kafka also has servers and clients interact through TCP network protocol, but in contrast, it operates in a distributed manner. More specifically, the servers in Kafka run as a cluster, which is distributed among data centers and cloud. In the traditional server machine described in class, there might be potential concern regarding the scalability and fault-tolerability. However, the servers in Kafka are partitioned and replicated across different machines and cloud, such that it is highly scalable and fault-tolerant.
 Figure. Overview of Kafka API (credit to https://kafka.apache.org/)
Figure. Overview of Kafka API (credit to https://kafka.apache.org/)
Transaction and ACID Guarantees
Kafka uses a log-based architecture and uses the concept of events to indicate that something happened. An event in kafka contains a key, value, and timestamp. For example, an event A can have key “Alice”, value “Made a payment of $200 to Bob”, and timestamp “6/25/2020 at 2:06 PM”. Kafka also maintains a log that records events. In Kafka, it utilizes the concept of topic as the “log” to store ordered collections of events in a durable way.
There are two main characters of clients, the producers and the consumers. The producers are client applications that write events to Kafka, and consumers are the ones that read and process events from Kafka. Kafka is designed to ensure that these transactions between producers and consumers with the server meets the ACID guarantees that were described in class. They include atomicity, in which the user never sees in-between transaction state, and only sees transaction effects once committed. We also mentioned durability, such that if a transaction commits, its effect must persist. Furthermore, Kafka also ensures isolation, such that from a transaction’s point of view, it is the only transaction running.
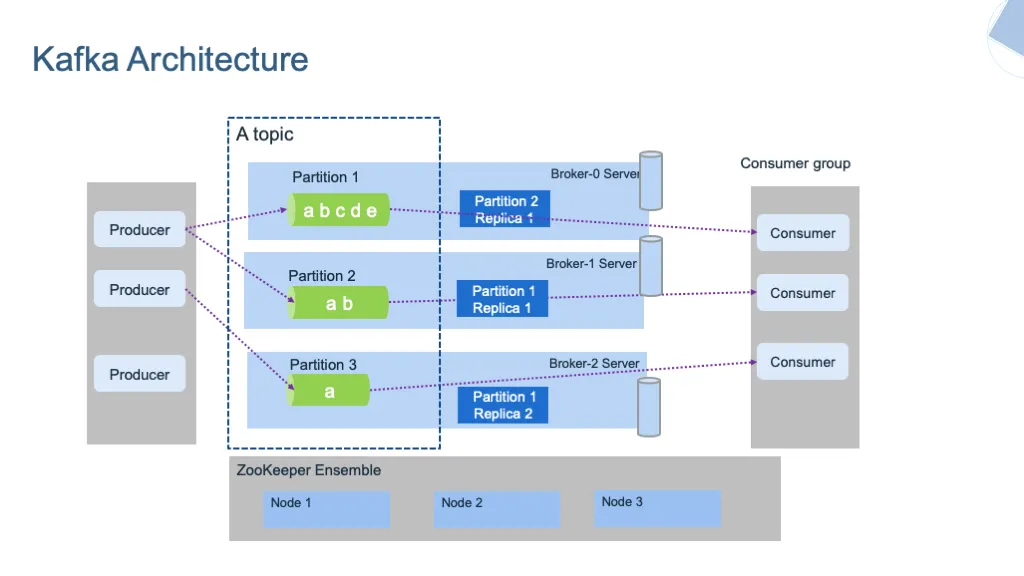
 Figure. Overview of Kafka architecture
Figure. Overview of Kafka architecture
Recovery
In class, we talked about several scenarios of crashes and we want to ensure the proper recovery of the DBMS. Kafka ensures that the data to be processed and delivered to the consumers once and only once, even under crashes. Below, we will discussed crash and recovery scenarios under the assumption of a perfect broker (a layer of topics in Kafka).
From the producer's point of view
Kafka ensures that once a message published by the producer is committed, it will not be lost. For example, there could be a network error that happens after a producer publishes a message, and the producer cannot be sure whether the error happened before or after committing the message. In this scenario, there are two potential solutions:
1.) The message can be resent to the server, however, there could be potential duplication in the case the the network error occurred after the commitment of the message
2.) Kafka’s solution
In Kafka, each producer is assigned with an ID by the broker, and every message is associated with a sequence number. Thus, the broker can check if the message was delivered from the producer by deduplication using the sequence number. Moreover, to ensure durability, the message sent by the producer is saved in multiple topic partitions, as mentioned earlier, and to ensure atomicity, Kafka ensures that either all messages are successfully sent or none are.
From a consumer’s point of view
The design of the Kafka system needs to know what has been processed and read. This relates to the serializability concept discussed in class: we do not want reads and processes of data that violate the isolation guarantee that in turn violates durability. Thus, in Kafka, each consumer has a log and position. The consumer’s operations are also replicated, in which each replica also has the same log and position to further ensure durability, in case one of the replicas fails.
In class, when we discussed recovery, we compared the different resulting scenarios of failure dependent on the transaction operation order and the timing of crashes and how the corresponding recovery method depends on these scenarios. Kafka’s design of ensuring durability on consumer’s perspective is also optimized based on the aforementioned considerations.
As discussed, in Kafka, a consumer reads and processes messages published by producers with recorded positions in the log. There are a few orders of operation:
1.) read message -> saves position in log -> (crash) process message
In the first order of operation, if a crash happens after saving its position and before saving the output of message processing, then the backup process (because there are replica) that took over after crash might start at the new position even though the output of the last processed message is not fully saved
2.) read message -> process message -> (crash) save position in log
In the second order of operation, if a crash happens after processing the message, but before saving the position in the log, and the backup process takes over, the new process will re-process the message.
Kafka's solution bundles the consumer position with the output of the processed data together as a transaction to the output topic, such that in case of a crash, the transaction is aborted, so both the processed data and position will be reverted. This solution ensures the durability of data, because it completes what is promised to users. A pictorial representation is shown below.

Data Replication
As mentioned before, another way that Kafka ensures durability is through replication. The servers in Kafka are stored across georegions and data centers, and each topic partition is replicated across brokers. Kafka manages these replicates in a hierarchical manner. For each partition there is a leader replica and a number of follower replicas. The leader handles all read and write requests for that partition, and the followers will hold a replica of that partition, it should theoretically be identical to the leader. This guarantees that the message is not lost as long as at least 1 follower exists. In the case that a leader fails, a new leader is elected amongst the followers.
Concurrency Control
In class, we discussed the concept of concurrency control, for which we want to handle transaction that that ACID guarantees are enforced. In Kafka, consumers can read from different partitions concurrently. The distributed system with replicated data logs allows this capability in Kafka. Different consumers can read the same data from different replications simultaneously. Producers can only send write requests to the leader, and as discussed earlier, the write requests sent will only be delivered once. After the write requests are completed, the result is updated to every follower. A message is only considered “committed” if it has finished replicating to all followers, which ensures the atomicity guarantee, for either all happened, or none happened. This way, different consumers reading from different followers will obtain the same data, and the users only sees committed data.
Performance optimization with denormalized data
In relational databases, data is often normalized in order to avoid redundancy. However, with Kafka, sometimes denormalizing the data is better. Kafka topics often use denormalized data in order to enable high-throughput, low latency, and make real-time data processing more efficient. Denormalization simplifies the flow of data and hence makes the processing of such data more efficient. For example, let’s say a database has two tables Users and Comments. The Users table has fields user_id, name, email. The Comments table has fields comment_id, user_id, content where user_id is a foreign key reference to the user_id in the Users table. The computer scientist might combine the two tables into one to maximize data-processing efficiency. This is called denormalizing the data. This allows for certain queries to be faster since all information is in one table, hence avoiding the action of joining related tables or querying from multiple tables when processing data in real time. Kafka prioritizes performance optimization, as its goal is to perform efficient, real-time analysis of data. Therefore, it might make sense to denormalize some data tables. Of course, it is up to the computer scientist if they want to do this. There are downsides to denormalizing data such as redundancy. As a result, it is the computer scientist’s job to determine what is more important for their application’s tables: avoiding redundancy (utilizing normalization) or performance optimization for Kafka’s real-time data processing (benefiting from denormalization).
Storage and Files
In class, we discussed how data is stored across different layers of memory and storage depending on its usage and access patterns. For instance, frequently accessed data is stored in RAM for faster access, while larger datasets and less frequently used data are stored on SSDs or disks. SSDs provide faster read/write access speeds compared to disks, while disks are used for cost-effective bulk storage. The DBMS optimizes where to store data to balance performance and cost. These concepts of storage from traditional DBMS systems can relate to Apache Kafka in which we will further explore below. First, we will describe the data storage architecture then relate it to memory accessing and caching.
Data Storage Design
Apache Kafka follows a distributed log storage pattern. In other words, this approach stores all incoming data sequentially in an append-only log, meaning that the data is written in the order it arrives and that once the data is written, it cannot be modified. This design allows efficient sequential read/write operations for both writes by producers and reads by consumers. Kafka storage is optimized for sequential access patterns rather than random access, which ensure optimal performance. Kafka’s storage architecture relies on the following core components: topics and partitions, log segments, and index files.
Topics and Partitions: Topics are logical groupings that represent categories or streams of data. An example of such logical groupings are “temperature_readings” or “vehicle_location.” Topics are the logical abstraction for data streams. Partitions are subdivisions within a topic that act as independent logs. Each partition can scale independently and can be distributed across multiple brokers to allow for parallel processing. Partitions are stored as directories on a disk, and it contains the log segments. Partitions also allow Kafka to horizontally scale by spreading data and loading across brokers.
Log Segments: Each partition contains a series of log segments, which are files on disk storing messages. Segment files are named using the base offset of the first message in the segment. Log segments are rolled over either when a specific size is reached or a specific time period elapses.
Index Files: Kafka uses two types of index files for fast data access. An offset index maps message offsets to their physical file positions for fast lookups. Time index maps timestamps to their physical file positions for efficient time-based searches. Both types of maps are considered sparse indexes, which means that they store only a subset of entries to memory. The rest of the entries are fetched from the disk when needed.
Next, we will discuss how Kafka brokers handle data along with clients access Kakfa data.
How Kafka Brokers Handle Data
Kafka brokers are server instances that are mainly responsible for managing storage, replication, and data retrieval. Brokers also coordinate partition management across the cluster. There are two types of brokers: leader broker and follower broker. For a given partition, a specific broker is assigned as the primary point of contact. The leader broker handles all read and write operations for that partition. A follower broker, on the other hand, replicates data from the leader broker to maintain durability and high availability.
When a producer sends data to a topic, Kafka uses partitioner logic, such as key-based hashing, to assign the message to a specific partition. The leader broker for that partition appends the message to the log file on the disk.
Kafka makes sure that data is durable throughout the entire process by replicating partition data across multiple brokers. Also, messages are deleted from logs based on Kafka’s retention policies. An example of retention policies are that messages are deleted by how long it has been stored and if a threshold has been exceeded.
How Clients Access Kafka Data
Consumers access data sequentially from Kafka partitions by connecting to the cluster using the Kafka Consumer API mentioned earlier. The main thing to takeaway from here is that offsets track consumer read positions and consumers fetch data sequentially starting from their committed offset. Data is then directly accessed from partitions stored on the broker’s disk.
Memory Access and Caching
Kafka uses RAM, OS-level caching, and disk mechanisms (page cache) to make for efficient storage and retrieval processes. Kafka uses RAM for multiple different occasions. One instance is when messages are sent to producers, they are first buffered in RAM to make sure that the writes are executed quickly to brokers. Additionally, consumers temporarily cache messages in RAM after fetching them to improve read performance. Finally, Kafka keeps the topic and partition metadata in memory to reduce the cost during broker operations.
Similarly, OS-level page caching helps reduce the latency of disk reads by preloading messages or logs that are frequently accessed.
Finally, Kafka heavily relies on disks. While SSDs are faster and optimized for random accesses, because Kafka relies on sequential read and writes, spinning disks are sufficient. Most importantly, log segments are on the disk. Kafka writes data sequentially in logs, with partitions stored as directories in these logs. The log segments are managed by Kafka’s retention policies, which helps make sure space is reclaimed in disk when the data is no longer needed. Having messages written to disk ensures data persistence. This allows Kafka to recover messages in case of failures.
Indexing
In class, we learned about traditional DBMS indexing. The techniques we learned help speed up the process of finding and retrieving data by minimizing the amount of data that needs to be scanned. However, because Kafka is a distributed event streaming platform, it doesn’t use the traditional indexing techniques we learned, but implements different ways to speed the data retrieval process.
Kafka organizes data in a log-structured format, which is why it doesn’t rely on B-Trees or hash tables. But, Kafka topics are divided into partitions, and each message is assigned to the partition based on a partitioning key, which is similar to a hash of the key. So, we can see how it behaves similarly to hashing in that if messages have the same key, they will be sent to the same partition. Additionally, consumers are able to retrieve related messages quickly by accessing the relevant partition.
Another way Kafka efficiently retrieves messages is because messages within partitions are written sequentially and identified by a unique offset. The offset is similar to an index when doing an array lookup, which allows for fast sequential reads without the barrier of traditional indexing. Kafka consumers use offsets to track the progress of their reads and can access messages directly using the offsets. This is extremely advantageous for fast sequential reads and avoids the added complexity of maintaining an index. However, it limits the complexity of the queries that consumers can execute.
Security/Privacy
In class, we learned about how the data in traditional DBMS ensures privacy by encryption methods and how it can be prevented from SQL injection techniques. Although Kafka isn’t vulnerable to SQL injection attacks because it doesn’t support SQL-based querying, it does use other strategies to make sure the data is secure.
Kafka makes sure to encrypt data to allow for data confidentiality. Kafka protects data both when data is being transferred between the clients and brokers. When data is being transferred, Kafka supports Transport Layer Security (TLS), which encrypts the communication between clients and brokers. It also helps encrypt inter-broker communication within the cluster. To configure TLS, keystores and truststores for brokers and clients have to be set up, which make sure there’s trust between both communicating parties. A keystore holds the broker or client’s private key and its corresponding public certificate. The private key helps prove the identity of theKafka broker to the other party and the public certificate is shared with others to ensure secure communication. On the other hand, a truststore contains the trusted public certificates of other brokers or clients that the system will communicate with. This makes sure that the entity knows that they’re interacting with an authorized party. So, the client validates the broker’s certificate to make sure it’s communicating with the trusted Kafka broker, while the broker can optionally validate the client’s certificate to make sure the client is authorized.
Authorization, also an important concept in security and privacy, is handled by Kafka through Access Control Lists (ACLs) and Role-Based Access Control (RBAC). ACLs make sure that the specified people can read, write, or manage topics. RBAC can streamline the permission management process by grouping users or services into certain roles, such as admin, producer, or consumer. Each role has their respective and pre-defined privileges. Such authorization mechanisms make sure that the data is confidential and only accessible to authorized users.
Note: Installation is less relevant than a tutorial highlighting the main concepts as they relate to 4111.
Tutorial
Tutorial 1: A Client Streaming Data Using Kafka API
What Tutorial 1 Does:
Setting up a Kafka consumer (application), subscribing to a topic (where a producer publishes data to), and processing the information.
Step 1: Install confluent-kafka in Python
You will need to install the confluent-kafka package in your Python environment to get started.
pip install confluent-kafka
Step 2: Set up a Consumer
Once it starts running, a Kafka consumer continuously listens for new messages from the topic it subscribes to. This is different from a traditional database like PostgreSQL, which reads by executing a SELECT query to retrieve data.
from confluent_kafka import Consumer, KafkaError
# Set up Kafka consumer configuration
consumer_conf = {
'bootstrap.servers': 'YOUR_BROKER',
'group.id': 'YOUR_CONSUMER_GROUP',
'auto.offset.reset': 'earliest'
}
consumer = Consumer(consumer_conf)
Step 3: Subscribing to a Topic
The topic is where a Kafka producer publishes data to. Multiple consumers can subscribe to the same topic at the same time with no concurrency issue because the published data is divided into different partitions.
topic = 'YOUR_TOPIC'
consumer.subscribe([topic])
print("Consumer Is Listening for messages…")
Step 4: Stream Messages from the Topic and Process Them
As a simple example, this application receives an integer from every message and adds 1 to the received message. If it receives a non-integer message, the Kafka consumer will log the error and keep going. In this way, streaming is not interrupted.
try:
while True:
msg = consumer.poll(1.0) # Poll for a message, poll timeout of 1 second
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
continue
else:
print(f"Consumer error: {msg.error()}")
continue
try:
value = int(msg.value().decode('utf-8'))
result = value + 1 # Add 1 to the integer
print(f"Received: {value}, Processed: {result}")
except ValueError:
print(f"Invalid message format: {msg.value()}")
except KeyboardInterrupt:
print("Consumer aborted. Exiting...") # Consumer can stop streaming by Ctrl+C
finally:
consumer.close() # Remember to close connection to release resources
Example Message and Application Output
If there’s a producer sending a message:
42
100
23
Assuming the Kafka consumer is running, these messages will be directly sent by Kafka to the consumer, and it will process the message and output:
Consumer Is Listening for messages…
Received: 42, Processed: 43
Received: 100, Processed: 101
Received: 23, Processed: 24
Tutorial 2: Producing Streaming Data Using Kafka API
What This Tutorial Does:
Setting up a Kafka producer to publish data to a Kafka topic. This producer will send a stream of messages, which can then be consumed by Kafka consumers.
Step 1: Install confluent-kafka in Python
You will need to install the confluent-kafka package in your Python environment to get started.
pip install confluent-kafka
Step 2: Set up a Producer
A Kafka producer is used to send data to a Kafka topic. This data is then available for consumers to retrieve.
from confluent_kafka import Producer
# Set up Kafka producer configuration
producer_conf = {
'bootstrap.servers': 'YOUR_BROKER' # Replace with your Kafka broker address
}
producer = Producer(producer_conf)
# Callback to confirm delivery status
def delivery_report(err, msg):
if err:
print(f"Message delivery failed: {err}")
else:
print(f"Message delivered to {msg.topic()} [{msg.partition()}]")
Step 3: Produce Messages to a Topic
The topic is where the producer sends data. Topics can have one or more partitions, and Kafka automatically assigns each message to a partition.
topic = 'YOUR_TOPIC'
# Produce a set of messages to the topic
messages = [42, 100, 23, 'invalid', 84] # Example data to produce
for message in messages:
try:
producer.produce(topic, str(message), callback=delivery_report)
producer.flush() # Ensures the message is sent to the broker
print(f"Produced message: {message}")
except Exception as e:
print(f"Failed to produce message: {message}, Error: {e}")
Step 4: Run and Verify the Producer
Run the producer script to publish messages to the topic.
python kafka_producer.py
Example of Output If the producer sends the following messages:
42
100
23
invalid
84
The output will show:
Produced message: 42
Message delivered to YOUR_TOPIC [0]
Produced message: 100
Message delivered to YOUR_TOPIC [0]
Produced message: 23
Message delivered to YOUR_TOPIC [0]
Produced message: invalid
Message delivered to YOUR_TOPIC [0]
Produced message: 84
Message delivered to YOUR_TOPIC [0]
Alternatives/ Pros & Cons / Uniqueness of Kafka
RabbitMQ
Overview:
RabbitMQ is a traditional message broker that uses a queue-based architecture. It is designed for managing short-lived messages and supports multiple messaging protocols like AMQP, MQTT, and STOMP.
Pros:
- Simplicity: Easy-to-understand architecture for basic use cases.
- Complex Routing: Supports various exchange types (direct, topic, fanout, headers) for fine-grained message delivery.
- Management Tools: Includes high-level tools for monitoring and managing queues, consumers, and exchanges.
Cons:
- Not Designed for High Throughput: Struggles with massive data streams and high event rates in real-time analytics.
- Batch Processing: Better suited for smaller workloads, less effective for event-driven streaming.
- Scaling Limitations: Horizontal scaling is limited and can cause performance bottlenecks.
Comparison with Kafka:
- RabbitMQ is ideal for complex message routing but lacks Kafka's throughput and scalability for high-volume streaming.
- RabbitMQ queues are "point-to-point," while Kafka topics allow multiple consumers to independently process the same data stream.
Amazon Kinesis
Overview:
Amazon Kinesis is a fully managed cloud service for real-time data streaming, tightly integrated into the AWS ecosystem.
Pros:
- Managed Service: No infrastructure maintenance; AWS manages scaling, fault tolerance, and availability.
- Integration with AWS: Seamless with Lambda, S3, Redshift, etc.
- Scalability: Handles large-scale streaming with horizontal scaling.
Cons:
- Vendor Lock-In: Limited to AWS, making migration difficult.
- Cost: High throughput or extended retention can drive up costs.
- Limited Flexibility: Less customizable outside AWS environments.
Comparison with Kafka:
- Kinesis is easier for AWS users with managed service convenience, while Kafka offers control and flexibility for self-hosted or multi-cloud setups.
- Kafka's open-source model supports deployment anywhere, whereas Kinesis is AWS-restricted.
Apache Pulsar
Overview:
Apache Pulsar is an open-source distributed messaging and streaming platform combining traditional messaging features with Kafka-style stream processing.
Pros:
- Multi-Tenancy: Supports isolated configurations for different teams or applications.
- Dynamic Partitions: Topics and partitions can be created dynamically.
- Unified Messaging: Supports both streaming and queue-based messaging.
Cons:
- Smaller Ecosystem: Less mature than Kafka, with fewer libraries and integrations.
- Complexity: Additional components (e.g., BookKeeper for storage) increase the learning curve.
Comparison with Kafka:
- Pulsar excels in multi-tenancy and dynamic partitions, while Kafka has a mature ecosystem and robust community support.
- Kafka’s replication and tooling are more established for durability and integrations.
ActiveMQ
Overview:
ActiveMQ is a traditional message broker implementing the Java Message Service (JMS) API, widely used in enterprise Java applications.
Pros:
- JMS Compatibility: Seamless integration with JMS-reliant applications.
- Routing Patterns: Supports pub-sub and point-to-point routing.
- Ease of Use: Simple for small-scale or legacy use cases.
Cons:
- Limited Throughput: Not optimized for real-time event streaming.
- Scaling Challenges: Horizontal scaling is less efficient.
- Durability Trade-Offs: Persistence mechanisms aren't optimized for high-velocity data.
Comparison with Kafka:
- ActiveMQ suits legacy systems and JMS-based applications, while Kafka is better for modern, high-throughput streaming.
- Kafka offers higher scalability and better partitioning.
Redis Streams
Overview:
Redis Streams is an in-memory data structure in Redis for lightweight streaming applications.
Pros:
- Low Latency: Fast in-memory reads and writes.
- Ease of Use: Simple to set up and integrate with Redis-based applications.
- Efficient for Small Workloads: Ideal for lightweight, low-throughput scenarios.
Cons:
- Memory Constraints: Scalability limited by memory, which can be costly.
- Data Durability: Less robust than Kafka due to in-memory storage.
- Not Built for High Throughput: Struggles with parallelism and long-term storage.
Comparison with Kafka:
- Kafka is superior in durability and scalability, while Redis Streams is optimized for low-latency, short-lived workloads.
- Redis Streams is best for lightweight real-time applications; Kafka handles distributed, high-volume streaming better.
Google Pub/Sub
Overview: Google Pub/Sub is used for streaming analytics like Kafka.
Pros:
- Managed Service: Google handles scaling and maintenance. Therefore, you, the programmer, do not have to worry about handling these things.
- Automatic Scaling: Scaling works well with any workload size
- Durability: Copies of messages are stored in several different zones. This ensures a message will not be lost.
- Easy Integration: If you are using other Google Cloud services, Google Pub/Sub is ideal as this allows for easy integration with your application
Cons:
- Stuck with Google: Google Pub/Sub is tied with the Google Cloud. Therefore, moving to a different platform not associated with Google can be difficult.
- Throughput Limitations/For Smaller Applications: Google Pub/Sub may not be appropriate for an application that expects a high-throughput, low-latency workload. As a result, it is more appropriate for smaller applications.
Comparison with Kafka:
- Google Pub/Sub is better for smaller applications where the person who runs the application wants to leave more of the oversight of the data streamlining process to Google.
- Kafka is better for those who want more control over the data streamlining process of their application and if they expect a larger volume of data processing. Kafka allows for high throughput and low latency in data processing, resulting in better performance as well as providing the programmer person more control.
What Makes Kafka Unique
- Scalability: Horizontally scales with ease, handling millions of messages per second.
- Durability: Persistent message storage on disk, replicated across brokers.
- Low Latency: Processes streams in near real-time.
- High Throughput: Optimized for massive data volumes.
- Publish-Subscribe Model: Decoupled producer-consumer architecture with multiple independent consumers.
- Rich Ecosystem: Includes Kafka Connect for data integration and Kafka Streams for real-time processing.
Example of Kafka used for a Music Review Application
Kafka can be used for many applications. Here is an example of how Kafka can be used for a music review application to facilitate real-time data collection from its application’s users.
1: Notifying users if their comment was upvoted
When a user upvotes a comment in the application, the application publishes an event that is sent to a Kafka Topic. For example, we can name the Kafka Topic as user-activity
An example message might be:
{"event_type": "upvote", "user_id": 2, "comment_id": 123, "timestamp": "2024-12-07T11:00:00Z"}
A consumer such as as a notification service can subscribe to the user-activity topic to then process the event. Thus, the consumer can send a real-time notification to the user that owns the given comment that was upvoted.
2: Keeping track of current most popular songs and artists
Kafka can also be used to process real-time data about the popularity of songs and artists. As you might imagine, the number of times a song or artist is listened to increases rapidly throughout the day with millions of users. As a result, Kafka can be used to streamline this process of keeping track of the current most listened-to songs and artists in real time. For example, when a song is played, added to a playlist, or upvoted, the application publishes an event that is sent to a Kafka Topic. This Kafka Topic could be called song-analytics.
An example message might be:
{"event_type": "playlist_addition", "song_id": 602, "user_id": 1, "timestamp": "2024-12-06T11:05:12Z"}
A consumer such as a data analytics service can subscribe to the song-analytics topic to then process the event. Thus, the consumer then uses the given information from the message to calculate which songs and artists are currently most popular.
3: Updating playlists across devices in real time
When a user adds a song or an artist's collection of songs to their playlist on one device, Kafka can help update this playlist across all the user's devices. For example, when a user adds a song to their playlist, the application publishes an event that is sent to the Kafka Topic. A topic might be named update-playlist.
An example message might be:
{"playlist_id": 100, "user_id": 10, "action": "add", "song_id": 51, "timestamp": "2024-12-07T11:10:00Z"}
Each device would be a consumer that subscribes to the update-playlist topic and hence ensuring that the playlist updates on all devices.
4: Real time music recommendations
Based on a user's real-time music listening history, Kafka can be used to give the user music recommendations. For example, when a user interacts with a song such as by listening to it, adding it to their playlist, or commenting on the song's page in the application, the application sends these events to the Kafka topic. The topic might be called music-recommendations.
An example message might be:
{"user_id": 4, "song_id": 7, "action": "play", "timestamp": "2024-12-07T11:25:00Z"}
A music recommendation service can subscribe to this topic and create music recommendations for a user based on their user activity.