Everything we need to know about Ensemble Learning - vvsnikhil/ML-Blogs GitHub Wiki
What is an ensemble method?
Ensemble models in machine learning combine the decisions from multiple models to improve the overall performance.The idea behind the ensemble model is that a group of weak learners come together to form a strong learner.
The main causes of error in learning models are due to noise, bias and variance.
Ensemble methods help to minimize these factors. These methods are designed to improve the stability and the accuracy of Machine Learning algorithms.
Example: Let’s suppose that you have developed a health and fitness app. Before making it public, you wish to receive critical feedback to close down the potential loopholes, if any. You can resort to one of the following methods, read and decide which method is the best:
- You can take the opinion of your spouse or your closest friends.
- You can ask a bunch of your friends and office colleagues.
- You can launch a beta version of the app and receive feedback from the web development community and non-biased users. No brownie points for guessing the answer :D Yes, of course we will roll with the third option.
Now, pause and think what you just did. You took multiple opinions from a large enough bunch of people and then made an informed decision based on them. This is what Ensemble methods also do.
Ensemble models in machine learning combine the decisions from multiple models to improve the overall performance.

Why and when use ensemble methods?
Under what circumstances does one need to use ensemble methods? Although one would argue that there are various reasons of why, more or less thinking outside the box, here I outline some of the general reasons to use ensemble learning, some of which are:
- Large dataset: It is challenging to train a large data set using a single model, in such instances we will create a small subset of data to train different models, and eventually choose the average of all as the final prediction.
- Small data set: Similarly, a dataset is too small to train a single model in such instances a data scientist will use bootstrap methods to create random subsamples of data to train the models.
- Complex (nonlinear) data: real-world datasets are nonlinear, where a single model cannot define the class boundary clearly. This is known as under-fitting of the model. In such cases, we use more than one model to train different subsets of the data and average out the result at the end to predict distinct boundaries.
- Minimize error: main cause of error in machine learning, are due to noise, bias and variance. Ensemble methods helps to minimize these errors. The methods are designed to improve the stability and accuracy of machine learning algorithms. Combination of multiple classifiers decrease variance, especially in the case of unstable classifier and may produce a more reliable classifier than a single classifier. Let’s recap on the different types of errors
- Bias error quantifies how much on an average are the predicted values different from the actual value. A high bias error means we have an under-performing model which keeps on missing important trends.
- Variance quantifies how the prediction made on same observation differ from each other. A high variance model will over-fit on your training population and perform badly on any observation beyond training. Thus, failing to generalize model on any unseen data.
Simple Ensemble techniques
1. Max voting of the results
MODE: The mode is a statistical term that refers to the most frequently occurring number found in a set of numbers.
In this technique, multiple models are used to make predictions for each data point. The predictions by each model are considered as a separate vote. The prediction which we get from the majority of the models is used as the final prediction.
For instance: We can understand this by referring back to our health and fitness app example. I have inserted a chart below to demonstrate the ratings that the beta version of our health and fitness app got from the user community. (Consider each person as a different model)
Output= MODE=3, as majority people voted this

2. Averaging the results
In this technique, we take an average of predictions from all the models and use it to make the final prediction.
AVERAGE= sum(Rating * Number of people) / Total number of people= (1 * 5)+(2 * 13)+(3 * 45)+(4 * 7)+(5 * 2)/72 = 2.833 =Rounded to nearest integer would be 3
3. Weighted averaging the results
This is an extension of the averaging method. All models are assigned different weights defining the importance of each model for prediction. For instance, if about 25 of people responded are professional app developers, while others have no prior experience in this field, then the answers by these 25 people are given more importance as compared to the other people.
For example: For simplicity, I am trimming down the scale of the example to 5 people
WEIGHTED AVERAGE= (0.3 * 3)+(0.3 * 2)+(0.3 * 2)+(0.15 * 4)+(0.15 * 3) =3.15 = rounded to nearest integer would give us 3.
Advanced Ensemble techniques
- Bagging to decrease the model’s variance;
- Boosting to decreasing the model’s bias, and;
- Stacking to increasing the predictive force of the classifier.
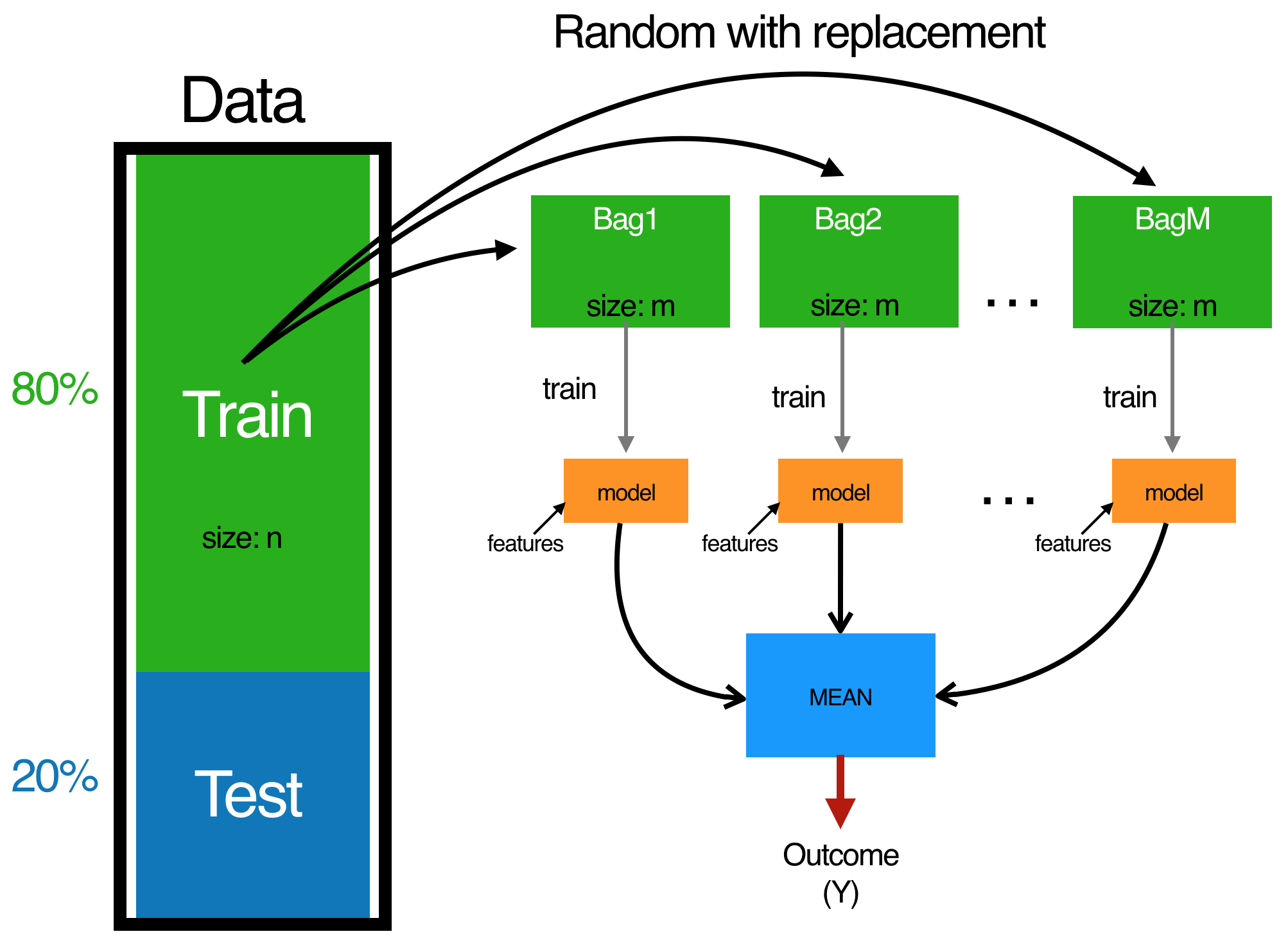
1. Bagging The idea behind bagging is combining the results of multiple models to get a generalized result. If you create all the models on the same set of data and combine it then there is a high chance that these models will give the same result since they are getting the same input. One of the techniques to solve this problem is bootstrapping.
Bootstrapping is a sampling technique in which we create subsets of observations from the original data set, with replacement. The size of the subsets is the same as the size of the original set.
Bagging (or Bootstrap Aggregating) technique uses these subsets (bags) to get a fair idea of the distribution (complete set). The size of subsets created for bagging may be less than the original set.
- Multiple subsets are created from the original data set, selecting observations with replacement.
- A base model (weak model) is created on each of these subsets.
- The models run in parallel and are independent of each other.
- Finally, results of these multiple models are combined using average or majority voting.
2. Boosting Boosting is a sequential process,where the first algorithm is trained on the entire data set and the subsequent algorithms are built by fitting the residuals of the first algorithm, thus giving higher weight to those observations that were poorly predicted by the previous model.
Boosting in general decreases the bias error and builds strong predictive models. Boosting has shown better predictive accuracy than bagging, but it also tends to over-fit the training data as well.So, parameter tuning is a crucial part of boosting algorithms to make them avoid over fitting.

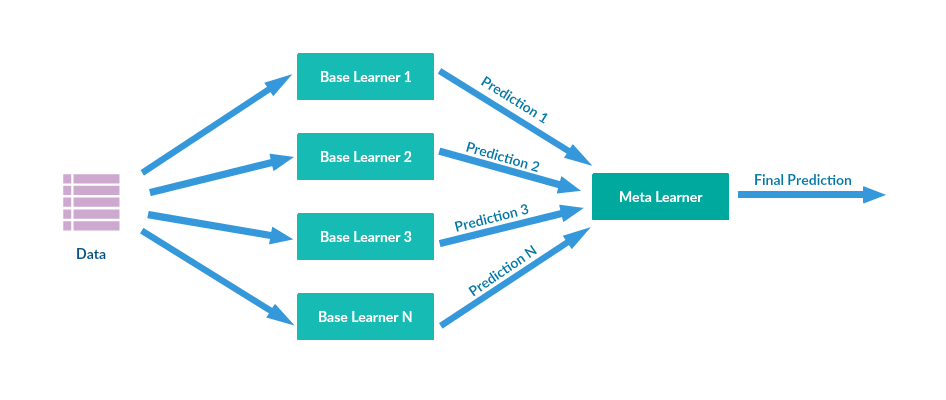
3. Stacking Stacking is another ensemble model, where a new model is trained from the combined predictions of two (or more) previous model via a meta-classifier or a meta-regressor. The base level models are trained based on a complete training set, then the meta-model is trained on the outputs of the base level model as features.
The base level often consists of different learning algorithms and therefore stacking ensembles are often heterogeneous.
Advantages/Benefits of ensemble methods
- More accurate prediction results- The ensemble of models will give better performance on the test case scenarios (unseen data) as compared to the individual models in most of the cases
- Stable and more robust model- The aggregate result of multiple models is always less noisy than the individual models. This leads to model stability and robustness.
- Ensemble models can be used to capture the linear as well as the non-linear relationships in the data.This can be accomplished by using 2 different models and forming an ensemble of the two.
Disadvantages of ensemble methods
- Reduction in model interpret-ability- Using ensemble methods reduces the model interpret-ability due to increased complexity and makes it very difficult to draw any crucial business insights at the end.
- Computation and design time is high- It is not good for real time applications.