HTTP 프로토콜 - vvonha/NaverAPI GitHub Wiki

HTTP 프로토콜이란?
HTTP(Hypertext Transfer Protocol)는 인터넷상에서 데이터를 주고 받기 위한 서버/클라이언트 모델을 따르는 프로토콜이다. 애플리케이션 레벨의 프로토콜로 TCP/IP위에서 작동한다. HTTP는 어떤 종류의 데이터든지 전송할 수 있도록 설계되어 있다. HTTP로 보낼 수 있는 데이터는 HTML문서, 이미지, 동영상, 오디오, 텍스트 문서 등 여러종류가 있다. 하이퍼텍스트 기반으로(Hypertext) 데이터를 전송하겠다(Transfer) = 링크기반으로 데이터에 접속하겠다는 의미이다.
작동방식
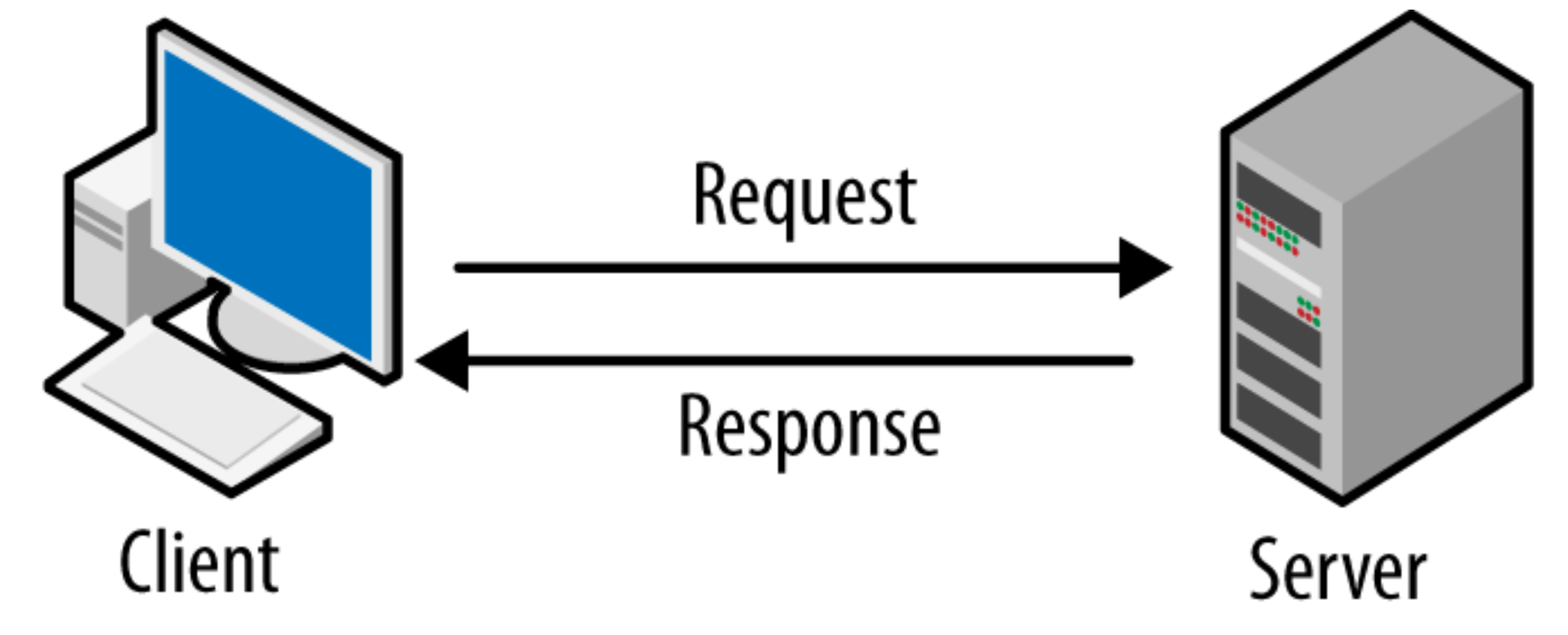
HTTP는 서버/클라이언트 모델을 따른다. 클라이언트에서 요청(request)를 보내면 서버는 요청을 처리해서 응답(response)한다.
클라이언트 :
서버에 요청하는 클라이언트 소프트웨어(IE, Chrome, Firefox, Safari ...)가 설치된 컴퓨터를 이용한다. 클라이언트는 URI를 이용해서 서버에 접속하고, 데이터를 요청할 수 있다.
서버 :
클라이언트의 요청을 받아서, 요청을 해석하고 응답을 하는 소프트웨어가 설치된 컴퓨터(Apache, nginx, IIS, lighttpd) 등이 서버 소프트웨어다.
 cf. 웹서버는 보통 표준포트인 80번 포트로 서비스한다.
cf. 웹서버는 보통 표준포트인 80번 포트로 서비스한다.
Connectionless & Stateless
HTTP는 Connectionless 방식으로 작동한다. 서버에 연결하고, 요청해서 응답을 받으면 연결을 끊어버린다. 기본적으로는 자원 하나에 대해서 하나의 연결을 만든다. 이런 작동방식은 각각 아래의 장점과 단점을 가진다
장점
불특정 다수를 대상으로 하는 서비스에 적합한 방식이다. 수십만명이 웹 서비스를 사용하더라도 접속유지는 최소한으로 할 수 있기 때문에, 더 많은 유저의 요청을 처리할 수 있다.
단점
연결을 끊어버리기 때문에, 클라이언트의 이전 상태를 알 수가 없다. 이러한 HTTP의 특징을 stateless라고 하는데, Connectionless 로 부터 파생되는 특징이라고 할 수 있다. 클라이언트의 이전 상태 정보를 알 수 없게 되면, 웹 서비스를 하는데 당장에 문제가 생긴다. 클라이언트가 과거에 로그인을 성공하더라도 로그 정보를 유지할 수가 없다. HTTP는 cookie를 이용해서 이 문제를 해결하고 있다.
Cookie는 클라이언트와 서버의 상태 정보를 담고 있는 정보의 조각들이다.
로그인을 예로 들자면, 클라이언트가 로그인에 성공하면, 서버는 로그인 정보를 자신의 데이터베이스에 저장하고 동일한 값을 cookie형태로 클라이언트에 보낸다.
첫 요청 시
클라이언트 로그인 성공 then 서버 로그인 정보를 자신의 DB에 저장 (서버는 cookie를 키로 갖는 값을 데이터베이스에 저장하는 방식으로 "세션"을 유지한다) and then return 쿠키 to 클라이언트 -> 이와 같은 형태가 된다. 클라이언트는 다음 번 요청때 cookie를 서버에 보내는데, 서버는 cookie 값으로 자신의 데이터베이스를 조회해서 로그인 여부를 확인할 수 있다.
두번쨰 요청 시
클라이언트 request(cookie) to server then 서버는 자신의 DB 조회 and then 로그인 여부 확인
URI(Uniform Resource Identifiers)
클라이언트 소프트웨어(IE, Chrome, Firefox, Safari ...)는 URI를 이용하여 자원의 위치를 찾는다. URI는 HTTP와는 독립된 다른 체계다. HTTP는 전송 프로토콜이고, URI는 자원의 위치를 알려주기 위한 프로토콜이다.
Uniform Resource Identifiers 의 줄임로, World Wide Web 상에서 접근하고자 하는 자원의 위치를 나타내기 위해서 사용한다. 자원은 HTML문서, 이미지, 동영상, 오디오, 텍스트 문서 등 모든 것이 될 수 있다. 웹페이지의 위치를 나타내기 위해서 사용하는 https://www.dcinside.com/index.php 등이 URI의 예다.
URI 분석 방법 Tip
https://www.naver.com/news.html 를 분해하여 분석해보자.
https : 자원에 접근하기 위해서 https 프로토콜을 사용한다.
www.naver.com : 자원의 인터넷 상에서의 위치는 www.naver.com이다.
도메인은 ip 주소로 변환되므로, ip 주소로 서버의 위치를 찾을 수 있다.
index.html : 요청할 자원의 이름이다.
이렇게 "프로토콜", "위치", "자원명"으로 어디에 있던지 자원에 접근할 수 있다.
https://www.naver.com/news.html이라고 하면 https 프로토콜을 사용할 것이고,
도메인(특정 IP 주소에 부여된 이름)는 이것이고, 그 IP 주소에 있는 news.html를
요청한다는 것으로 정리할 수 있다.
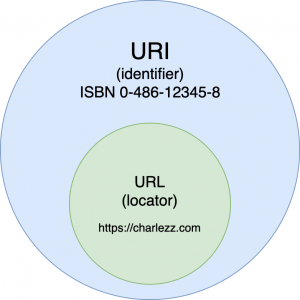
URI와 URL의 혼동 방지 Tip
URI란,
URI는 특정 리소스를 식별하는 통합 자원 식별자(Uniform Resource Identifier)를 의미한다. 웹 기술에서 사용하는 논리적 또는 물리적 리소스를 식별하는 고유한 문자열 Sequence이다.
URL란,
URL은 흔히 "웹 주소"라고도 하며, 컴퓨터 네트워크 상에서 리소스가 어디 있는지 알려주기 위한 규약이다. URI의 Subset이다.