04일차 [ Overfitting ] - votus777/AI_study GitHub Wiki
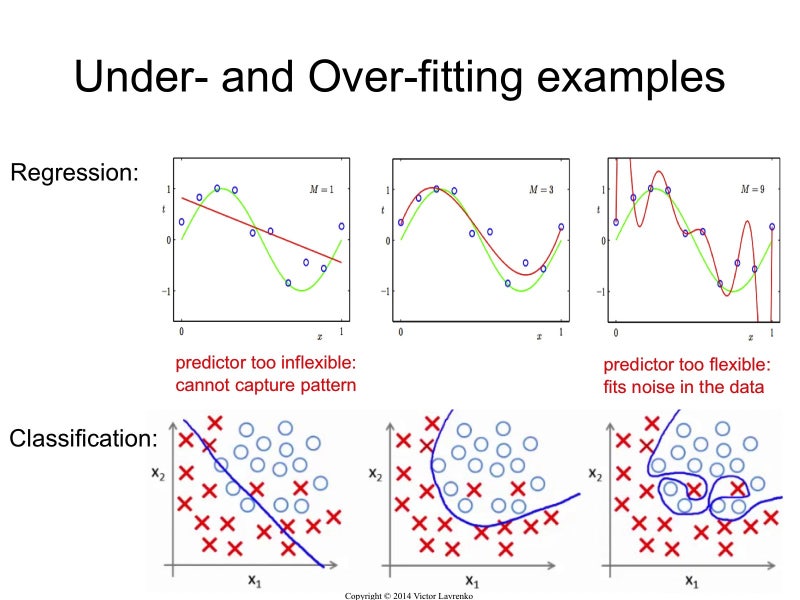
과소적합 (Underfitting)
높은 편향 (High Bias)
잘못된 가정을 했거나, 데이터 간의 상관관계를 충분히 밝혀내지 못했거나,
모델이 너무 단순하거나, 규제가 너무 많거나, 그냥 충분히 오래 학습하지 않았을 때 발생
-> 충분한 신호 미포함 -> 과소적합 (under-fitting)
상수 함수 같은 경우는 한 가지 표본을 뽑아서 모델을 만들었을 때 실제값가 동떨어진 모습이겠지만
임의의 두 모델을 비교해보면 평균이 비슷하기 때문에 두 모델은 서로 비슷하게 만들어질 것이다.
이는 편향은 크지만 분산은 작다는 뜻이다.
분류 모델에서
모양이 둥글다고 과일이든 달이든 죄다 공으로 판단해버리는 상황
중요한 신호들을 놓치고 지나치게 편중된 편향을 가짐
이렇게 프리패스 하다보니 분산이 작아 결과값들은 비슷하게 모여있지만, 실제값에서는 떨어져있음
처음보는 애들인데 얘가 너무 자신있게 분류하는 것 같다? 그럼 의심을 해보아야 함
training set에서 적절한 패턴 학습 필요
과대적합 (Overfitting)
높은 분산 (High Variance) //
모델에 내재된 변동 때문에 발생 -> 많은 잡음 포함 -> 과대적합 (over-fitting)
모델 성능이 증가하다가 어느 epoch 이상 넘어가면 다시 감소하는 현상
쉽게 말해 학습셋에 너무 과체적화 된 것
9차 함수 같은 경우는 모든 학습 데이터를 완벽하게 통화하지만
임의의 두 학습 데이터에서 만들어진 모델은 서로 엄청 다를 것이다.
이는 편향은 작지만 분산은 크다고 볼 수 있다.
위와 반대로
공을 학습한다고 가져온게 공 데이터 100만개임
공만 주구장창 보다보니 이제 이것에 관해서는 박사급이 됨. 탄성계수, 사이즈, 무게 등등
문제는 계속 이런 식이다 보니 엄청나게 다양한 조건들을 만족해야만 하는 모델이 만들어졌다.
이렇게 각 데이터 포인터에 민감해져서 새로운 데이터를 잘 받아들이지 못하게 된다.
세팍타크로 공을 보면 자기 기준에 바라보던 공 하고는 둥근 것 빼고는 뭔가 잘 안맞으니까 바로 빠꾸먹이는거
즉, 테스트 세트에서 일반화 되지 못하는 패턴을 훈련 세트에서 학습함.
이를 과하게 학습되었다 해서 over-fitting이라 함.
무시해도 될 만한 정보(잡음) 까지 모두 포함하게 되서 일어난 일
실제값에는 가깝지만 잡음이 많이 껴있어 결과값이 분산되어 나타남.
이를 방지하기 위해 early stopping을 한다.
모델의 규모를 축소, 학습 가능한 파라미터의 수를 줄이거나
혹은 많은 데이터를 가지고 있으면 일반화 성능이 좋아져서 이런 상황이 나타나지 않음
만약 데이터가 충분하지 못하다면 regularization 기법 같이 모델에 규제나 제약을 부과할 수도 있다.
가중치 규제, dropout 기법 등이 있다.. 고 한다
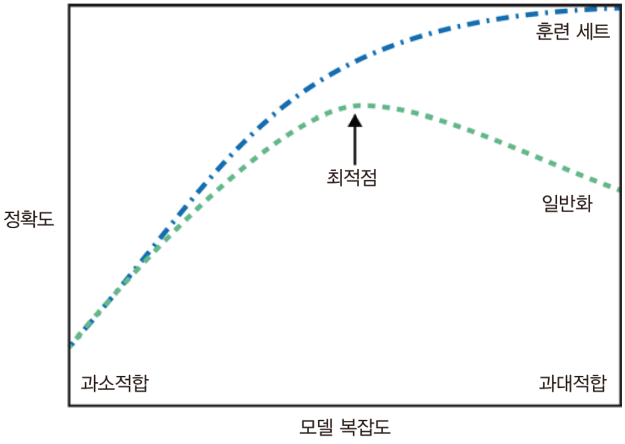
over-fitting 과 under-fitting은 trade off 관계라서
어느 하나를 잡으면 다시 다른 하나가 튀어나오는 식이라
둘 사이의 딜레마에서 조절을 잘해야 함. 노가다 밖에 답이 없다
모델의 파라미터는 곧 모델의 기억 용량과도 같다.
파라미터가 너무 많으면 훈련 셋에서 너무 많은 신호를 들고가게 되고
혹 너무 작으면 적절한 신호를 가지지 못해서 패턴 학습 하기 어려움
조금만 생각해보면 이게 꼭 들어맞는 설명은 아니지만 일단 이해하기 쉽게만 기록
배고프다
reference : https://www.tensorflow.org/tutorials/keras/overfit_and_underfit?hl=ko