W Net Reproduction - valorcurse/W-Net-Pytorch GitHub Wiki
Authors: Nick Dekker [email protected] TU Delft, student #4965388,
Marcelo Dias Avelino [email protected] TU Delft, student #4981669
Date: 16-04-2021
Introduction
Like the repo this was forked from, this is an implementation of the W-Net paper [6]. Our final source code was forked and altered and not written by the same author as the paper. Our goal is to reproduce the paper and its results (though, without postprocessing). We also perform some ablation studies. This documentation offers a way to reproduce our results and shows and explains our findings.
The W-Net Model in Short
W-Net [6] aims for unsupervised image segmentation, a very popular problem which has been the subject of research for a long time. There are a few important studies that are relevant to, in particular U-net [7] and normalized-cut (n-cut) [8]. U-Net is a model that is trained with labeled data and does supervised learning. W-Net does not require labeled data and learns without supervision. In this section, we outline the paper's idea.
W-Net Architecture
To understand the behaviour of the W-Net model, we look at the idea and the way a W-Net model is constructed. Its architecture consists of two consecutive U-Net Architectures. With a loss function over the first. The U-Net architecture is an autoencoder that does contractions with an expansion directly after. The contraction is a forward step in the architecture that convolutes the images and does max pooling several times. This extracts the image features, which are used to create segmentation and for reconstruction of the original image. All layers are shown in Figure 1.

Figure 1: W-Net architechture, source: W-Net paper.
Our Setup and Code Replication
Reproduction Environment
The W-Net paper did not publish the code they work with directly. Therefore, the community is left to reproduce the results by implementing their own W-Net. The actual architecture stemming from the U-Net concept, has a simple implementation and is based on deep learning standards. Mostly existing of convolutions and pooling, the structure from figure 1 can be implemented without much trouble. Reconstruction loss is also fairly straight forward, our implementation uses the MSE loss with sum reduction. The domain of our learning setup is depicted in Figure 2.

Figure 2: The idea of the W-NET in our circumstances.
The following hyperparameters were used in this reproduction:
- Image size: 224x224
- Batch size: 5
- Classes (K): 20
- Iterations: 100,000
We tried to stay as close to the setup of the paper as possible, but we had to make some choices due to lack of resources (mostly memory problems). We could use at most a batch size of 5, in comparison to the paper's batch size of 10. To try and compensate that, we double the number of iterations from the paper's 50k to 100k. The paper never specifies how many classes (the variable K) they used for training, but by analyzing the n-cut loss from the paper (shown below) and through experimenting with different Ks, we could deduce they used K=20.

Figure 3: The two losses shown in the paper [8]
Mode Collapse
One of the training runs was done with a dropout rate of 0.1, while the paper has used 0.65. This yielded a bad outcome very quickly. As Figure 4 shows, each image segmentation is the same. This is sometimes referred to as mode collapse. We did not see this behaviour after using 0.65 as the dropout rate.

Figure 4: An intermediary result from our training. The first row has training images, the second images shows the generated segmentation.
Ablation: soft-n-cut Implementation Variation
Ideally, a normalized cut (n-cut) would be used to segment the image and use this as a backbone for the segmentations. That is, the segmentation loss is calculated against the value of the n-cut. This n-cut value is a strong condition in the W-Net model which makes sure the segmentation is not overpowered by the reconstruction loss (as seen in Figure 5) and as such, will be ineffective. In the code another problem arises, also discussed in the paper; the n-cut formula is not differentiable. This gives rise to the need for soft-n-cut, a differentiable version of n-cut.
Figure 5: The difference between using soft n-cut loss and not using soft n-cut loss [6]
Due to the difficulty and the differences with which soft-n-cut can be implemented, there will be many differences in training and evaluating the results. Additionally, the n-cut calculation is very heavy and will impact learning time strongly.
Instead of implementing the soft-n-cut loss as specified in the paper, we used a slight variation of the soft-n-cut used by a different W-Net reproduction repository 1(https://github.com/gr-b/W-Net-Pytorch/blob/master/soft_n_cut_loss.py). The variation compares every pixel in each class to the class average, instead of to every other pixel. This saves a lot of memory and computation time, which are in dire need when running a large architecture like W-Net on a home computer. From our preliminary tests, we did not find that there was a big difference in convergence speed between both. Since we could not train the original soft-n-cut in a reasonable amount of time, we cannot compare both properly.
Ablation: Training More and Training on Less
We trained the model on the VOC2012 dataset, just like in the paper. It's a dataset consisting of 17,025 training images (which differs from the paper, which mentions the dataset consisting of 11,530 images, but perhaps the dataset was updated since then) and 100 validation images. Of course, not all images are created equal. Some are larges, other are smaller. Some are rectangular, some square. For this reason, resizing is required when training W-Net. It expects 224*224 images. This will affect the aspect ratio of some images, but shouldn't affect the quality of the segmentation.
We have trained the model on a Nvidia GeForce GTX 1070. Training the final model took around 3 days. Due to time constraints we chose not to use any type of data augmentation, since we already struggled to train the model on the original dataset, adding more data wouldn't have provided any benefits.
The following gif is a progression of our training. (Mind that there was a change of colormap halfway through the training because we didn't feel like the colormap we chose originally represented the segmentation correctly and due to time constraints we weren't able to retrain the whole model using one colormap)
Gif 1: Progression of training watch on external site
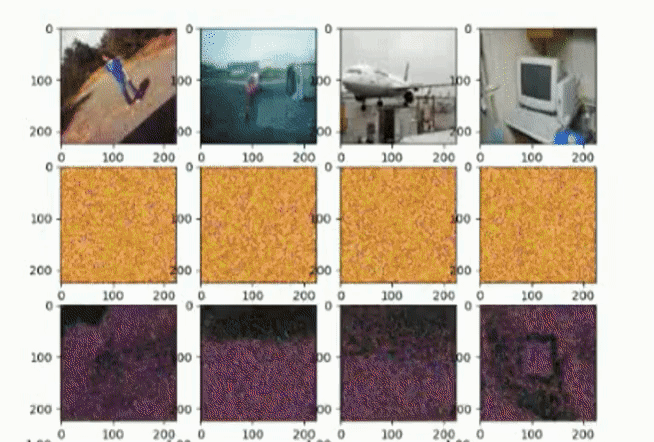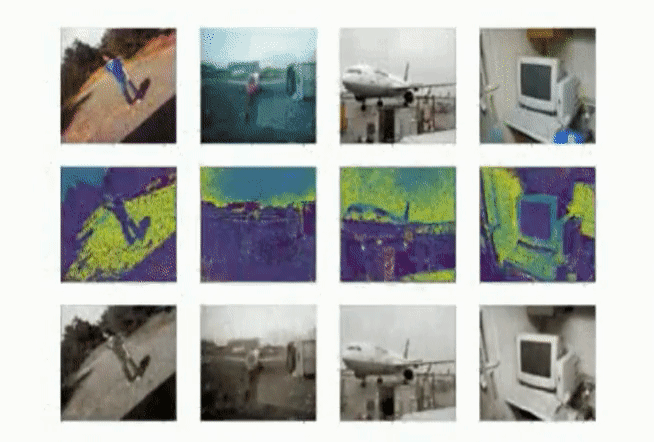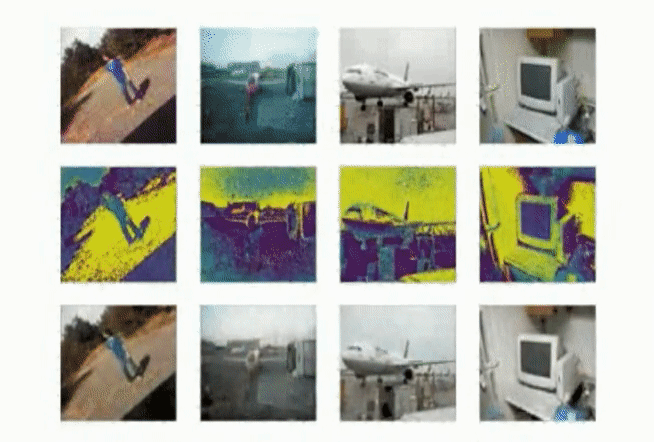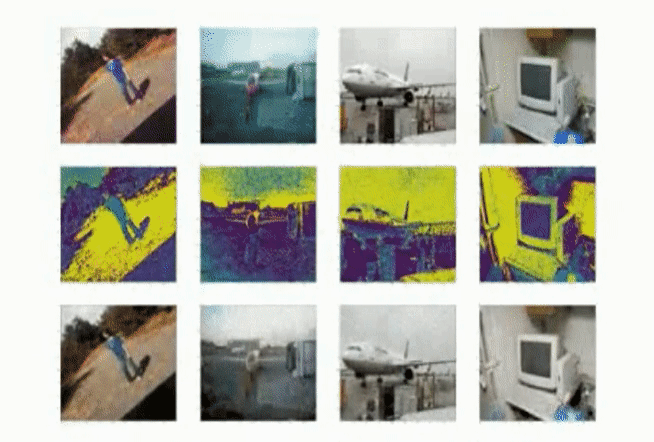{kind=link}
Things to notice in the gif:
- The noisiness of the segmentations are due to the high dropout rate (0.65). When running the model in evaluation mode it provides smooth surfaces.
- The reconstruction of the image only reconstructed color towards the end of the training process.
Evaluation
Using the model trained on the VOC2012 [5] dataset, we evaluated its performance visually on multiple datasets. The model did not, of course, perform perfectly everywhere. Although we believe this is more due to our training process then the merits of the paper.
Below we will show you a couple of cherry-picked segmentations to show the potential of the algorithm, since due to time-constraints we cannot determine whether the poorer performance in some images is due to the algorithm or our specific reproduction.
Evaluating on BSDS500 [2]
The dataset used by the paper for its evaluation. The dataset consists of 500 images with a wide range of subjects.
Figure 6: Our results on the BSDS dataset.
In these high-contrast images, the model seems to perform almost perfectly even without any post-processing.
Evaluating on CityScapes [3]
CityScapes provides a large dataset of stereoimages from urban scenery.
Figure 7: Our results on the CityScape dataset.
In these urban images, the model seems to be very good at segmenting roads and their markings. This is perhaps to be expected since there is a high contrast difference between the black roads and white markings. Once it gets to the minute details of the building, it starts to falter.
Evaluating on Global Wheat Detection [4]
The Global Wheat Detection challenge on Kraggle provides a large dataset of aerial pictures of wheat fields, where the correct detection of the wheat density can be used by a farmer to make management decisions.
Figure 8: Our results on the wheat dataset.
Whe applying this model which was trained in a very general dataset to segment such specialized images, it seems to still be able to do quite a good job at differentiating between foliage and the wheat heads.
Evaluating on Old School Runescape
As a quick application of the model on a real-time application, we decide to try how well it would perform segmenting a virtual world like the one of Runescape.
Gif 2: Real-time segmentation of Old School Runescape
Although far from perfect and mostly due to the model being trained for 224x224 images (which loses a lot of information), the application was able to segment the video stream in real-time and, depending on the location in-game, provide promising segmentations.
Combining Both Ablations to Aim for High Scoring Benchmarks
The trained models of the final model, trained on the VOC2012 dataset, need to be evaluated to see the difference with the paper. By comparing ground truth images with the output of our learned model (the prediction), we find out how similar they are. We tested with BSD500 (with a metric) and some others without a metric for lack of compatible ground truth images. The BSD500 test set has ground truth images available, where 5 images have been segmented by human workers. Of these images, the Intersection over Union (IoU) is used. This methods is very similar to Segmentent Coverage and will compare the best matching segmentations of the prediction and the ground truth. The results of this method was: mean IoU: 0.3296. This does not come close to the numbers in the paper (Figure 9). We suspect this is due to the training time. As the loss of the model did not compare well against the paper.

Figure 9: Results of the W-Net and competing segmenting methods [6].
Conclusion
The W-Net paper purports to be one of the best (unsupervised) segmentation methods (Figure 9). Our results do not support this claim as of right now, when looking at the segmentation score (SC). However, visually, the image seem to segment well. The BSDS500 ground truth may be based on certain segmentations, for which the algorithms in the score table are optimised and therefore produce a skewed image.
For now, we consider the paper not fully reproduced, we are skeptical about the performance outside the paper's testing domain. It is also unclear which training was performed by the authors, based on information such as reconstruction loss, which we could not reproduce. Our method may have to be trained for more epochs, as there is evidence that it segments well in some scenarios. We welcome further research, based on our approach.
References
[1] W-Net Pytorch, (2021), GitHub repository, https://github.com/gr-b/W-Net-Pytorch/blob/master/soft_n_cut_loss.py
[2] Contour Detection and Hierarchical Image Segmentation , P. Arbelaez, M. Maire, C. Fowlkes and J. Malik. IEEE TPAMI, Vol. 33, No. 5, pp. 898-916, May 2011.
[3] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The Cityscapes Dataset for Semantic Urban Scene Understanding,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.* https://www.cityscapes-dataset.com/
[4] David, Etienne, et al. "Global Wheat Head Detection (GWHD) dataset: a large and diverse dataset of high-resolution RGB-labelled images to develop and benchmark wheat head detection methods." Plant Phenomics 2020 (2020).
[5] The PASCAL Visual Object Classes (VOC) Challenge, Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J. and Zisserman, A., International Journal of Computer Vision, 88(2), 303-338, 2010_
[6] Xia, Xide, and Brian Kulis. "W-net: A deep model for fully unsupervised image segmentation." arXiv preprint arXiv:1711.08506 (2017).
[7] U-Net: Convolutional Networks for Biomedical Image Segmentation. Ronneberger, O. Fischer, P, Brox T (2015)
[8] Normalized cuts and image segmentation. Shi, J. Malik, J (2000)