4. Case Study Sunlight in Austin - upalr/Python-camp GitHub Wiki
1 Reading and cleaning the data
1.1 Case study
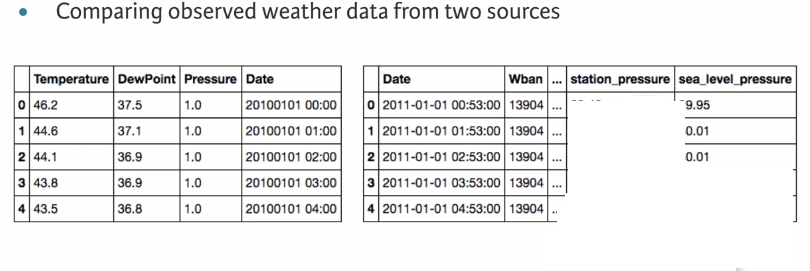
1.2 Climate normals of Austin , TX from 1981-2010
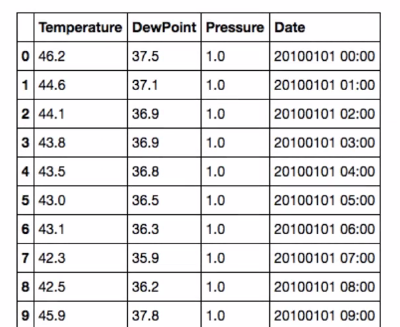
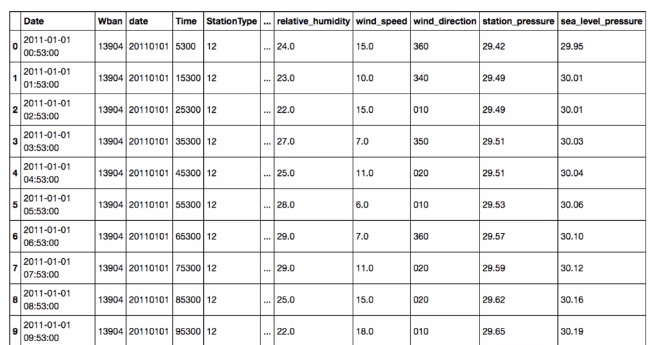
1.3 Weather data of Austin, TXfrom 2011
1.4 Reminder : read_csv()

Example 1:Reading in a data file, pd.read_csv('data.csv', header=None)
Find the header=none result.
Now that you have identified the method to use to read the data, let's try to read one file. The problem with real data such as this is that the files are almost never formatted in a convenient way. In this exercise, there are several problems to overcome in reading the file. First, there is no header, and thus the columns don't have labels. There is also no obvious index column, since none of the data columns contain a full date or time.
Your job is to read the file into a DataFrame using the default arguments. After inspecting it, you will re-read the file specifying that there are no headers supplied.
The CSV file has been provided for you as 'data.csv'.
INSTRUCTIONS:
- Import
pandasaspd. - Read the file
'data.csv'into a DataFrame calleddf. - Print the output of
df.head(). This has been done for you. Notice the formatting problems indf. - Re-read the data using specifying the keyword argument
header=Noneand assign it todf_headers. - Print the output of
df_headers.head(). This has already been done for you. Hit 'Submit Answer' and see how this resolves the formatting issues.
# Import pandas
import pandas as pd
# Read in the data file: df
df = pd.read_csv('data.csv')
# Print the output of df.head()
print(df.head())
# Read in the data file with header=None: df_headers
df_headers = pd.read_csv('data.csv', header=None)
# Print the output of df_headers.head()
print(df_headers.head())
Example 2 : Cleaning and tidying datetime data
In order to use the full power of pandas time series, you must construct a DatetimeIndex. To do so, it is necessary to clean and transform the date and time columns.
The DataFrame df_dropped you created in the last exercise is provided for you and pandas has been imported as pd.
Your job is to clean up the date and Time columns and combine them into a datetime collection to be used as the Index.
INSTRUCTIONS
- Convert the
'date'column to a string with.astype(str)and assign to df_dropped['date']. - Add leading zeros to the
'Time'column. This has been done for you. - Concatenate the new
'date'and'Time'columns together. Assign todate_string. - Convert the
date_stringSeries to datetime values withpd.to_datetime(). Specify theformatparameter. - Set the index of the
df_droppedDataFrame to to bedate_times. Assign the result todf_clean.
# Convert the date column to string: df_dropped['date']
df_dropped['date'] = df_dropped['date'].astype(str)
# Pad leading zeros to the Time column: df_dropped['Time']
df_dropped['Time'] = df_dropped['Time'].apply(lambda x:'{:0>4}'.format(x))
# Concatenate the new date and Time columns: date_string
date_string = df_dropped['date'] + df_dropped['Time']
# Convert the date_string Series to datetime: date_times
date_times = pd.to_datetime(date_string, format='%Y%m%d%H%M')
# Set the index to be the new date_times container: df_clean
df_clean = df_dropped.set_index(date_times)
# Print the output of df_clean.head()
print(df_clean.head())
Cleaning and tidying datetime data
Example 3: Cleaning the numeric columns
The numeric columns contain missing values labeled as 'M'. In this exercise, your job is to transform these columns such that they contain only numeric values and interpret missing data as NaN.
The pandas function pd.to_numeric() is ideal for this purpose: It converts a Series of values to floating-point values. Furthermore, by specifying the keyword argument errors='coerce', you can force strings like 'M' to be interpreted as NaN.
A DataFrame df_clean is provided for you at the start of the exercise, and as usual, pandas has been imported as pd.
INSTRUCTIONS
- Print the
'dry_bulb_faren'temperature between 8 AM and 9 AM on June 20, 2011. - Convert the
'dry_bulb_faren'column to numeric values withpd.to_numeric(). Specifyerrors='coerce'. - Print the transformed
dry_bulb_farentemperature between 8 AM and 9 AM on June 20, 2011. - Convert the
'wind_speed'and'dew_point_faren'columns to numeric values withpd.to_numeric(). Again, specifyerrors='coerce'.
# Print the dry_bulb_faren temperature between 8 AM and 9 AM on June 20, 2011
print(df_clean.loc['2011-06-20 08:00:00' : '2011-06-20 09:00:00', 'dry_bulb_faren'])
# Convert the dry_bulb_faren column to numeric values: df_clean['dry_bulb_faren']
df_clean['dry_bulb_faren'] = pd.to_numeric(df_clean['dry_bulb_faren'], errors='coerce')
# Print the transformed dry_bulb_faren temperature between 8 AM and 9 AM on June 20, 2011
print(df_clean.loc['2011-06-20 08:00:00' : '2011-06-20 09:00:00', 'dry_bulb_faren'])
# Convert the wind_speed and dew_point_faren columns to numeric values
df_clean['wind_speed'] = pd.to_numeric(df_clean['wind_speed'], errors='coerce')
df_clean['dew_point_faren'] = pd.to_numeric(df_clean['dew_point_faren'], errors='coerce')
2 Statistical exploratory data analysis
2.1 Reminder: time serises
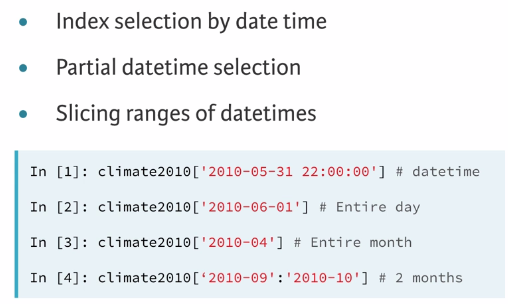
2.2 Reminder: statistics methods

Example 4: Signal variance
You're now ready to compare the 2011 weather data with the 30-year normals reported in 2010. You can ask questions such as, on average, how much hotter was every day in 2011 than expected from the 30-year average?
The DataFrames df_clean and df_climate from previous exercises are available in the workspace.
Your job is to first resample df_clean and df_climate by day and aggregate the mean temperatures. You will then extract the temperature related columns from each - 'dry_bulb_faren' in df_clean, and 'Temperature' in df_climate - as NumPy arrays and compute the difference.
Notice that the indexes of df_clean and df_climate are not aligned - df_clean has dates in 2011, while df_climate has dates in 2010. This is why you extract the temperature columns as NumPy arrays. An alternative approach is to use the pandas .reset_index() method to make sure the Series align properly. You will practice this approach as well.
INSTRUCTIONS:
- Downsample
df_cleanwith daily frequency and aggregate by the mean. Store the result asdaily_mean_2011. - Extract the
'dry_bulb_faren'column fromdaily_mean_2011as a NumPy array using.values. Store the result asdaily_temp_2011. Note:.valuesis an attribute, not a method, so you don't have to use(). - Downsample
df_climatewith daily frequency and aggregate by the mean. Store the result asdaily_climate. - Extract the
'Temperature'column fromdaily_climateusing the.reset_index()method. To do this, first reset the index ofdaily_climate, and then use bracket slicing to access'Temperature'. Store the result asdaily_temp_climate.
# Downsample df_clean by day and aggregate by mean: daily_mean_2011
daily_mean_2011 = df_clean.resample('D').mean()
# Extract the dry_bulb_faren column from daily_mean_2011 using .values: daily_temp_2011
daily_temp_2011 = daily_mean_2011['dry_bulb_faren'].values
# Downsample df_climate by day and aggregate by mean: daily_climate
daily_climate = df_climate.resample('D').mean()
# Extract the Temperature column from daily_climate using .reset_index(): daily_temp_climate
daily_temp_climate = daily_climate.reset_index()['Temperature']
# Compute the difference between the two arrays and print the mean difference
difference = daily_temp_2011 - daily_temp_climate
print(difference.mean())
Example 5: Sunny or cloudy
On average, how much hotter is it when the sun is shining? In this exercise, you will compare temperatures on sunny days against temperatures on overcast days.
Your job is to use Boolean selection to filter out sunny and overcast days, and then compute the difference of the mean daily maximum temperatures between each type of day.
The DataFrame df_clean from previous exercises has been provided for you. The column 'sky_condition' provides information about whether the day was sunny ('CLR') or overcast ('OVC').
INSTRUCTIONS:
- Use
.loc[]to select sunny days and assign tosunny. If'sky_condition'equals'CLR', then the day is sunny. - Use
.loc[]to select overcast days and assign toovercast. If'sky_condition'contains'OVC', then the day is overcast. - Resample
sunnyandovercastand aggregate by the maximum (.max()) daily ('D') temperature. Assign tosunny_daily_maxandovercast_daily_max. - Print the difference between the mean of
sunny_daily_maxandovercast_daily_max. This has already been done for you, so click 'Submit Answer' to view the result!
# Select days that are sunny: sunny
sunny = df_clean.loc[df_clean['sky_condition'] == 'CLR']
# Select days that are overcast: overcast
overcast = df_clean.loc[df_clean['sky_condition'].str.contains('OVC')]
# Resample sunny and overcast, aggregating by maximum daily temperature
sunny_daily_max = sunny.resample('D').max()
overcast_daily_max = overcast.resample('D').max()
# Print the difference between the mean of sunny_daily_max and overcast_daily_max
print(sunny_daily_max.mean() - overcast_daily_max.mean())
3 Visual exploratory data analysis
3.1 Line plots in pandas

3.2 Histograms in pandas

3.3 Box plots in pandas

3.4 Subplots in pandas

Example 6: Weekly average temperature and visibility
Is there a correlation between temperature and visibility? Let's find out.
In this exercise, your job is to plot the weekly average temperature and visibility as subplots. To do this, you need to first select the appropriate columns and then resample by week, aggregating the mean.
In addition to creating the subplots, you will compute the Pearson correlation coefficient using .corr(). The Pearson correlation coefficient, known also as Pearson's r, ranges from -1 (indicating total negative linear correlation) to 1 (indicating total positive linear correlation). A value close to 1 here would indicate that there is a strong correlation between temperature and visibility.
The DataFrame df_clean has been pre-loaded for you.
INSTRUCTIONS:
- Import
matplotlib.pyplotasplt. - Select the
'visibility'and'dry_bulb_faren'columns and resample them by week, aggregating the mean. Assign the result toweekly_mean. - Print the output of
weekly_mean.corr(). - Plot the
weekly_meandataframe with.plot(), specifyingsubplots=True.
Weekly average temperature and visibility
# Import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
# Select the visibility and dry_bulb_faren columns and resample them: weekly_mean
weekly_mean = df_clean.loc[: , ['visibility', 'dry_bulb_faren']].resample('W').mean()
# Print the output of weekly_mean.corr()
print(weekly_mean.corr())
# Plot weekly_mean with subplots=True
weekly_mean.plot(subplots=True)
plt.show()
Example 7: Daily hours of clear sky (OSTHIR)
In a previous exercise, you analyzed the 'sky_condition' column to explore the difference in temperature on sunny days compared to overcast days. Recall that a 'sky_condition' of 'CLR' represents a sunny day. In this exercise, you will explore sunny days in greater detail. Specifically, you will use a box plot to visualize the fraction of days that are sunny.
The 'sky_condition' column is recorded hourly. Your job is to resample this column appropriately such that you can extract the number of sunny hours in a day and the number of total hours. Then, you can divide the number of sunny hours by the number of total hours, and generate a box plot of the resulting fraction.
As before, df_clean is available for you in the workspace.
INSTRUCTIONS:
- Create a Boolean Series for sunny days. Assign the result to
sunny. - Resample
sunnyby day and compute the sum. Assign the result tosunny_hours. - Resample
sunnyby day and compute the count. Assign the result tototal_hours. - Divide
sunny_hoursbytotal_hours. Assign tosunny_fraction. - Make a box plot of
sunny_fraction.
# Create a Boolean Series for sunny days: sunny
sunny = df_clean['sky_condition'] == 'CLR'
# Resample the Boolean Series by day and compute the sum: sunny_hours
sunny_hours = sunny.resample('D').sum()
# Resample the Boolean Series by day and compute the count: total_hours
total_hours = sunny.resample('D').count()
# Divide sunny_hours by total_hours: sunny_fraction
sunny_fraction = sunny_hours / total_hours
print(sunny_fraction)
# Make a box plot of sunny_fraction
sunny_fraction.plot(kind='box')
plt.show()
Example 8: Probability of high temperatures
We already know that 2011 was hotter than the climate normals for the previous thirty years. In this final exercise, you will compare the maximum temperature in August 2011 against that of the August 2010 climate normals. More specifically, you will use a CDF plot to determine the probability of the 2011 daily maximum temperature in August being above the 2010 climate normal value. To do this, you will leverage the data manipulation, filtering, resampling, and visualization skills you have acquired throughout this course.
The two DataFrames df_clean and df_climate are available in the workspace. Your job is to select the maximum temperature in August in df_climate, and then maximum daily temperatures in August 2011. You will then filter out the days in August 2011 that were above the August 2010 maximum, and use this to construct a CDF plot.
Once you've generated the CDF, notice how it shows that there was a 50% probability of the 2011 daily maximum temperature in August being 5 degrees above the 2010 climate normal value!
INSTRUCTIONS:
- From
df_climate, extract the maximum temperature observed in August 2010. The relevant column here is'Temperature'. You can select the rows corresponding to August 2010 in multiple ways. For example,df_climate.loc['2011-Feb']selects all rows corresponding to February 2011, whiledf_climate.loc['2009-09', 'Pressure']selects the rows corresponding to September 2009 from the'Pressure'column. - From
df_clean, select the August 2011 temperature data from the'dry_bulb_faren'. Resample this data by day and aggregate the maximum value. Store the result in august_2011. - Filter out days in
august_2011where the value exceededaugust_max. Store the result inaugust_2011_high. - Construct a CDF of
august_2011_highusing 25 bins. Remember to specify thekind,normed, andcumulativeparameters in addition tobins.
# Extract the maximum temperature in August 2010 from df_climate: august_max
august_max = df_climate.loc['2010-08', 'Temperature'].max()
print(august_max)
# Resample the August 2011 temperatures in df_clean by day and aggregate the maximum value: august_2011
august_2011 = df_clean.loc['2011-Aug', 'dry_bulb_faren'].resample('D').max()
# Filter out days in august_2011 where the value exceeded august_max: august_2011_high
august_2011_high = august_2011.loc[august_2011 > august_max]
# Construct a CDF of august_2011_high
august_2011_high.plot(kind='hist', normed=True,cumulative=True, bins=25)
# Display the plot
plt.show()