Introduction to Big Data with Apache Spark - ua-datalab/Workshops GitHub Wiki
Links:
📓 These notes:
💻 Code
:video_camera: Link to Zoom recording (11-04-2023)
Introduction
What is Apache Spark?
Apache Spark is an open-source unified analytics engine for large-scale data processing of data engineering, data science, and machine learning on single-node machines or clusters.
Why Spark?
- Problem: Single machine can not complete the computaion
- Soluion: Parallelize the job and distribute work among a network of machines
Databricks completed the Daytona GraySort, which is a distributed sort of 100 terabyte (TB) of on-disk data, in 23 minutes with 206 machines with 6,592 cores during this year's Sort Benchmark competition.Databricks pushed Spark further to also sort one petabyte (PB) of data on 190 machines in under four hours (234 minutes).
Why Spark is fast?
- In-Memory Processing: Spark leverages in-memory computing to process data in RAM, which significantly accelerates processing speeds compared to traditional disk-based systems.
- Distributed Computing: Spark distributes data across a cluster of machines, allowing for parallel processing of tasks.
Spark Architecture
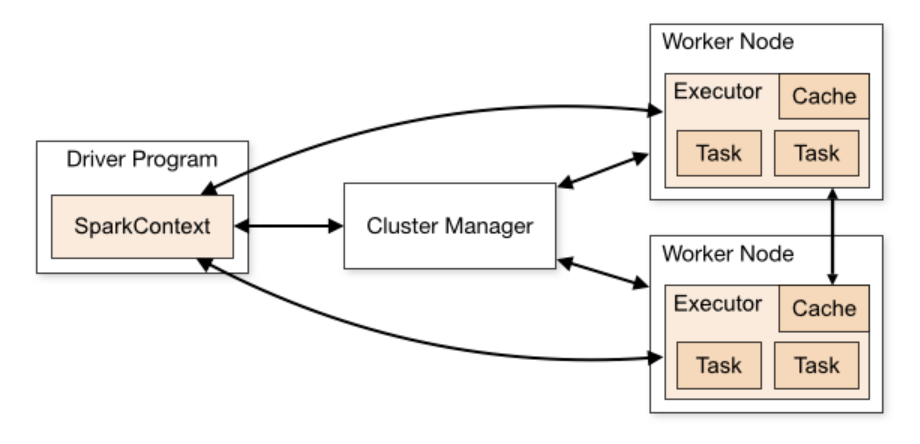
- Master-Slave Architecture: Spark follows a master-slave architecture. The Master node manages the distribution of tasks, while Worker nodes execute those tasks.
- Cluster Manager: The cluster manager is responsible for managing resources across the cluster. It allocates tasks to worker nodes based on available resources. Spark can work with different cluster managers, including Apache Mesos, Hadoop YARN, and its standalone cluster manager.
- Driver Program: The driver program is responsible for coordinating the execution of tasks in a Spark application. It is the entry point for any Spark functionality. The driver sends tasks to the cluster's worker nodes and schedules computations.
- Worker Node: Worker nodes are the machines in the cluster that execute the tasks assigned to them by the driver. Each worker node has its own executor processes. These processes are responsible for running computations and storing data locally.
- Executor: An executor is a process that runs on each worker node and is responsible for executing tasks. Executors manage both the computation and storage resources for the tasks they execute.
- Task: A task is a unit of work that is sent to a worker node for execution. Tasks are created by the driver and executed by the executors.
Components

- Spark Core is the foundation of the platform. It is responsible for memory management, fault recovery, scheduling, distributing & monitoring jobs, and interacting with storage systems
- Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
- Spark SQL provides a unified data processing framework for both structured and unstructured data. It allows you to execute SQL queries alongside your Spark code.
- MLlib is Spark's machine learning library. It provides a wide range of algorithms and tools for building and training machine learning models at scale.
- GraphX is Apache Spark's API for graphs and graph-parallel computation.
Spark APIs
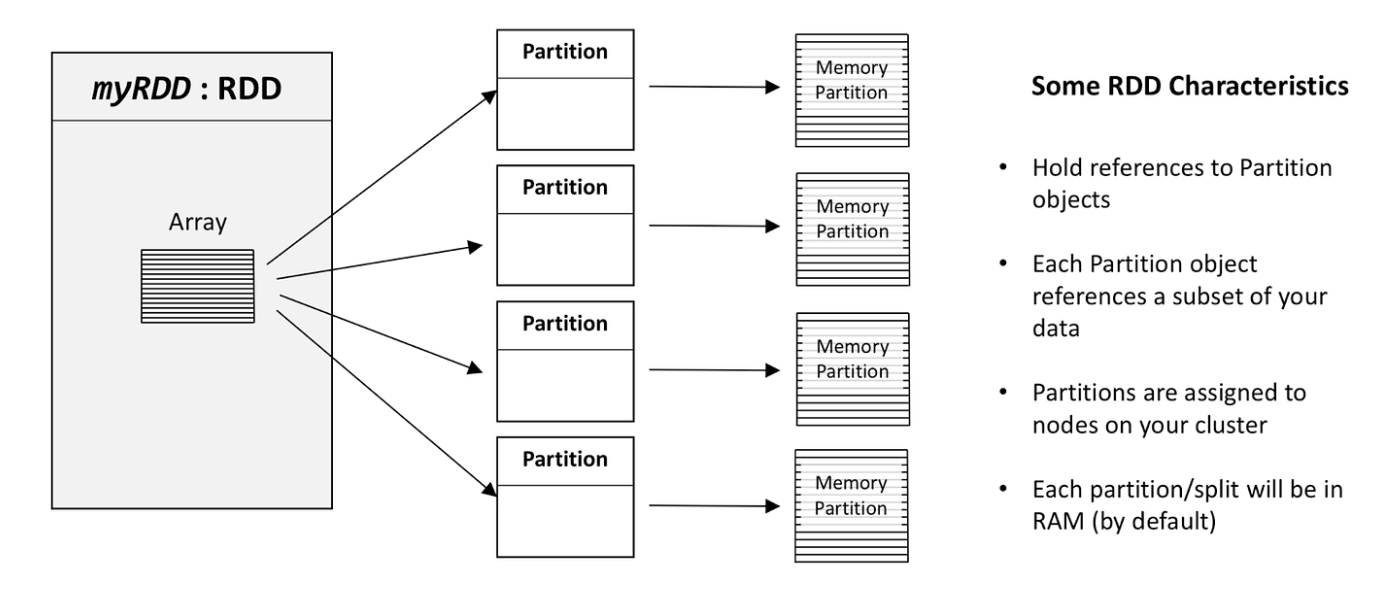
- Resilient Distributed Dataset (RDD): RDD is the fundamental data structure in Spark. It is an immutable distributed collection of objects that can be processed in parallel across a cluster.