Using Transparently Compressed Files
NTFS has a special internal storage format for compressed files. This format is compatible with compressing and decompressing on the fly, which makes transparent reading and writing compressed files by applications possible without explicitly starting a compression tool. Doing so, storage space is saved at the expense of computing requirements and files stored on slow devices may be read faster than uncompressed ones.
Another compression method has been brought by Windows Server 2012 through the deduplication feature : similar parts of different files are only stored once and compressed. This requires an examination of all the files in the file system so it is not compatible with deduplicating on the fly. Deduplicated files are however organized as reparse points, so that the reassembly of parts needed for a transparent reading can be triggered. The deduplication is mostly used for saving space on backup storage.
Yet newer compression methods have been brought by Windows 10 for saving space on the system partition. Each file is compressed individually, using a more efficient format not compatible with compressing on the fly. Such compressed files are also organized as reparse points and can be read transparently. Windows 10 apparently only uses these formats on computers which can decompress faster than read uncompressed.
Currently reading compressed files is supported by all ntfs-3g versions. Creating new compressed files, clearing contents, and appending data to existing compressed files are supported since ntfs-2009.11.14. Modifying existing compressed files by overwriting existing data (or existing holes) is supported since ntfs-3g-2010.8.8.
When the mount option compression is set, files created in a directory marked for compression are created compressed. They remain compressed when they are moved (by renaming) to a regular directory in the same volume, and data appended to them after they have been moved are compressed. Conversely files which were present in a directory before it is marked for compression, and files moved from a directory not marked for compression are not compressed. Copying a compressed file always decompresses it, just to compress it again if the target directory is marked for compression.
A directory is marked for compression by setting the attribute flag FILE_ATTRIBUTE_COMPRESSED (hex value 0x00000800). This can be done by setfattr applied to the extended attribute system.ntfs_attrib_be. This attribute is not available in older versions, and system.ntfs_attrib has to be used instead, with the value shown as 0x00080000 on small-endian computers. Marking or unmarking a directory for compression has no effect on existing files or directories, the mark is only used when creating new files or directories in the marked directory.
# Mark a directory for compression
setfattr -h -v 0x00000800 -n system.ntfs_attrib_be directory-name
# On small-endian computers when above is not possible
setfattr -h -v 0x00080000 -n system.ntfs_attrib directory-name
# Disable compression for files to be created in a directory
setfattr -h -v 0x00000000 -n system.ntfs_attrib directory-nameNotes
- compression is not recommended for files which are frequently read, such as system files or files made available on file servers. Moreover compression is not effective on files compressed by other means (such as zip, gz, jpg, gif, mp3, etc.)
- ntfs-3g tries to allocated consecutive clusters to a compressed file, thus avoiding fragmentation of the storage space when files are created without overwriting.
- some programs, like gcc or torrent-type downloaders, overwrite existing data or holes in files they are creating. This implies multiple decompressions and recompressions, and causes fragmentation when the recompressed data has not the same size as the original. Such inefficient situations should be avoided.
- compression is not possible if the cluster size is greater than 4K bytes.
The file deduplication feature can be enabled at partition level on Windows Servers since the 2012 edition. The deduplication itself is done by a background process which examines files from the partition to detect common parts. Small files are excluded, so are encrypted files and those which are compressed at the application level (by zip, gzip, etc.).
The deduplicated files are stored like sparse files with no data and they are referenced in normal directories. Their attributes (size, time stamps, permissions, etc.) are the original ones with reparse point information added to locate actual data possibly shared with other deduplicated files.
Each part of a file (a chunk) is compressed and stored within a chunks file. The size of each chunk is variable and limited to 131K. The chunks which are part of a file are listed in one or more smaps file. Finally the smaps designating parts of the file are listed in the reparse data of the file (see picture). The splitting of files to chunks strives to maximize the amount of shared chunks.
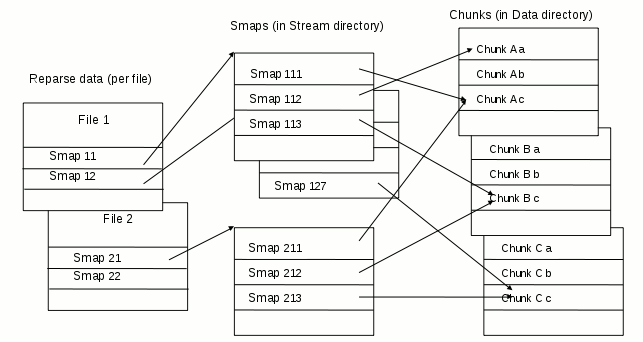
Each smap entry records the size and position of the designated chunk in the file, and similarly each reparse data entry records the global size and position of the chunks recorded in the designated smap. Thus, when looking for some position in the file, the required chunk can easily be determined, and getting the data only requires decompressing the chunk from its beginning.
The chunks, smaps and other technical files used by the background deduplication process are stored in standard files within the "System Volume Information" directory. New files are created and stored the usual way, until the background process examines them for deduplication. Files which are opened for updating must be extracted and stored the usual way before the updating takes place.
Reading deduplicated files is only possible since ntfs-3g-2016.2.22AR.1 and requires a specific plugin (available on the download page). There is no deduplication background process. Newly created files are not deduplicated. Updating deduplicated files is not possible, they can be deleted and recreated as new files. When the partition is mounted on Windows, the deduplication process examines new files for decompression and reclaims the space which was used by chunks from deleted files not used by other files.
The system compression feature is activated on some Windows 10 system partitions in order to reduce the system footprint. Several compression methods are available, they have a better compression rate than basic compression but they requires more CPU time and they are not compatible with updating on the fly. Windows uses this compression method for system files which are written during a system update and never updated subsequently.
The system compressed files are stored like sparse files with no data and they are referenced in normal directories. Their attributes (size, time stamps, permissions, etc.) are the original ones with a compressed stream added, in association with reparse point information to describe the compression method used.
The original file is split into fixed-size chunks which are compressed independently. A list of the compressed chunks is located at the beginning of the compressed stream, followed by the compressed data, with no space in between. By looking at the table, the compressed chunk for some uncompressed position can be determined and decompressed, so reading some portion of the file is possible without decompressing from the beginning of the file. However creating a new compressed file is only possible when its size is known, so that the space for the chunks table can be reserved. Updating some part of the file without changing its size implies changing the size of some compressed chunks and consequently having to relocate the chunks up to the end of stream and to update the chunks table. In short, appending data to a compressed file or updating its contents require decompressing the whole file and recompressing it. Reading system compressed files is only possible since ntfs-3g-2016.2.22AR.1 and requires a specific plugin (available on the download page)
The basic NTFS compression is based on the public domain algorithm LZ77 (Ziv and Lempel, 1977). It is faster than most widely used compression methods, does not require to decompress the beginning of the file to read or update a random part of it, but its compression rate is moderate.
The file to compress is split into 4096 byte blocks, and compression is applied on each block independently. In each block, when a sequence of three bytes or more appears twice, the second occurrence is replaced by the position and length of the first one. A block can thus be decompressed, provided its beginning can be located, by locating the references to a previous sequence and replacing the references by the designated bytes.
If such a block compresses to 4094 bytes or less, two bytes mentioning the new size are prepended to the block. If it does not, the block is not compressed and two bytes mentioning a count of 4096 are prepended.
Several compressed blocks representing 16 clusters of uncompressed data are then concatenated. If the total compressed size is 15 clusters or less, the needed clusters are written and marked as used, and the remaining ones are marked as unneeded. If they only contain zeroes, they are all marked as unneeded. If 16 or 17 clusters are needed, no compression is done, the 16 clusters are filled with uncompressed data. The cluster size is defined when formating the volume (generally 512 bytes for small volumes and 4096 for big volumes).
Only the allocated clusters in a set of 16 or less are identified in the allocation tables, with neighbouring ones being grouped. When seeking to a random byte for reading, the first cluster in the relevant set is directly located. If the set is found to contain 16 allocated clusters, it is not compressed and the requested byte is directly located. If it contains 15 clusters or less, it contains blocks of compressed data, and the first couple of bytes of each block indicates its compressed size, so that the relevant block can be located, it has to be decompressed to access the requested byte.
When ntfs-3g appends data to a compressed file, the data is first written uncompressed, until 16 clusters are filled, which implies the 16 clusters are allocated to the file. When the set of 16 clusters is full, data is read back and compressed. Then, if compression if effective, the needed clusters are written again and the unneeded ones are deallocated.
When the file is closed, the last set of clusters is compressed, and if the file is opened again for appending, the set is decompressed for merging the new data.
NTFS-3G project is sponsored by Tuxera Inc.
![]()
