DFS && BFS - tenji/ks GitHub Wiki
DFS 全称是 Depth First Search,中文名是深度优先搜索,是一种用于遍历或搜索树或图的算法。所谓深度优先,就是说每次都尝试向更深的节点走。
优缺点:
- 空间复杂度:与深度成正比,假设深度为 n,则为 O(n)
- 可能会存在爆栈的危险
- 不能搜最短路径,最小等问题
算法规则:
- 如果可能,访问一个邻接的未访问顶点,标记它,并将它放入栈中;
- 当不能执行规则 1 时,如果栈不为空,就从栈中弹出一个顶点;
- 如果不能执行规则 1 和规则 2 时,就完成了整个搜索过程。
遍历模式:(先、中、后是以根节点的访问顺序为主的)
- 先序遍历:对任一子树,先访问根,然后遍历其左子树,最后遍历其右子树。
- 中序遍历:对任一子树,先遍历其左子树,然后访问根,最后遍历其右子树。
- 后序遍历:对任一子树,先遍历其左子树,然后遍历其右子树,最后访问根。
Java 实现:(搜索树,
LinkedList是Deque的实现,栈可以使用push和pop方法实现)

输出顺序:A, B, C, D, E, F, G, H, I
// 中序遍历
public static void inOrderTraverse(TreeNode root) {
Deque<TreeNode> stack = new LinkedList<>();
TreeNode node = root;
while (node != null || !stack.isEmpty()) {
if (node != null) {
// node 不为空,则入栈并指向左子树
stack.push(node);
node = node.left;
} else {
// node 为空,说明没有左子树且栈顶元素为最左子树,则出栈并输出,然后指向右子树
TreeNode tem = stack.pop();
System.out.print(tem.val + "->");
node = tem.right;
}
}
}// 中序遍历,递归实现
public static void inOrderTraverseRecur(TreeNode root) {
if (root != null) {
inOrderTraverse(root.left);
System.out.print(root.val + "->");
inOrderTraverse(root.right);
}
}
输出顺序:F, B, A, D, C, E, G, I, H
// 先序遍历
public static void preOrderTraverse(TreeNode root) {
Deque<TreeNode> stack = new LinkedList<>();
TreeNode node = root;
while (node != null || !stack.isEmpty()) {
if (node != null) {
// node 不为空,入栈并输出,然后指向左子树
System.out.print(node.val + "->");
stack.push(node);
node = node.left;
} else {
// node 为空,说明栈顶节点没有左子树,出栈并指向右子树
TreeNode tem = stack.pop();
node = tem.right;
}
}
}// 先序遍历,递归方式
public void preOrderTraverseRecur(TreeNode root) {
if (root != null) {
preOrderTraverseRecur(root.left);
preOrderTraverseRecur(root.right);
System.out.print(root.val + "->");
}
}
输出顺序:A, C, E, D, B, H, I, G, F
// 后序遍历
public static void postOrderTraverse(TreeNode root) {
TreeNode cur, pre = null;
Deque<TreeNode> stack = new LinkedList<>();
stack.push(root);
while (!stack.isEmpty()) {
cur = stack.peek();
/*
满足以下条件出栈并输出:
1、没有左子树和右子树;
2、上一个出栈的节点是当前栈顶节点的左节点或者右节点;
*/
if ((cur.left == null && cur.right == null) ||
(pre != null && (pre == cur.left || pre == cur.right))) {
System.out.print(cur.val + "->");
stack.pop();
pre = cur;
} else {
// 右子树不为空,则入栈
if (cur.right != null)
stack.push(cur.right);
// 左子树不为空,则入栈
if (cur.left != null)
stack.push(cur.left);
}
}
}// 后序遍历,递归方式
public static void postOrderTraverseRecur(TreeNode root) {
if (root != null) {
postOrderTraverseRecur(root.left);
postOrderTraverseRecur(root.right);
System.out.print(root.val + "->");
}
}BFS 全称是 Breadth First Search,中文名是广度优先搜索,与 DFS 并列,但两者除了都能遍历图的连通块以外,用途完全不同,很少有能混用两种算法的情况。深度优先搜索要尽可能的远离起始点,而广度优先搜索则要尽可能的靠近起始点,它首先访问起始顶点的所有邻接点,然后再访问较远的区域,这种搜索不能用栈实现,而是用队列实现。
优缺点:
- 空间复杂度是呈现出指数增长
- 不存在爆栈的危险
- 可以搜索最短路径、最小等问题
算法规则:
- 访问下一个未访问的邻接点(如果存在),这个顶点必须是当前顶点的邻接点,标记它,并把它插入到队列中;
- 如果已经没有未访问的邻接点而不能执行规则 1 时,那么从队列列头取出一个顶点(如果存在),并使其成为当前顶点;
- 如果因为队列为空而不能执行规则 2,则搜索结束。
Java 实现:(搜索树,
LinkedList是Deque的实现,队列可以使用add和poll方法实现)
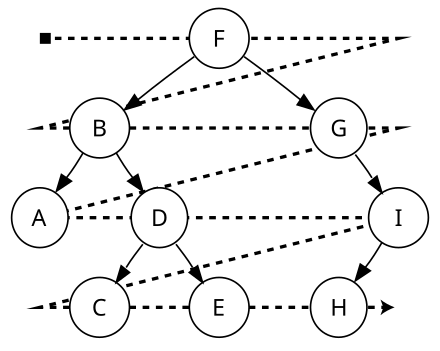
输出顺序:F, B, G, A, D, I, C, E, H
// 树结构
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}// 广度优先搜索
public static void bfs(TreeNode root) {
if (root == null) {
return;
}
Deque<TreeNode> queue = new LinkedList<>(); // 使用 Deque 作为队列
queue.add(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
System.out.print(node.val + "->");
if (null != node.left) {
queue.add(node.left);
}
if (null != node.right) {
queue.add(node.right);
}
}
}/**
* 构建树,递归方式
*
* @param treeArr 节点数组
* @param index 节点对应的数组下标
* @return
*/
public static TreeNode createTree(Integer[] treeArr, int index) {
TreeNode treeNode = null;
if (index < treeArr.length) {
Integer value = treeArr[index];
if (value == null) {
return null;
}
treeNode = new TreeNode(value);
treeNode.left = createTree(treeArr, 2 * index + 1);
treeNode.right = createTree(treeArr, 2 * index + 2);
}
return treeNode;
}