prometheus grafana监控体系 - tencentmusic/cube-studio GitHub Wiki
prometheus架构

其中
- 1、pushgateway是用来接收业务推送的数据形成metrics接口。
- 2、exporter是用来监控组件(三方中间件)并形成metrics接口的组件的统称,负责收集目标对象(host, container…)的性能数据,并通过 HTTP 接口供 Prometheus Server 获取。
- 3、prometheus server是prometheus的核心,相当于时间序列数据库,负责从 Exporter 拉取和存储监控数据,并提供一套灵活的查询语言(PromQL)供用户使用。prometheus server 本身也提供了自己的metrics接口。
- 4、alertmanager是报警装置(prometheus配置报警事件的采集规则,alertmanager配置的报警信息的发送规则),用户可以定义基于监控数据的告警规则,规则会触发告警。一旦 Alermanager 收到告警,会通过预定义的方式发出告警通知。
- 5、grafana是监控可视化报表组件。不仅支持prometheus,还支持很多三方数据库。
Prometheus Operator 架构

其中
Operator
Operator 即 Prometheus Operator,在 Kubernetes 中以 Deployment 运行。其职责是部署和管理 Prometheus Server,根据 ServiceMonitor 动态更新 Prometheus Server 的监控对象。
Prometheus Server
Prometheus Server 会作为 Kubernetes 应用部署到集群中。为了更好地在 Kubernetes 中管理 Prometheus,CoreOS 的开发人员专门定义了一个命名为 Prometheus 类型的 Kubernetes 定制化资源。我们可以把 Prometheus看作是一种特殊的 Deployment,它的用途就是专门部署 Prometheus Server。
Service
这里的 Service 就是 Cluster 中的 Service 资源,也是 Prometheus 要监控的对象,在 Prometheus 中叫做 Target。每个监控对象都有一个对应的 Service。比如要监控 Kubernetes Scheduler,就得有一个与 Scheduler 对应的 Service。当然,Kubernetes 集群默认是没有这个 Service 的,Prometheus Operator 会负责创建。
ServiceMonitor
Operator 能够动态更新 Prometheus 的 Target 列表,ServiceMonitor 就是 Target 的抽象。比如想监控 Kubernetes Scheduler,用户可以创建一个与 Scheduler Service 相映射的 ServiceMonitor 对象。Operator 则会发现这个新的 ServiceMonitor,并将 Scheduler 的 Target 添加到 Prometheus 的监控列表中。
ServiceMonitor 也是 Prometheus Operator 专门开发的一种 Kubernetes 定制化资源类型。
Alertmanager
除了 Prometheus 和 ServiceMonitor,Alertmanager 是 Operator 开发的第三种 Kubernetes 定制化资源。我们可以把 Alertmanager 看作是一种特殊的 Deployment,它的用途就是专门部署 Alertmanager 组件。
监控机器使用情况
Node exporter 主要用于暴露 metrics 给 Prometheus,其中 metrics 包括:cpu 的负载,内存的使用情况,网络等。
在prometheus自带的机器监控中我们可以选中目标机器ip获取指标数据。

为了方便一次性查看所有机器,我们也在git中prometheus/grafana-dashboard文件夹添加了新的看板dashboard的json文件,自己导入就可以。

监控容器使用情况
容器的监控在kubelet中,有些部署方式kubelet启动时会提供metrics接口,有些部署方式默认没有启动。
如果你的kubelet没有提供metrics接口,需要修改启动参数。
# /etc/systemd/system/kubelet.service.d/
Environment="KUBELET_AUTHZ_ARGS=--authentication-token-webhook=true --
authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca.crt"
# kubelet
service kubelet restart
在git的部署文件中已经包含了kubelet的metrics采集和看板显示。在git的prometheus/grafana-dashboard中我们也开源了容器监控的dashboard对应的json文件。自己可以配置top榜单便于排查问题(也包含在git中)。

监控入口流量时延等信息
机器级别和业务级别的监控介绍完,下面开始介绍不同类型的组件。
首先是入口流量的监控。入口流量监控有多种方式:非侵入式的主要有Service Mesh和网关。如果你只需要监控总入口的流量吞吐和时延,或者你并没有复杂的微服务调用链,不需要监控service之间的调用情况,可以使用网关来实现。如果你需要在微服务之间追踪查看调用,可以使用Service Mesh来实现。
Gateway监控
OpenResty是lua语言编写nginx插件的web服务和动态网关框架。比如k8s的ingress-nginx就是OpenResty应用:https://github.com/kubernetes/ingress-nginx,也可以使用另一个网关应用插件kong:https://github.com/Kong/kong
Ingress-nginx新版本已经集成了指标监控。ingress-nginx的部署和监控启用和配置可以按照github官网中操作。这里粘一下效果图。


Service Mesh监控
可以使用istio或linkerd2来实现,因为配置服务网格会添加sidecar容器到业务容器旁边,比较麻烦,所以这里只给一个linkerd2的监控效果图。

监控三方中间件
我们习惯上将监控中间件形成metrics接口的组件称作为exporter,官方支持了很多三方中间件的exporter组件:
https://prometheus.io/docs/instrumenting/exporters/
比如我们想监控kafka,可以直接在页面上跳转到kafka exporter的github,链接的exporter仓库一般都提供了docker版本,需要自己封装成k8s的deployment,并且配置k8s service,并为该exporter的service打上label,使用下文的serviceMonitor将监控添加prometheus中,并且将仓库中的grafana看板配置到grafana中。

自定义pushgateway
官方的pushgate是这样的

在使用之前,有必要了解一下它的一些官方pushgateway的弊端:
- 将多个节点数据汇总到 pushgateway, 如果 pushgateway 挂了,受影响比多个 target 大。
- Prometheus 拉取状态 up 只针对 pushgateway, 无法做到对每个节点有效。
- Pushgateway 可以持久化推送给它的所有监控数据。当prometheus把数据拉取以后,这些数据会仍然留在pushgateway,不会被自动删除。下一次拉取又会被拉渠道prometheus中
- pushgateway在接收到同一个metric的后一次推送时,会把前一次的内容删除掉
- pushgateway客户端在推送数据到pushgateway服务器端以后必须要不同label下的数据清理或者置为0,不然会有叠加效果
由于alertmanager在内网中消息推送有些故障,和官方pushgateway中包含的弊端,我们开源了一个pushgateway。将metric数据收集和消息推送继承在pushgateway中。
其中报警推送代理:
post访问接口/{client}/webhook
参数
sender_type:字符串。推送类型(目前支持wechat和rtx_group)
sender:字符串。推送者(TME_DataInfra或企业微信机器人key)
username:字符串。接收用户(逗号分隔多用户)(微信推送时为rtx,企业微信群推送时为空)
message: 推送字符串,如果有message字段,则仅推送message字段,否则除上面之外的所有字段会json序列化为message推送
监控业务自定义数据
如果通用监控无法满足你的需求,可以自己编写metrics接口。下面以python为例:代码可参考git中python-metric(flask版本和aiohttp版本)
flask
pip install flask
pip install prometheus_client
import prometheus_client
from prometheus_client import Counter
from prometheus_client.core import CollectorRegistry
from flask import Response, Flask
####
@app.route("/metrics")
def ApiResponse():
muxStatus.set(muxCode)
manageStatus.set(manageCode)
return Response(prometheus_client.generate_latest(REGISTRY),mimetype="
text/plain")
aiohttp
pip install asyncio
pip install aiohttp
pip install prometheus_client
import prometheus_client
from prometheus_client import Counter,Gauge
from prometheus_client.core import CollectorRegistry
from aiohttp import web
import aiohttp
import asyncio
import random,logging,time,datetime
routes = web.RouteTableDef()
# metrics
@routes.get('/metrics')
async def metrics(request):
requests_total.inc() #
# requests_total.inc(2)
data = prometheus_client.generate_latest(requests_total)
return web.Response(body = data,content_type="text/plain") #
形成的metrics接口是这样的
# HELP face_search_metric face search metrics
# TYPE face_search_metric gauge
face_search_metric{method="POST",path="/vesionbook/v1.0/user/feature",
project="vesionbook"} 11.0
face_search_metric{method="POST",path="/vesionbook/v1.0/user/search",
project="vesionbook"} 11.0
servicemonitor
上面通过exporter/pushgateway/自定义metric/ingress-nginx/node-exporter/kubelet都已经形成metrcs接口,并且具有service提供对应的服务,我们可以通过这个服务来查看组件是否采集到数据。那么如何将这些数据采集到prometheus中,这就需要编写servicemonitor文件了。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: app1 # 这里必须是k8s-app 不然prometheus采集不了该资源
name: app1
namespace: monitoring
spec:
endpoints: # endpoints
- interval: 30s
path: /metrics
port: http # 端口号只能是字符串, 在pod中定义的端口name
jobLabel: k8s-app
namespaceSelector:
matchNames:
- yournamespace
selector:
matchLabels:
app: app1 # 匹配service
监控非k8s内应用
对于k8s内的数据可以通过上面的servicemonitor,采集service暴露的metrics接口,对于非k8s内的应用,需要自己编写prometheus的配置文件。其实上面的监控,也是通过prometheus-operator自动生成prometheus的配置文件,类似可参考下面的configmap。需要自己熟悉prometheus的记录规则(recording rules)与和报警规则(alerting rules)。
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: prometheus-7.3.0
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global: #
evaluation_interval: 15s
scrape_interval: 15s
scrape_timeout: 10s
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files: # prometheus-rules.yaml
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
配置serviceMonitor后调试
在配置serviceMonitor之前要先通过curl service:port/metrics查看是否正常采集了数据。如果正常采集了数据,后面的监控才能正常。
1、配置了servicemonitor以后,稍微等一两分钟,可以在prometheus中查看配置时否成功。

如果Configuration中包含了你的servicemonitor相关配置(解析成prometh的配置以后的样子),才表示你的sm配置语法正确,并且配置同步到了prometheus中。
2、进入Service Discovery,可以看到你配置的servicemonitor匹配到了多少个pod。(注意由于servicemonitor文件中是匹配的service,prometheus会自动获取service下面绑定的pod,并将pod作为metrics接口的访问地址。并且会随着service下pod的变更而变更)。

3、进入Targets,查看每个pod的metrics接口是否能正常拿到数据。如果能拿到数据,pod状态为绿色。

4、有了数据就可以在Graph中查看到指标数据,并配置grafana了。
Alertmanager配置报警
报警的配置文件在k8s中是通过secret来配置的,需要先生成配置文件的base64编码。
import base64
# alert 报警的secret
# 换行都会变换base64编码后的格式
config='''
global:
resolve_timeout: 5m
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'null'
routes:
- match:
namespace: clickhouse
receiver: 'di'
- match:
namespace: superset
receiver: 'pengluan'
- match:
namespace: infra
receiver: 'pengluan'
# 告警抑制。避免重复告警的。
# https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/alert/alert-manager-inhibit
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# Apply inhibition if the alertname is the same.
equal: ['alertname', 'cluster', 'service']
receivers:
- name: 'di'
webhook_configs:
- send_resolved: true
url: 'http://cloud-pushgateway-service.monitoring/alertmanager/webhook?sender_type=rtx_group&sender=your_key'
- name: 'pengluan'
webhook_configs:
- send_resolved: true
url: 'http://cloud-pushgateway-service.monitoring/alertmanager/webhook?sender_type=wechat&username=pengluan'
- name: 'null'
'''
base64str = base64.b64encode(bytes(config,encoding='utf-8'))
print(str(base64str,encoding='utf-8'))
由于alertmanager在内网配置,报警受网络影响,所以alertmanager的报警推送也是接入到前面开源的pushgateway中。
routes为要匹配的消息和发送的接收者,receivers为接收者的配置,这里配置了微信个人和企业微信群接收。其中企业微信群接收中your_key为企业微信群聊机器人的key值。
如果推送需求无法满足,欢迎开源共建。
Grafana
安装插件 grafana是独立于prometheus之外的,由于对prometheus兼容的比较好,所以一般使用grafana作为prometheus的可视化看板。
grafana的数据源,看板都是以插件的形式进行安装的。https://grafana.com/grafana/plugins。
官方的镜像插件如果满足不了你的需求,需要自己编写Dockerfile来安装自己的插件。如下
FROM grafana/grafana:6.0.0
USER root
# clickhouse数据源
Run grafana-cli plugins install vertamedia-clickhouse-datasource
# 时钟图
Run grafana-cli plugins install grafana-clock-panel
# 饼图
Run grafana-cli plugins install grafana-piechart-panel
# 气泡图
Run grafana-cli plugins install digrich-bubblechart-panel
# 世界地图
Run grafana-cli plugins install raintank-worldping-app
# json数据
Run grafana-cli plugins install grafana-simple-json-datasource
#zabbix报警
Run grafana-cli plugins install alexanderzobnin-zabbix-app
# k8s监控应用
Run grafana-cli plugins install grafana-kubernetes-app
# WindRoseby 极坐标图
Run grafana-cli plugins install fatcloud-windrose-panel
# 雷达图
Run grafana-cli plugins install snuids-radar-panel
# 世界地图热力图
Run grafana-cli plugins install ovh-warp10-datasource
# 选点监控
Run grafana-cli plugins install natel-usgs-datasource
# es数据监控
Run grafana-cli plugins install stagemonitor-elasticsearch-app
# Plotly直接坐标系散点图
Run grafana-cli plugins install natel-plotly-panel
# 组织结构图
Run grafana-cli plugins install digiapulssi-organisations-panel
# ajax请求更新数据
Run grafana-cli plugins install ryantxu-ajax-panel
然后重新构建镜像,并在部署grafana中替换成新镜像名。
dashboard
要想成功配置看板,需要几个步骤:1、配置数据源,2、配置chart,3、配置dashboard。
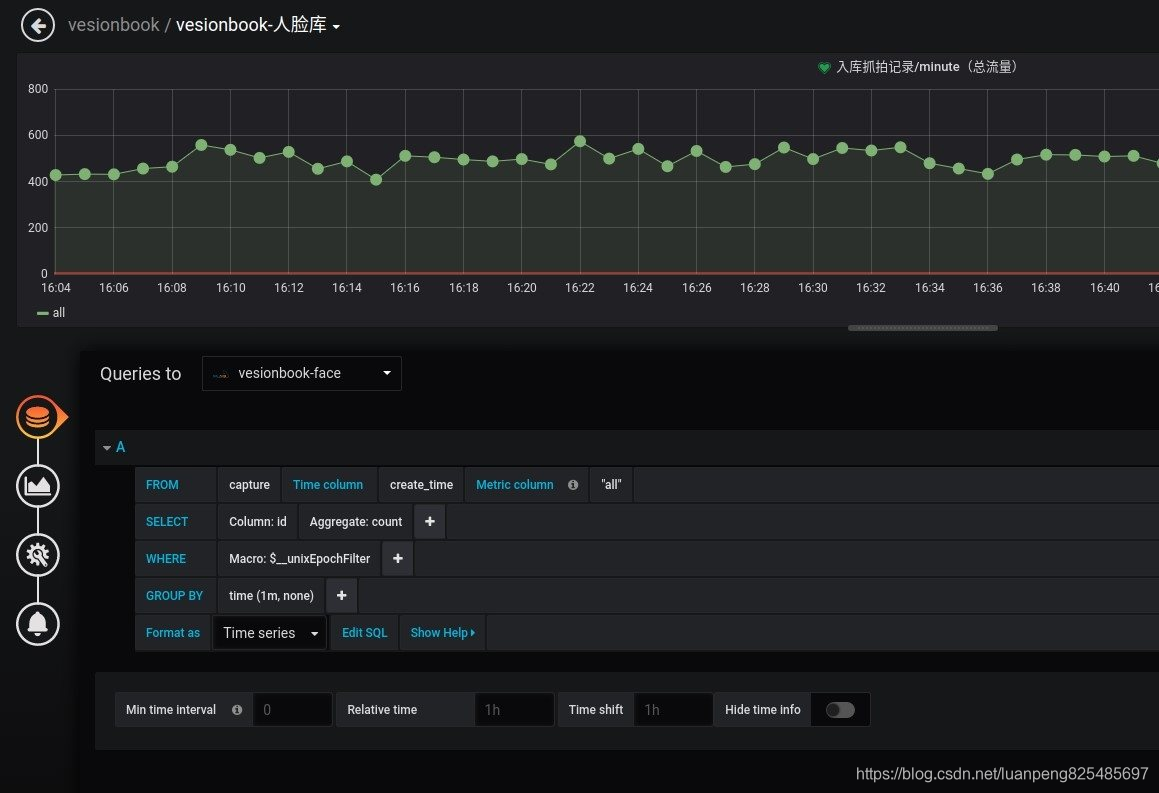
grafana的配置是chart组成dashboard的结构。每个chart的配置需要绑定数据源,可视化报表类型,报警配置等。
Alert
在grafana监控指标难免要配置报警,在内网部署报警受到一些限制,在pushgateway中我们封装了报警接口,在上面的内容也介绍了。所以直接将grafana的报警推送地址接入到pushgateway中。
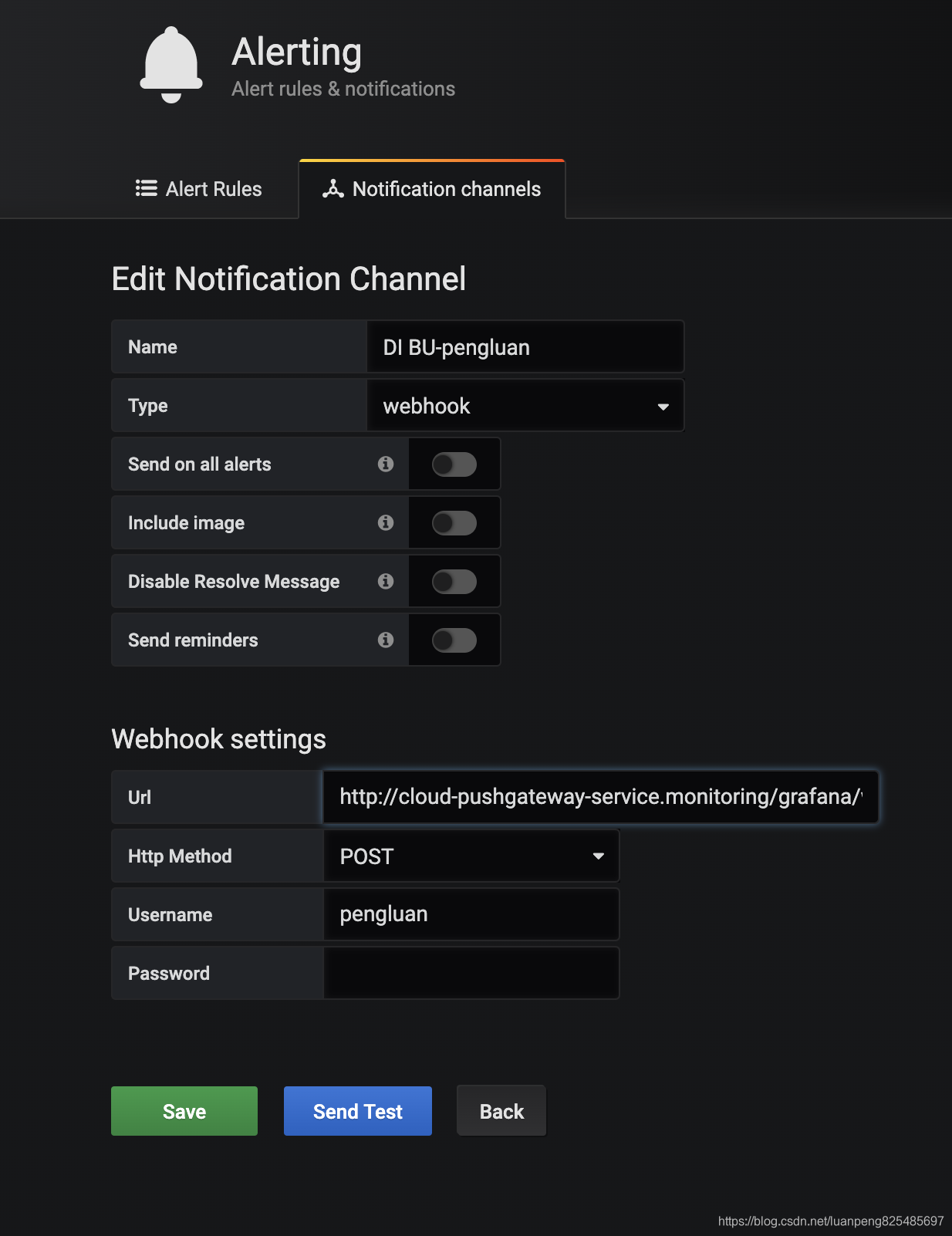
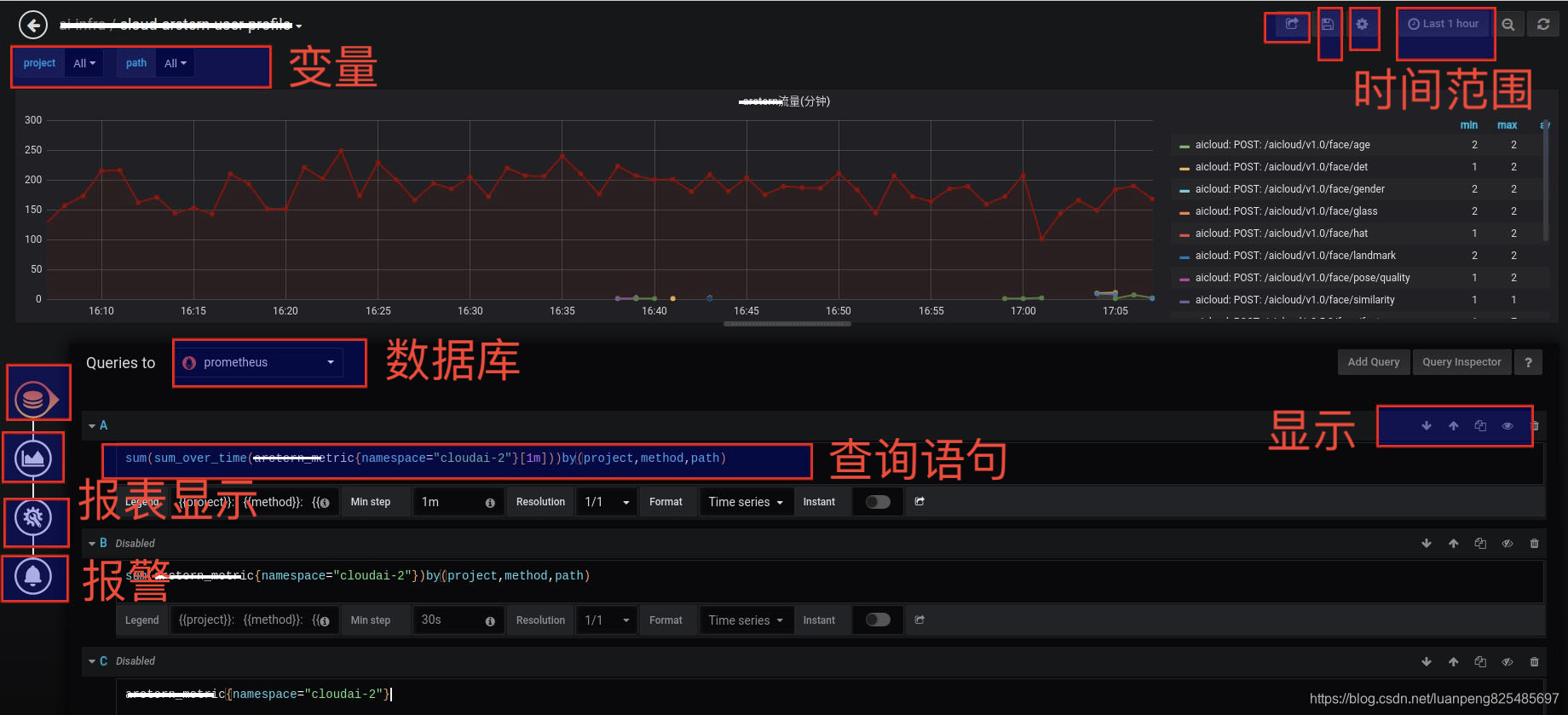
配置pushgateway的接口http://cloud-pushgateway-service.monitoring/grafana/webhook?sender_type=wechat
username为rtx名,密码可以不配置。
其他数据源 除了可以使用prometheus数据库,grafana还支持很多其他的数据库。
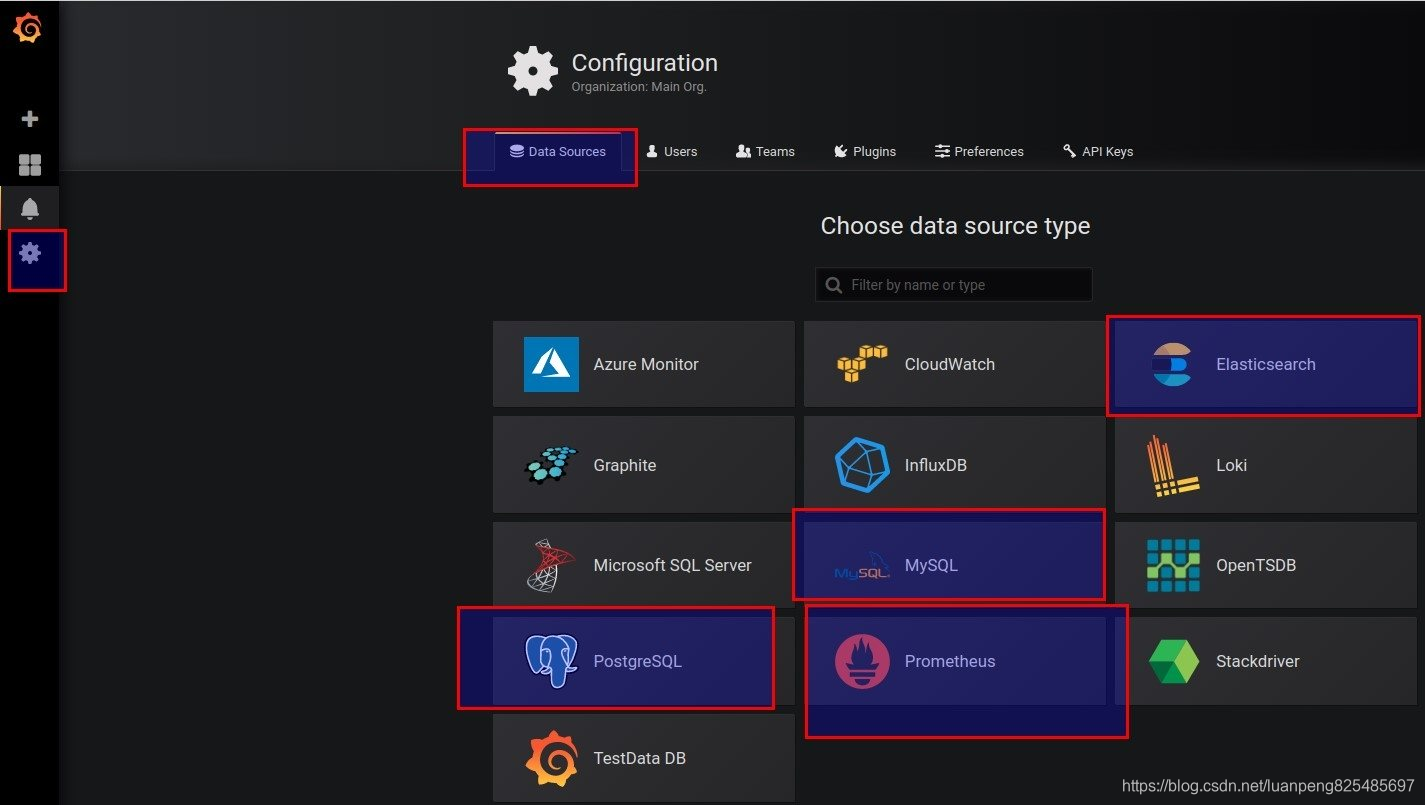
监控业务指标
因为支持更多的数据库,所以也就可以监控数据库中的数据。比如我们可以监控es中存储的日志,也可以监控mysql中的业务数据。例如下面是监控mysql中的数据指标。