模型管理和服务 - tencentmusic/cube-studio GitHub Wiki
模型管理
在“模型管理”中添加模型
模型管理可记录模型所属的项目组、模型版本、算法框架等关键信息,可进行模型的版本管理。在“服务化”-“模型管理”-“添加模型”可添加模型,在每个模型的“更多”中,可以查看更多详情,也可以删除和修改模型信息。
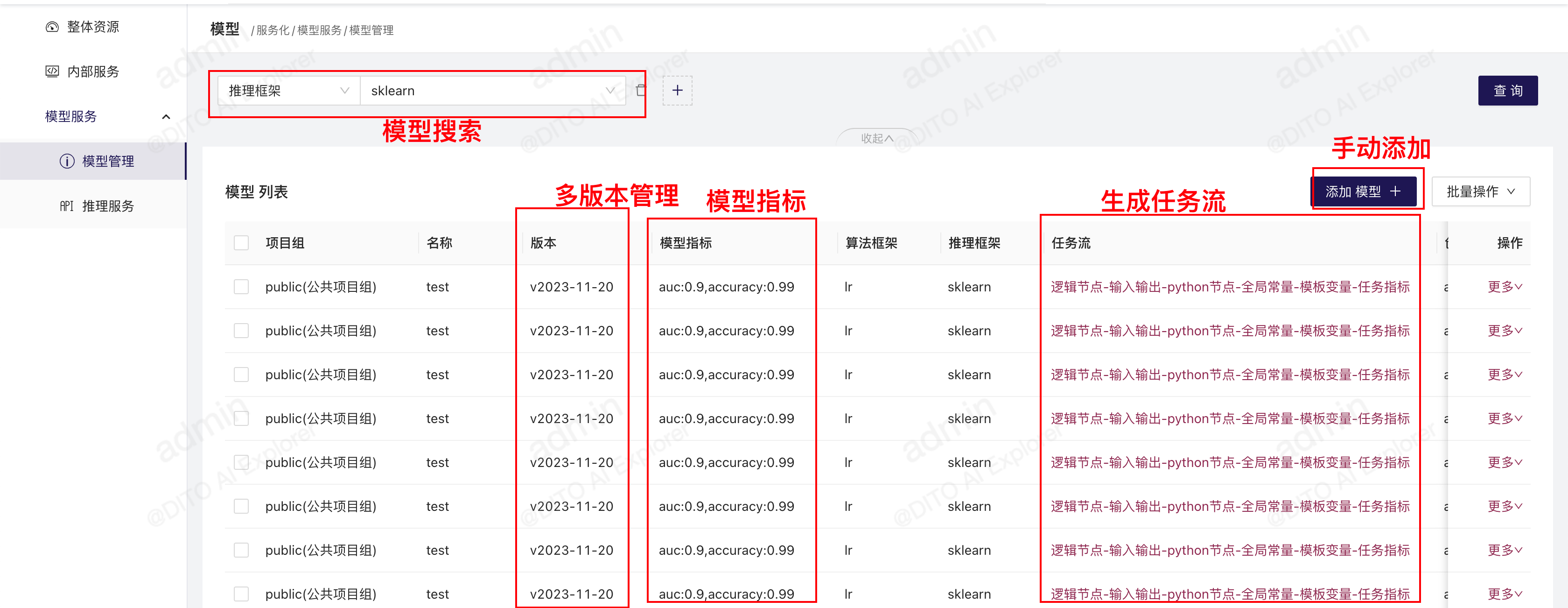
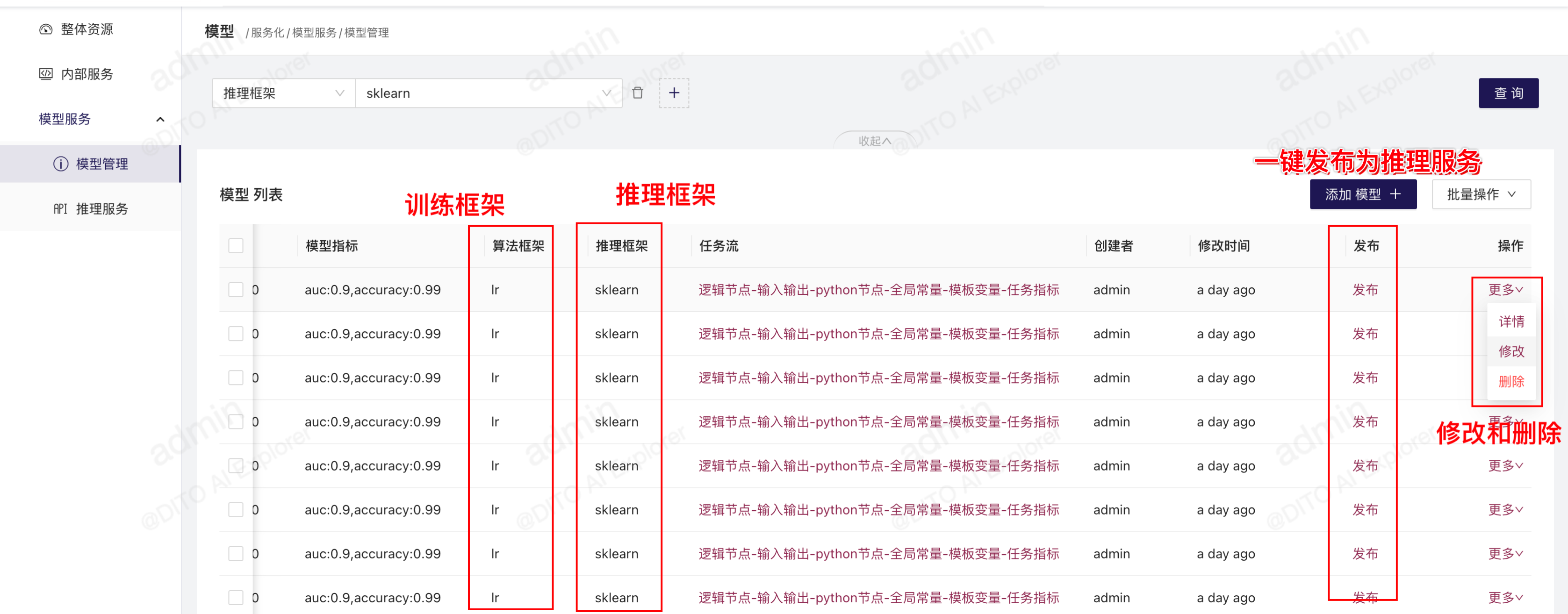
通过pipeline中的“模型注册”模板添加模型
除了手动在模型管理中添加模型,还可以在模型训练的pipeline中,通过“模型服务化”类别下的“model-register”模板来自动注册模型,将模型元数据添加到“模型管理”中来。
子模型
如果在模型管理中注册的模型地址填写的为json格式,那么表示该模型是由多个子模型构成。每个key都表示一个子模型,这种情况下,模型拉取时可以直接拉取子模型。
模型指标
模型指标可填写字符串或者json格式,json格式时,在list列表页面展示的时候会展开成key1=value1,key2=value2的格式
推理服务
服务发布
想要将模型发布成推理服务,可以分两步:\
- 在“模型管理”中添加模型,并且点击“发布”,自动为模型创建推理服务,或者在“推理服务”中,手动添加服务;
- 在“推理服务”中,点击已发布的推理服务的“部署测试”,将模型部署到测试环境,测试通过后,点击“部署生产”,将模型部署到生产环境。


域名访问
第一种方式:公司申请泛域名,并将泛域名解析地址配置到svc/istio-ingressgateway的服务地址上。通过域名访问,在istio-ingressgateway中进行转发到对应的服务上
第二种方式:配置本地host文件,以产生域名解析的效果,不过因为这种方式需要在每个人电脑上配置,所以仅适用于测试
第三种方式:客户端的请求中在header中配置location,istio-ingressgateway就是检测http请求中的location来进行转发的。不过这种方式需要侵入性修改客户端请求,适用于仅提供api的下层服务
流量流向:客户端->istio-ingressgateway(VirtualService)-> k8s service->k8s pod
泛域名的配置: config.py中配置SERVICE_DOMAIN变量为泛域名后缀,例如local.com,
ip:port访问
config.py中配置SERVICE_EXTERNAL_IP=[xx.xx.xx.xx] 或者项目组中配置SERVICE_EXTERNAL_IP=xx.xx.xx.xx,ip需为集群中节点的ip
在内部服务中,端口默认为20000+10*内部服务的id
在推理服务中,端口默认为30000+10*推理服务的id
在notebook中,端口默认为10000+10*推理服务的id
流量流向:客户端 -> k8s service external ip -> k8s pod
版本/域名/pod/ip的关系
$服务名=$模型名-$模型版本(只取版本中的数字)

$k8s-deploymnet名称=$服务名

$k8s-hpa名称=$服务名
在最大最小副本数不一致时创建hpa

$k8s-service名称=$服务名 用于域名的代理
$k8s-service名称=$服务名-external 用户ip的代理

$ip:port=$代理服务ip:20000+10*id

系统自带域名
需要泛域名支持,这里假如泛域名为*.cube-studio.local.com
生产域名
http://$服务名.service.cube-studio.local.com
测试环境域名
http://test.$服务名.service.cube-studio.local.com
http://debug.$服务名.service.cube-studio.local.com
自定义域名
用户可通过host字段配置服务的访问域名
- 配置域名,会使用该域名作为istio-ingressgateway的代理
- 配置url,会使用其中的域名作为代理,但是打开域名自动进入完整的url
- 配置url path,自动生成域名,但是打开会自动进入完整url
多个服务可以配置相同的域名,相同域名的服务只能有一个在线,最新发布的模型会接替同域名的其他模型服务
流量复制和分流
多个服务(可以是相同模型或者不同模型间)配置相同的域名
1、“分流”字段控制分配多少流量到其他服务上,剩余流量归属于当前服务
2、“流量复制”字段控制复制多少流量到其他服务上。但只会将当前服务的响应返回给客户端

灰度升级
1、同一个服务灰度升级,只需要修改服务的配置,重新部署,服务会自动滚动升级pod
2、不同服务进行灰度升级。比如同一个模型的不同版本之间,那么多个服务使用相同的域名,新部署的服务上线正常后,会自动下线同域名的旧服务。
弹性伸缩容
弹性伸缩容的触发条件:“弹性伸缩容”字段可以配置,可以使用自定义指标,可以使用其中一个指标或者多个指标,示例:cpu:50%,mem:%50,gpu:50%
服务优先级
“优先级”字段可配置服务优先级,优先满足高优先级的资源需求,同时保证每个服务的最低pod副本数。
sidecar
通过“Sidecar”字段配置,通过sidecar的配置,推理服务将自动添加伴随容器,使得IP形式访问的推理服务也能获得负载统计数据。
环境变量
系统携带的环境变量
KUBEFLOW_ENV=test
KUBEFLOW_MODEL_PATH=
KUBEFLOW_MODEL_VERSION=
KUBEFLOW_MODEL_IMAGES=
KUBEFLOW_MODEL_NAME=
KUBEFLOW_AREA=shanghai/guangzhou
K8S_NODE_NAME=
K8S_POD_NAMESPACE=
K8S_POD_IP=
K8S_HOST_IP=
K8S_POD_NAME=
内存、CPU、GPU、VGPU
推理服务中,允许用户调整推理服务的内存、CPU、GPU占用以及选择GPU卡型。其中,GPU的占用支持独占、共享、VGPU。可以设置GPU的占用方式为虚拟GPU,比如设置GPU时填写0.2(T4),表示一个推理服务占0.2张T4卡,从而实现单卡上部署多个推理服务的pod。

推理服务的内存、GPU、CPU都是可以在“更多”中修改的。
配置文件,启动目录,启动命令
1、配置文件configmap形式挂载进去。
会配置文件的形式挂载到容器/config/目录下。留空时将被自动重置,格式: ---文件名 多行文件内容 ---文件名 多行文件内容
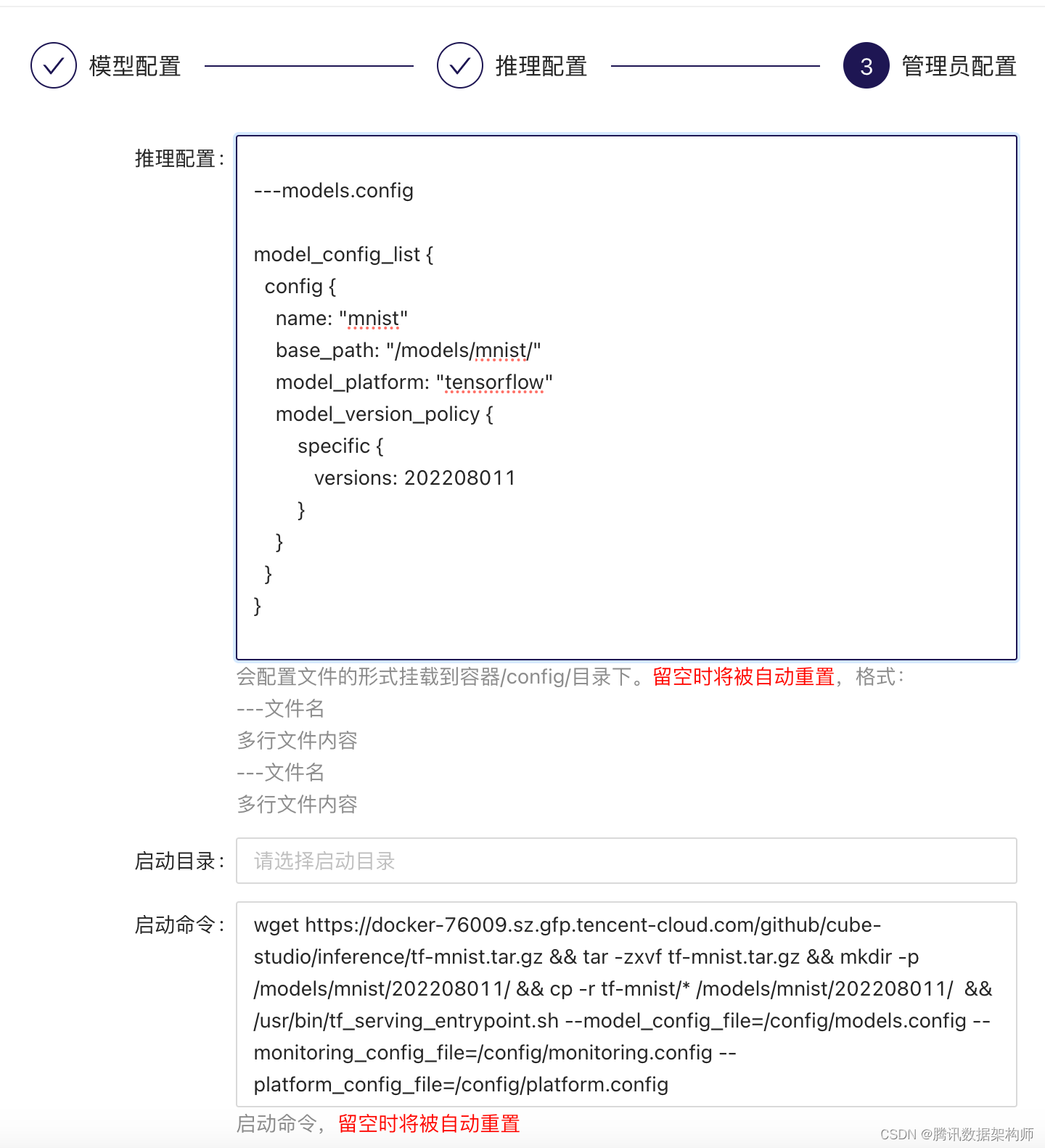
代码中需要读取/config目录下挂载进去的文件
2、启动目录和启动命令会覆盖镜像中的启动目录和命令,注意如果之前的环境中使用~/.bashrc进行了环境初始化,在使用k8s时,是不存在这个文件的。需要在代码中手动去source环境
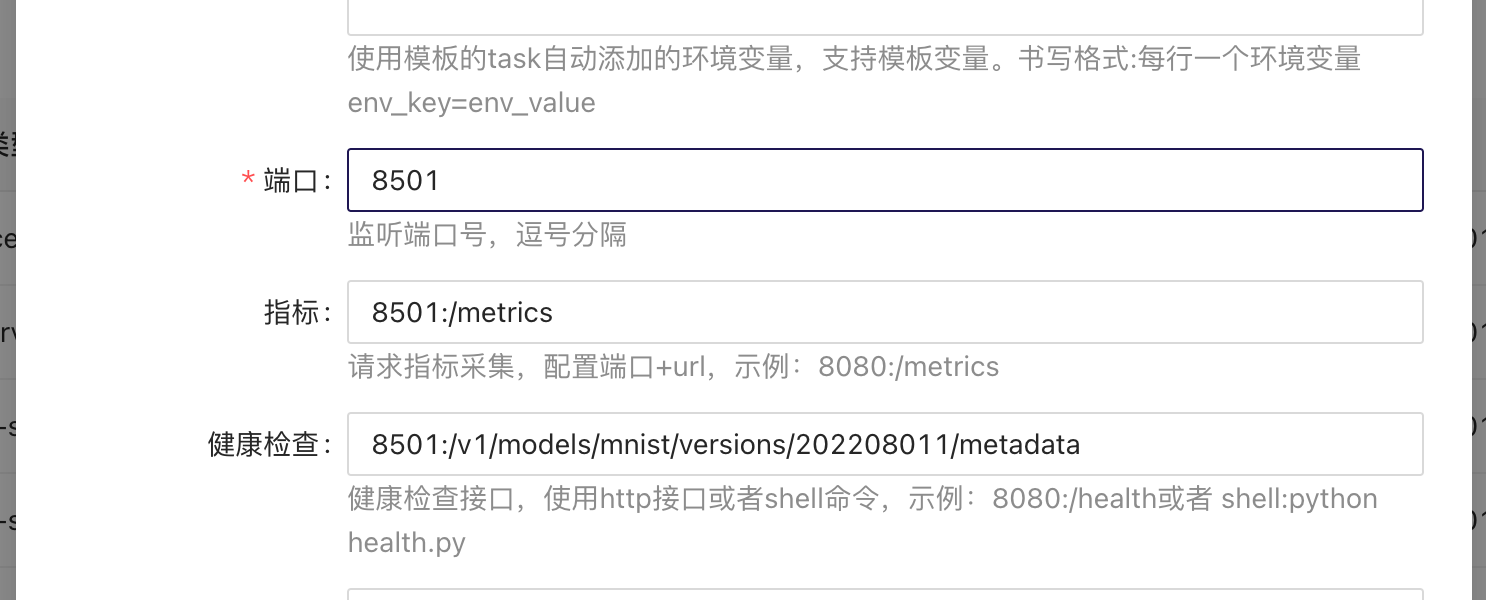
端口
端口最多只能设置2个,用逗号分隔。比如PORT1,PORT2
开放的端口会启动两种方式代理:
1、通过配置的泛域名生成的服务域名进行访问:
第一个端口会由istio-ingressgateway的80端口代理,第二个端口会由istio-ingressgateway的8080端口代理。 访问地址为 service1.example.oa.com:80和service1.example.oa.com:8080
2、会生成ip和端口的访问形式。xx.xx.xx.xx:EXPORT_PORT1和xx.xx.xx.xx:EXPORT_PORT2
其中 EXPORT_PORT1为30000+10推理服务的id EXPORT_PORT2为30001+10推理服务的id
指标
请求指标采集,配置端口+url,示例:8080:/metrics
按照prometheus采集数据的要求,提供/metrics,然后在此处配置端口和地址,配置后会自动被prometheus采集,需要自行配置看板,解析自己的指标进行查看
健康检查
需要业务在代码中提供可用于健康检查的接口,用于阻隔损坏的容器或重启损坏的容器。接口返回200表示正常,其他会阻隔流量或重启容器。检查周期为60s
调试环境/测试环境/生产环境
三者的主要区别:
1、调试环境会重置启动命令为sleep infinity,会自动进入命令行,自己手动启动命令,查看日志。 2、调试环境和测试环境不会启动hpa。 3、调试环境会自动在生产环境域名前添加debug.,测试环境会自动在生产环境域名前添加test.
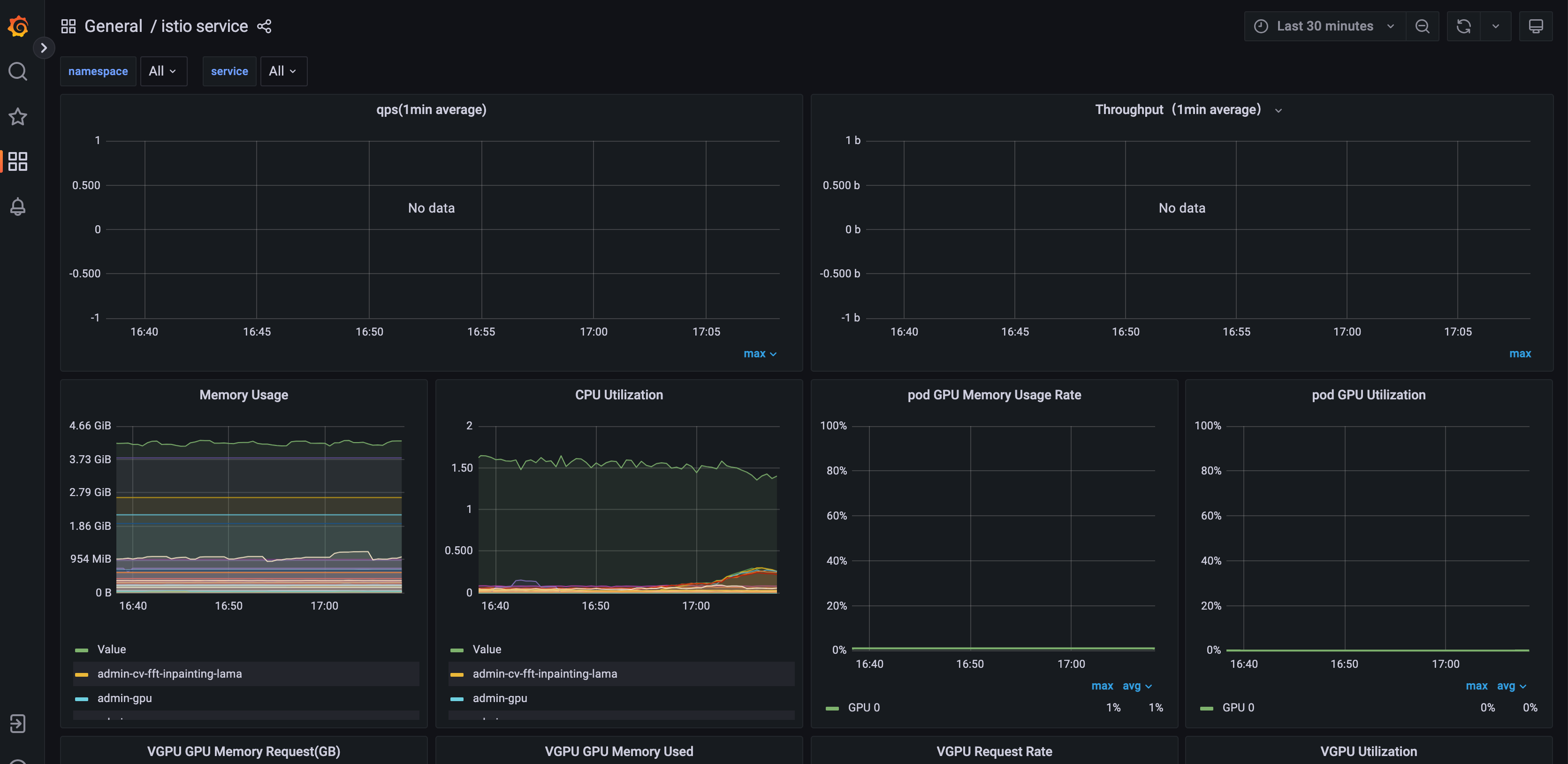
服务负载监控
在每个推理服务后面点击监控按钮,可以查看每个服务的资源使用和流量负载情况。
自定义镜像服务
往往后端推理服务需要特殊的业务处理逻辑。这个时候我们可以选择serving类型的推理服务,自己配置镜像和其他参数。
tfserving/torch-server/triton的服务类型也可以修改镜像名,但是其他的配置,比如配置文件,端口,环境变量等会自动生成,以实现0代码推理发布的目的