数据etl - tencentmusic/cube-studio GitHub Wiki
数据ETL使用
数据ETL是在平台上对接数据中台,操作数据中台完成数据ETL操作。它专用于数据ETL的任务流,对接数据中台之后,在此处添加数据ETL任务流,主要是使用hadoop、sparkjob等任务模板来实现。这里只是编排任务节点,实际的数据ETL任务运行还是在二次开发时对接的任务系统上。
点击“数据ETL”的“新建任务流”,点击新建好的任务流的名称链接,即可进入pipeline编排界面。

生成的任务流编排信息会自动保存为json格式,存在数据库中,在任务流详情界面可以查看该json。

下图所示是一个典型的ETL任务流。左侧边栏有一系列可进行ETL操作的模板,拖拉拽需要的模板,并配置每个任务节点,可以完成数据中台的数据入库、数据ETL、数据入库等操作。

对接数据中台、数据ETL的各类模板,除了平台本身提供的,还可以通过二开来增加模板。
数据ETL部分二开
原理
数据etl支持对接不同的调度引擎,但是cube-studio仅是包含任务的编排能力,并在数据库中形成dag.json,并不是真正去向远程调度系统
所以需要二开实现向远程调度系统创建任务,删除任务,并在远程更新的过程中,记录远程任务的信息在本地数据库中
源码位置
- myapp/views/view_etl_pipeline_airflow.py
- myapp/views/view_etl_pipeline_azkaban.py
- myapp/views/view_etl_pipeline_dolphinscheduler.py
可以对接不同的调度系统实现多个调度系统在etl中的使用,在创建etl任务流时选择对应的调度引擎,就会使用对应的上述模块。
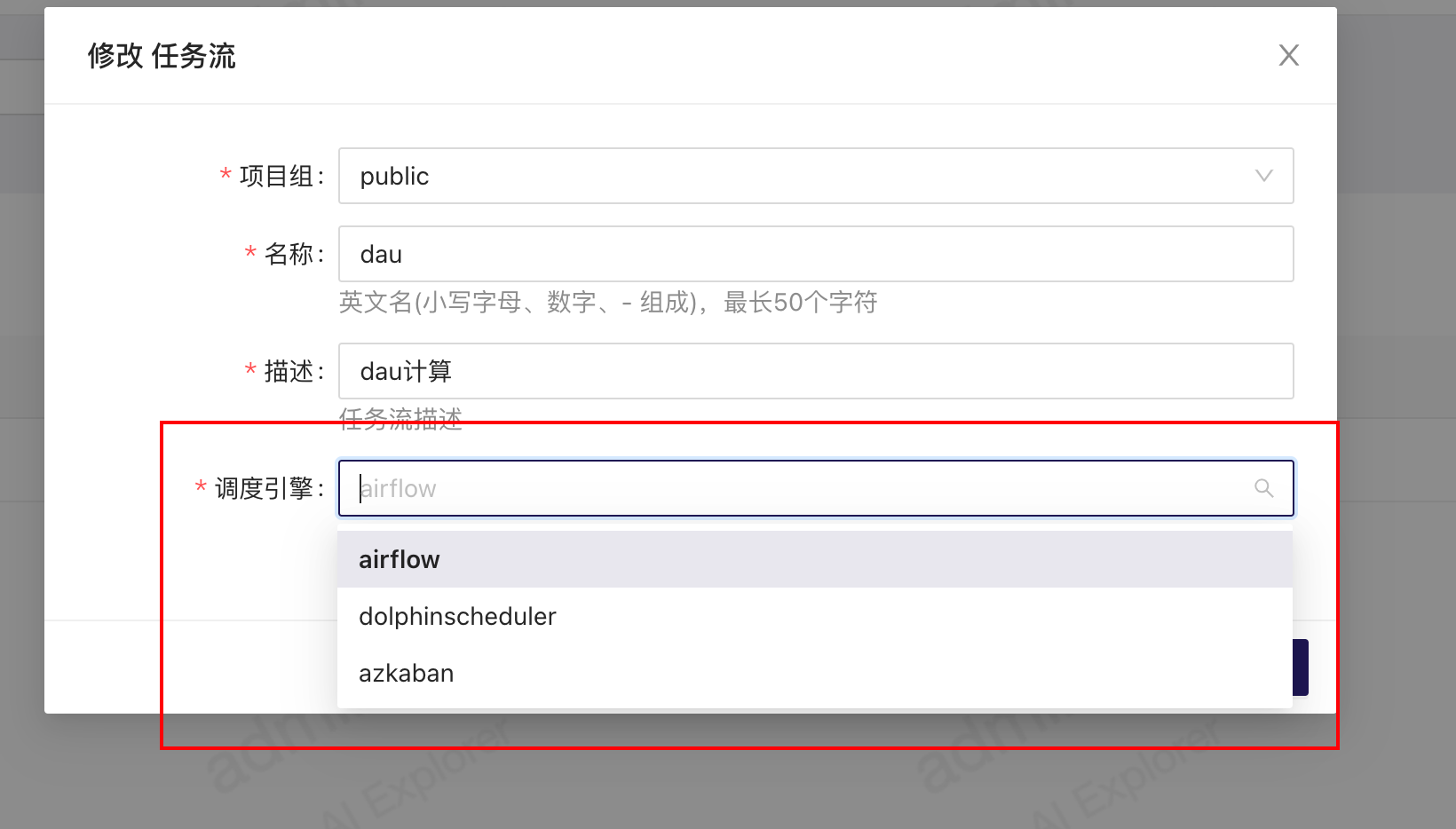
对接实现
ETL的功能模块主要分为以下几个部分实现:
-
模板列表:模板列表是一个单独的函数,可以修改用户看到的列表内容,包括列表名称、列表分组以及列表的固定参数。
-
模板的公共配置和特殊配置:模板的公共配置包括任务名、调度周期、队列、监控告警和超时等。特殊配置是每个模板都不一样的,需要根据具体情况进行调整。
-
编排功能:前端实现编排功能后,会将整个编排内容发送给后端,后端接收到一个包含所有任务信息的JSON文件。这个JSON文件包含任务链的上下游关系、每个任务使用的模板以及用户填写的公共参数和特定参数。
-
提交和删除pipeline:提交和删除pipeline涉及到与远程调度系统的交互。提交任务时,需要将dag_json和全局配置发送给调度系统。删除任务时,需要在远程调度系统中实际删除任务。
在对接过程中,需要实现以下几个函数:
-
模板列表:定义Airflow或Azkaban中的模板列表。
-
跳转按钮和运行按钮:定义跳转到调度实例和运行任务的按钮。
-
提交任务:将dag_json发送给调度系统。
-
删除任务:在调度系统中实际删除任务。
对应函数和变量:
- all_template:想要支持的模板列表
- pipeline_config_ui:pipeline的公共参数配置
- pipeline_jump_button:pipeline的快捷跳转按钮
- pipeline_run_button:pipeline的任务提交按钮
- submit_pipeline:pipeline的远程任务提交
- delete_pipeline: pipeline的远程任务删除