AWS Glue - syou2020/memo GitHub Wiki
架构

半结构化架构转换为关系架构
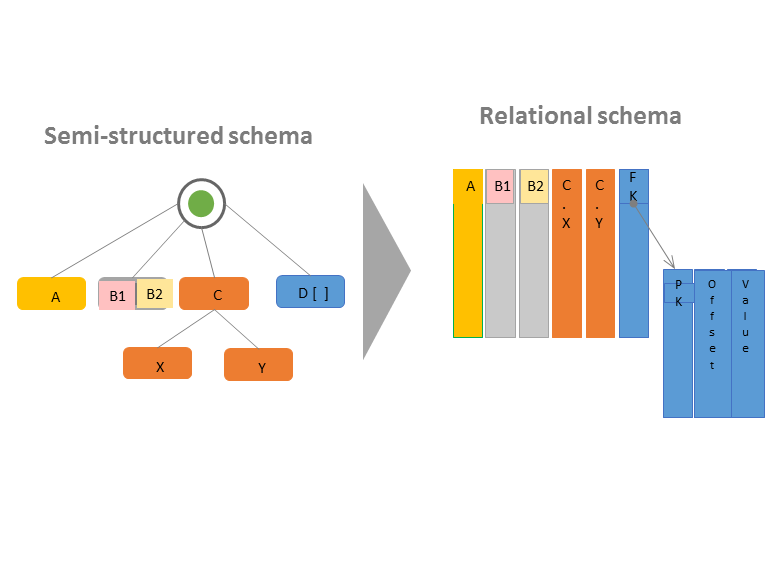
基本工作流程和步骤


在 AWS Glue 数据目录 中定义表 当爬网程序检测到表元数据的更改时,将会在 AWS Glue 数据目录 中创建表的新版本。您可以比较表的当前和过去版本。 表的架构包含其结构。您还可以编辑架构以创建表的新版本 表的历史记录也保留在 Data Catalog 中。您可以查找作业的名称、运行时间、添加了多少行以及作业运行了多长时间。 ETL 作业使用的架构版本也保存在历史记录中。 以下所有条件都必须为 true,AWS Glue 才能为 Amazon S3 文件夹创建分区表: 文件的架构类似,由 AWS Glue 确定。 文件的数据格式是相同的。 文件的压缩格式是相同的 您的爬网程序使用 AWS Identity and Access Management (IAM) 权限角色来访问您的数据存储和 Data Catalog。 传递给爬网程序的角色必须有权访问网络爬取的 Amazon S3 路径和 Amazon DynamoDB 表。
[AWS Glue 中的内置分类器] (https://docs.aws.amazon.com/zh_cn/glue/latest/dg/add-classifier.html)
使用 AWS CloudFormation 模板填充数据目录
开发终端节点教程 您的 Python 脚本必须针对 Python 2.7,因为 AWS Glue 开发终端节点还不支持 Python 3。
将 Python 和 AWS Glue 一起使用
install:
python2.7
aws cli
AWS SDK for Python (Boto 3)
在 AWS Glue 中传递和访问 Python 参数:key-value形(JSONに変換し易いため)
只要是用纯 Python 编写的,就可以将 Python 扩展模块和库与您的 AWS Glue ETL 脚本一起使用。
C 库 (如 pandas) 目前不受支持,用其他语言编写的扩展也不受支持。
#1.创建 AWS Glue 客户端的实例
import boto3
glue = boto3.client(service_name='glue', region_name='us-east-1',
endpoint_url='https://glue.us-east-1.amazonaws.com')
#2.创建作业。您必须使用 glueetl 作为名称的 ETL 命令,如以下代码所示
myJob = glue.create_job(Name='sample', Role='Glue_DefaultRole',
Command={'Name': 'glueetl',
'ScriptLocation': 's3://my_script_bucket/scripts/my_etl_script.py'}
#3.启动JOB
myNewJobRun = glue.start_job_run(JobName=myJob['Name'])
#4.获取作业状态
status = glue.get_job_run(JobName=myJob['Name'], RunId=myNewJobRun['JobRunId'])
print status['myNewJobRun']['JobRunState']
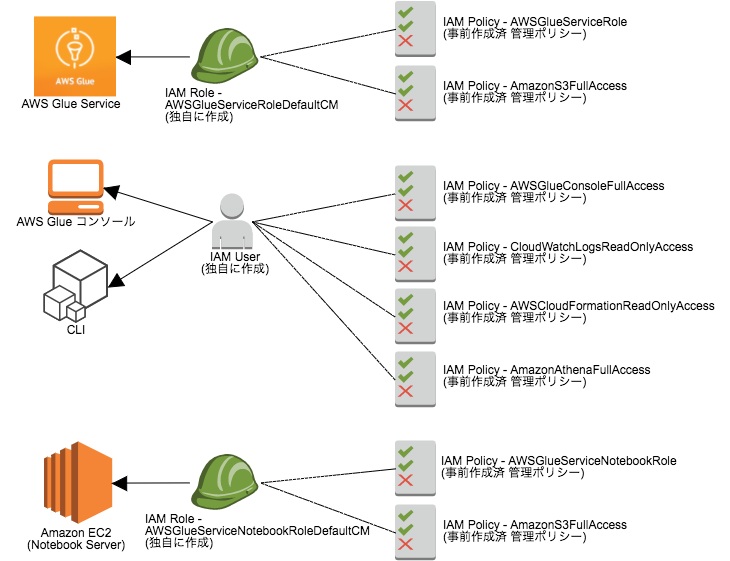
EC2(Zeppelin)インスタンスが AWS Glueを利用するロール(AWSGlueForEC2Role)を作成します。このロールは AWS Glue サービスが実行やリソースにアクセスするための権限を指定します。 AwsGlueServiceRole AwsGlueServiceNotebookRole
Red shift DBにアクセスしたい場合、Redshiftに対するアクセス権限をAWS Glue Serviceに付与
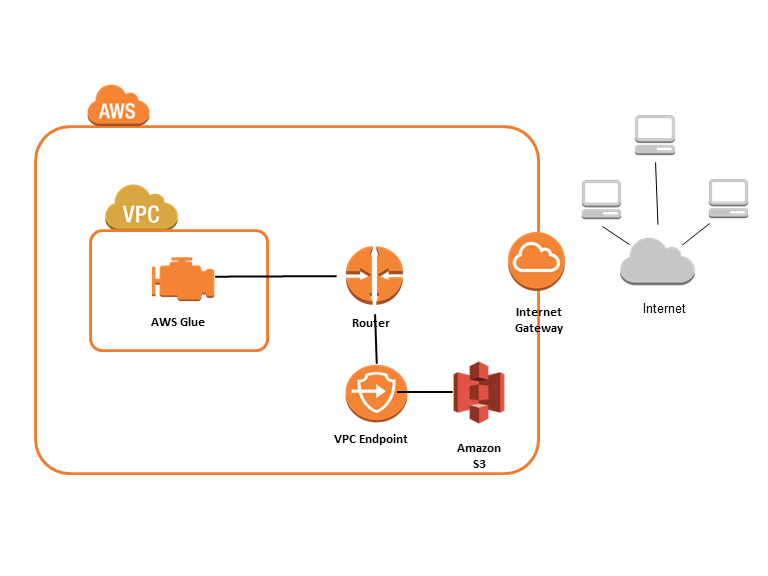
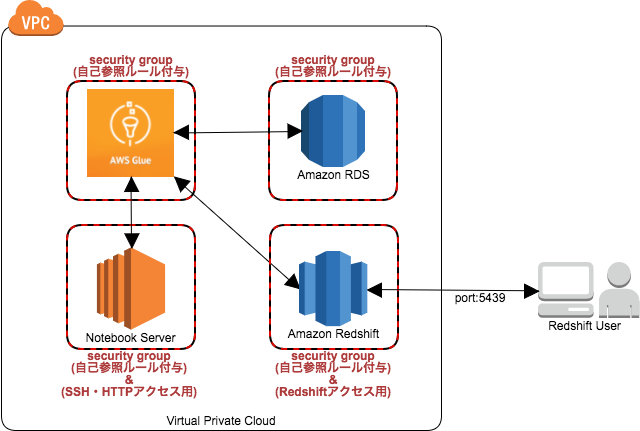
Redshift-Redshift間のETLでしたが、中間ファイルをS3で持つので、S3-Redshift間やRedshift-S3間、その他のDB間との組み合わせでもS3を介して、ETLができる仕組みになっていることがご理解いただけたと思います。
DynamicFrameはAWS Glueで独自に定義されたデータ構造のようです。
DataFrameのようなテーブル形式でデータ
DataFrameと異なり列ごとのデータ型が異なるものにも柔軟な対応が可能
という特徴があるようです。
Spark AWS Glue
DataFrame DynamicFrame
Row DynamicRecord
Athena
SQLを使用したS3でのデータクエリ
Scalaの利点:
SparkのコードはScalaによって書かれていることもあり、Pythonと比較して一般的なSpark2.1ではSparkが提供する機能やライブラリの全てが利用できます。DataFrameが登場するまでRDDに対するPythonのクエリの速度はScalaの同じクエリに比べて半分以下になることもありました。なお、クエリのパフォーマンスの低下の原因は、PythonとJVM間でのコミュニケーションのオーバーヘッドによるものです。
Scalaのユースケース:
既存のSparkのETLコードをAWS Glueに移行する場合、Scalaであれば利点でも述べた通り、Pythonと比較して一般的なScalaはSparkが提供する機能やライブラリのより多くが利用でき、Pythonで生じる性能低下の懸念がありません。AWSのGlueの入出力の仕組みを利用して、Data SourceからDynamicFrameの生成と、Data TargetへDynamicFrameを出力する以外は、既存のSparkのETLコードをそのまま置き換えることが可能であると考えられます。
ScalaでDataSetを利用する
AWS GlueのクエリエンジンであるSpark2.1では、DataFrameとDataSetが統合されており、DataSetはScalaから利用できます。なお、PythonでDataset APIが実装されていない理由の一つは、Pythonが型安全な言語ではないためです。
Spark之RDD :
https://www.cnblogs.com/qingyunzong/p/8899715.html
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象
AWS Glueコンソールのメトリクスの参照では5分毎の表示となりますが、CloudWatch Metric Dashboardsでは、30秒ごとにMetricを参照できます。
AWS Glueプロファイルを使用して30秒ごとにCloudWatchに測定値を送信し、AWS Glue Metrics Dashboardが1分に1回報告します。
特定のExecutorがホットな状態なのか、そしてボトルネックの要因(CPU、メモリ、IO)が何かを把握するのは可能
コードのデバッグ、データの問題の特定、CPUキャパシティの計画に役立ちます
spark sql:
カラムの関数適用、条件(CASE〜WHEN)による編集、データのフィルタ、データの集計などは、AWS Glueが標準で提供しているTransform や Apache SparkのDataFrameの関数を用いて、コードを書かなければなりません。
複雑な処理もSQLのほうが簡潔に書ける場合が多いので、メンテナンスを重視するのであれば、SQLでETLができないか検討すると良いでしょう。
Parquetフォーマットに変換することでAthena、Redshift Spectrum、EMRからより高速にクエリできるようになります。
ネストしていないキーバリュー形式のJSONファイルは、sparkSession.read.json()で、DataFrameに変換できます。しかし、ネストしたJSONファイルは、この方式ではネストしたJSON形式を認識できません。
#ネストされたJSONデータをキーバリューのJSONデータに変換する機能:
dfc_root_table_name = "root" # default value is "roottable"
relationalize1 = Relationalize.apply(
frame = datasource_df,
staging_path = "s3://mybucket/glue/tmp",
name = dfc_root_table_name,
transformation_ctx = "relationalize1")
result_data = relationalize1.select(dfc_root_table_name)
# キーバリューのJSONデータをCSVに出力
datasink2 = glueContext.write_dynamic_frame.from_options(frame = result_data, connection_type = "s3", connection_options = {"path": glue_relationalize_output_s3_path}, format = "csv", transformation_ctx = "datasink2")
#Dataframeによるパーティション出力
df_out = applymapping1.toDF()
partition_keys=['sales_date']
df_out.repartition(*partition_keys).write.partitionBy(partition_keys).mode("append").csv("s3://mybucket/posdata")
#Dynamicframeによるパーティション出力
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://mybucket/posdata", "partitionKeys": ["sales_date"]}, format = "csv", transformation_ctx = "datasink2")
#AWS Glue の Pushdown Predicates を用いてすべてのファイルを読み込むことなく、パーティションをプレフィルタリングする
#不要なデータを読まないことでデータの生成・破棄のコストが下がり、結果的にパフォーマンスが向上、、コスト削減が期待できます。
partition_predicate="year='2015' and month='01' and day='01'"
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "default",
table_name = "elb_parquet",
push_down_predicate = partition_predicate
transformation_ctx = "datasource0")
AthenaなかでS3テーブルを作成:
CREATE EXTERNAL TABLE elb_parquet(
request_timestamp string,
elb_name string,
request_ip string);
Excludeパターン効果の違い
S3データストアとJDBCデータストアでは、同じ様にExcludeパターンを指定できますが、実は機能や目的が異なります。
* Amazon S3 データストアの場合は、読込まないファイル名のパターンを指定することでスキャンの対象となるデータファイルをフィルタできます。
* JDBC データストアの場合は、クロールしないテーブルの指定であり、データそのものはフィルタしません。