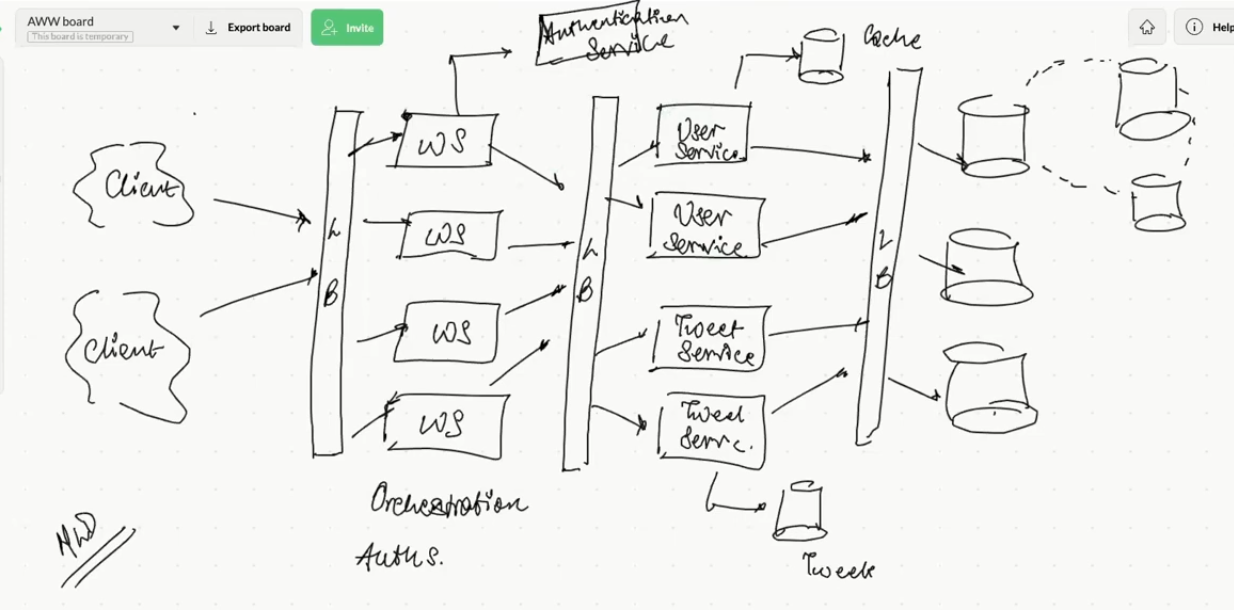
Twitter HLD | Expertifie - sulabh84/SystemDesign GitHub Wiki
- Create Profile - User
- Update Profile - User
- Login into the account
- Post a tweet
- React on a tweet (Like, Comment)
- Follow other users
- Fetch the latest tweets for the user - Feed generation
- Low latency - within a second
- Availability - High
- Consistency - Eventual Consistency should be fine
- More preference should be given to Availability over consistency
- Reliability
- DDoS (Distributed Denial of Services)
- Block the IP from which you have received more than X no of requests within a time window
- System should be highly available
- Right checks for authentication and authorization in the system
- Data transfer should be secure - Request and response should be encrypted
- Backup to retrieve data for disaster recovery
- DDoS (Distributed Denial of Services)
- Estimations
- Assumptions
- 500M users in an year
- 100M daily active users
- 50k new users signing up daily bases
- On an avg. 50% of the active user will create 1 tweet
- every active user gives 10 reactions
- every user will follow another user on an avg in a day
- on an avg a user will check for the latest tweets 5 times
- QPS - for a second
- Read QPS
- 10M (User Login)
- 100M*5 (Fetch latest Tweets)
- 500 * 10^6 / 606024 = 500 * 10^6 / 10^5
- 5000 QPS for reading
- Write QPS (in a day)
- 50k (Create profile)
- 1M (Update Profile)
- 50M (Create Tweets)
- 100M*10 (Reactions)
- 100M (Follow)
- ~1200M writes request per day
- 1200 * 10^6 / 606024 = 1200 * 10^6 / 10^5
- 12000 QPS for writing
- Load might not be evenly distributed across the day, so it might be possible that you see more spike in few hours than what you expect from above calculation
- Multiplier factor -> 1.5
- Read = 5000 * 1.5 = 7500 QPS
- Write = 12000 * 1.5 = 18000 QPS
- Read QPS
- Capacity - at least an year
- (500M + 50K * 365) * 1000 -> Users
- (500M + 400 * 50K)*1000
- 520B bytes
- 50M * 365 * 500Bytes -> tweets
- 50M * 400 * 500
- 100 * 10^5M
- 10000B Bytes
- 100M * 10 * 365 * 100 -> Reaction
- 100 * 10 * 400 * 100M
- 40000B bytes
- 100M * 365 * 100 -> Follow
- 100 * 400 * 100M
- 4000B Bytes
- ~55000B Bytes total = 55TB total in a year
- Note: We have not considered replications here.
- (500M + 50K * 365) * 1000 -> Users
- Assumptions
- APIs
- CreateProfile() returns success/failure
- UserLogin(string username, string password)
- UpdateProfile(List, List)
- CreateTweet(UserId,String TweetContent)
- ReactOnTweet(Userid, tweetId, ReactionType, Content)
- FetchLatestTweets(Userid)
- FollowUser(UserId -> Follower, Userid -> Followee)
- Tables
- User Table (1000 bytes)
- UserId(PK), Password (Encrypted), Name, DoB, Phone Number, Email Address, Profile Picture, CreationTimeStamp
- Tweet Table (500 bytes)
- TweetId(PK), UserId -> Author of the tweet, TweetContent, CreationTimeStamp
- Reaction Table (100 Bytes)
- ReactionId(PK), TweetId, UserId, ReactionType (Like, Comment), Reaction Details -> only populated for comments, CreationTimeStamp
- FollowUser Table (100 bytes)
- UserId -> Follower, UserId -> Followee, TimeStamp
- User Table (1000 bytes)
- Horizontal sharding
- User Table
- Region based shard - 1st level sharding
- Hashing based on the userid - 2nd level sharding
- Region based shard - 1st level sharding
- Tweet Table
- Region based shard
- Hashing based on the userid
- Region based shard
- Reaction Table
- Region based shard
- Hashing based on the tweetid
- Region based shard
- FollowUser Table
- Region based shard
- Hashing based on the userid
- Region based shard
- User Table
- Master Slave configuration
- Data will be written into master and read from the slave
- MultiMaster (Master -> Master -> Master) have slaves under them
- Helps in better distribution of load across layers
- Intelligent Round Robin Strategy for balancing the load between the server/machine
- User is able to login -> authentication
- To verify if the userId for which the request is made belongs to the same user, check if the tokens belong to the same user or not
- Authorization -> if the user can access particular APIs/Service with their credentials
80-20 Rule
- 80% of the request on the system will query for 20% of the data and remaining 20% of the request will be querying on 80% of the data
- based on number of followers we should decide what data should be cached
- User Cache -> Cache profiles of celebrities and famous personalities
- Tweet cache -> Store the data for recent tweets from famous personalities
- Eviction Strategy -> LRU(Least Recently used)
- use write around cache -> to write data into the cache
- Helps monitor the latency of each of the APIs
- Monitor success and failure rates of the APIs
- QPS for each of the APIs
- Monitoring of caches
- Alerting:
- Alert on failure if requests fails X times in a window of a time (1 hour, 10 mins, 20 mins)
- Alerting on the latency -> if X% of the requests from total requests within a window is taking more than t ms to return the result
- BackUps
- Retrieval of data which could be lost because of some bugs
- Product Metrics on backups
- Create metrics for experiments on backups
- Analytics