Basic Concepts - strohne/Facepager GitHub Wiki
Data can be accessed and downloaded from the web with the help of URLs. Facepager assists you to assemble these URLs. First, you have to add nodes and adjust the required settings. Then you can process all your cases with these settings – which simplifies and speeds up the data collection process compared to manual collection.
The main work Facepager is doing for you for getting the data, consists of three steps for every node:
- It assembles URLs from node data and the Query Setup.
- Data is requested from the web by using these URLs. You can see the URLs in the Status Log.
- The downloaded data is sliced up and put into the database as new nodes – ready for export or as new starting points for fetching data.
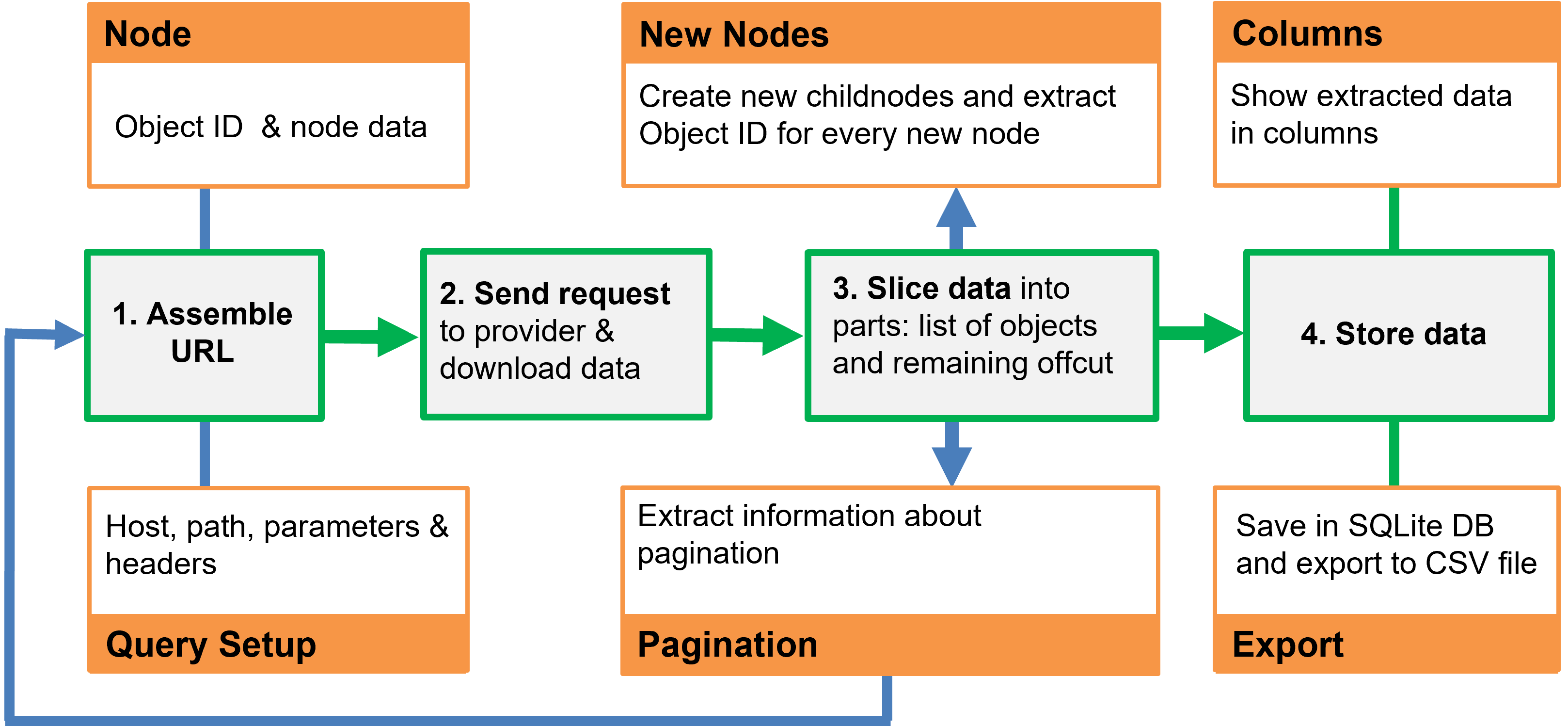
To understand the basic concepts of Facepager and use Facepager efficiently, it is worthwhile to look at some things:
- Learn about the underlying principle of Facepager: URLs and Placeholders and Extraction Keys
- Understand the Layout of the Main Window of Facepager.
- Be able to access data from different platforms through authorization via Login and Access Tokens.
- Learn about the fetching progress and its General Settings.
- Get a quick start to collecting data with the help of Presets.
- Get an idea of how to work with data exported from Facepager and have a look at the section Data analysis.