Cypher Query: Intermediate - srijan-singh/neo4j-lineage GitHub Wiki
Filtering Queries
Null
MATCH (m:Movie)
WHERE
m.tmdbId IS NULL
RETURN m
Range Query
MATCH (p:Person)
WHERE p:Actor AND p:Director
AND 1950 <= p.born.year < 1960
RETURN p.name, labels(p), p.born
List Inclusion
MATCH (m:Movie)
WHERE "German" IN m.languages
RETURN count(m)
String
STARTS WITH (Case Sensitive)
MATCH (p:Person)
WHERE p.name STARTS WITH 'Robert'
RETURN p.name
STARTS WITH (Case Insensitive)
MATCH (m:Movie)
WHERE toUpper(m.title) STARTS WITH 'LIFE IS'
RETURN m.title
CONTAINS
MATCH (p:Person)-[r]->(m:Movie)
WHERE toLower(r.role) CONTAINS "dog"
RETURN p.name, r.role, m.title
Query Patterns and Performance
A pattern is a combination of nodes and relationships that is used to traverse the graph at runtime. There are multiple ways to write a query that returns the same results. The difference in queries is typically its traversal performance.
Query 1: 1107 total db hits
PROFILE MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie)
WHERE exists {(p)-[:DIRECTED]->(m)}
RETURN p.name, labels(p), m.title
- MATCH Clause:
- Finds all nodes p with the label Person and property name = 'Tom Hanks'.
- Traverses the [:ACTED_IN] relationship to find connected m nodes with the label Movie.
- WHERE Clause:
- For each p-m pair found, checks if a [:DIRECTED] relationship exists between the same p and m.
- This involves additional sub-query execution (exists block), which adds complexity.
- RETURN Clause:
- Extracts and returns the name of p, the labels of p, and the title of m.
- DB Hits:
- 1107 hits. The exists sub-query adds significant overhead because it checks every potential p-m pair for an additional relationship, even when some pairs might not match.
Query 2: 105 total db hits
PROFILE MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(p)
RETURN p.name, labels(p), m.title
- MATCH Clause:
- Identifies nodes p with the label Person and property name = 'Tom Hanks'.
- Traverses the [:ACTED_IN] relationship to find connected m nodes with the label Movie.
- Further filters results by ensuring the same p node is also connected to m through a [:DIRECTED] relationship.
- RETURN Clause:
- Extracts and returns the name of p, the labels of p, and the title of m.
- DB Hits:
- 105 hits. This query avoids the overhead of the exists clause by explicitly specifying the additional relationship in the MATCH pattern. It processes fewer intermediate results.
Query 3: 43 total db hits
PROFILE MATCH (p:Person {name: "Tom Hanks"})-[:ACTED_IN & DIRECTED]->(m:Movie)
RETURN p.name, labels(p), m.title
- MATCH Clause:
- Identifies nodes p with the label Person and property name = 'Tom Hanks'.
- Directly finds m nodes with the label Movie connected via a relationship that has both types [:ACTED_IN] and [:DIRECTED].
- RETURN Clause:
- Extracts and returns the name of p, the labels of p, and the title of m.
- DB Hits:
- 43 hits. This is the most efficient query because it directly specifies the dual relationship type [:ACTED_IN & DIRECTED], avoiding unnecessary intermediate steps or checks.
OPTIONAL MATCH
- Query 1: Returns movies which are rated.
PROFILE MATCH (u:User)-[:RATED]->(m:Movie)-[:IN_GENRE]->(g:Genre {name: 'Film-Noir'})
RETURN COUNT(m)
- Query 2: Returns both rated and unrated movies.
PROFILE MATCH (m:Movie)-[:IN_GENRE]->(g:Genre {name: 'Film-Noir'})
OPTIONAL MATCH (u:User)-[:RATED]->(m)
RETURN COUNT(m)
Controlling Results Returned
ORDER BY
No limit on properties that can order in results.
MATCH (m:Movie)<-[ACTED_IN]-(p:Person)
WHERE m.imdbRating IS NOT NULL
RETURN m.title, m.imdbRating, p.name, p.born
ORDER BY m.imdbRating DESC, p.born DESC
CASE
MATCH (m:Movie)<-[:ACTED_IN]-(p:Person)
WHERE p.name = 'Charlie Chaplin'
RETURN m.title AS movie,
CASE
WHEN m.runtime < 120 THEN "Short"
ELSE "Long"
END AS runTime;
Working with Cypher Data
Aggregating Data
MATCH (director:Director)-[directed:DIRECTED]->(movie:Movie)
// Grouping nodes and relationship together to get desired result
RETURN director.name, count(directed) AS numberOfMovieDirected, collect(movie.title) AS movies
ORDER BY numberOfMovieDirected DESC
LIMIT 1
MATCH (actor:Actor)-[acted:ACTED_IN]->(movie:Movie)
// Grouping nodes and relationship together to get desired result
RETURN actor.name, collect(movie.title) AS movies
ORDER BY size(movies) DESC
LIMIT 1
MATCH (movie:Movie)<-[acted:ACTED_IN]-(actor:Actor)
// Grouping nodes and relationship together to get desired result
RETURN movie.title, collect(actor.name) AS actors
ORDER BY size(actors) DESC
LIMIT 1
MATCH (movie:Movie)<-[acted:ACTED_IN]-(actor:Actor)
// Grouping nodes and relationship together to get desired result
WITH movie.title AS movies, collect(actor.name) AS actors
WITH size(actors) AS totalCast
RETURN totalCast
ORDER BY totalCast DESC
LIMIT 1
Date and Time
Get current Date and Time
RETURN date(), datetime(), time()
Set Date and Time
MATCH (x:Test {id: 1})
SET x.date1 = date('2022-01-01'),
x.date2 = date('2022-01-15')
RETURN x
MATCH (x:Test {id: 1})
SET x.datetime1 = datetime('2022-01-04T10:05:20'),
x.datetime2 = datetime('2022-04-09T18:33:05')
RETURN x
Duration
between
MATCH (x:Test {id: 1})
RETURN duration.between(x.date1,x.date2)
MATCH (x:Test)
RETURN duration.between(x.datetime1,x.datetime2).minutes
inDays
MATCH (x:Test {id: 1})
RETURN duration.inDays(x.datetime1,x.datetime2).days
Format using apoc
MATCH (x:Test {id: 1})
RETURN x.datetime as Datetime,
apoc.temporal.format( x.datetime, 'HH:mm:ss.SSSS')
AS formattedDateTime
MATCH (x:Test {id: 1})
RETURN apoc.date.toISO8601(x.datetime.epochMillis, "ms")
AS iso8601
Graph Traversal
Basic query traversal
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = 'Eminem'
RETURN m.title AS movies
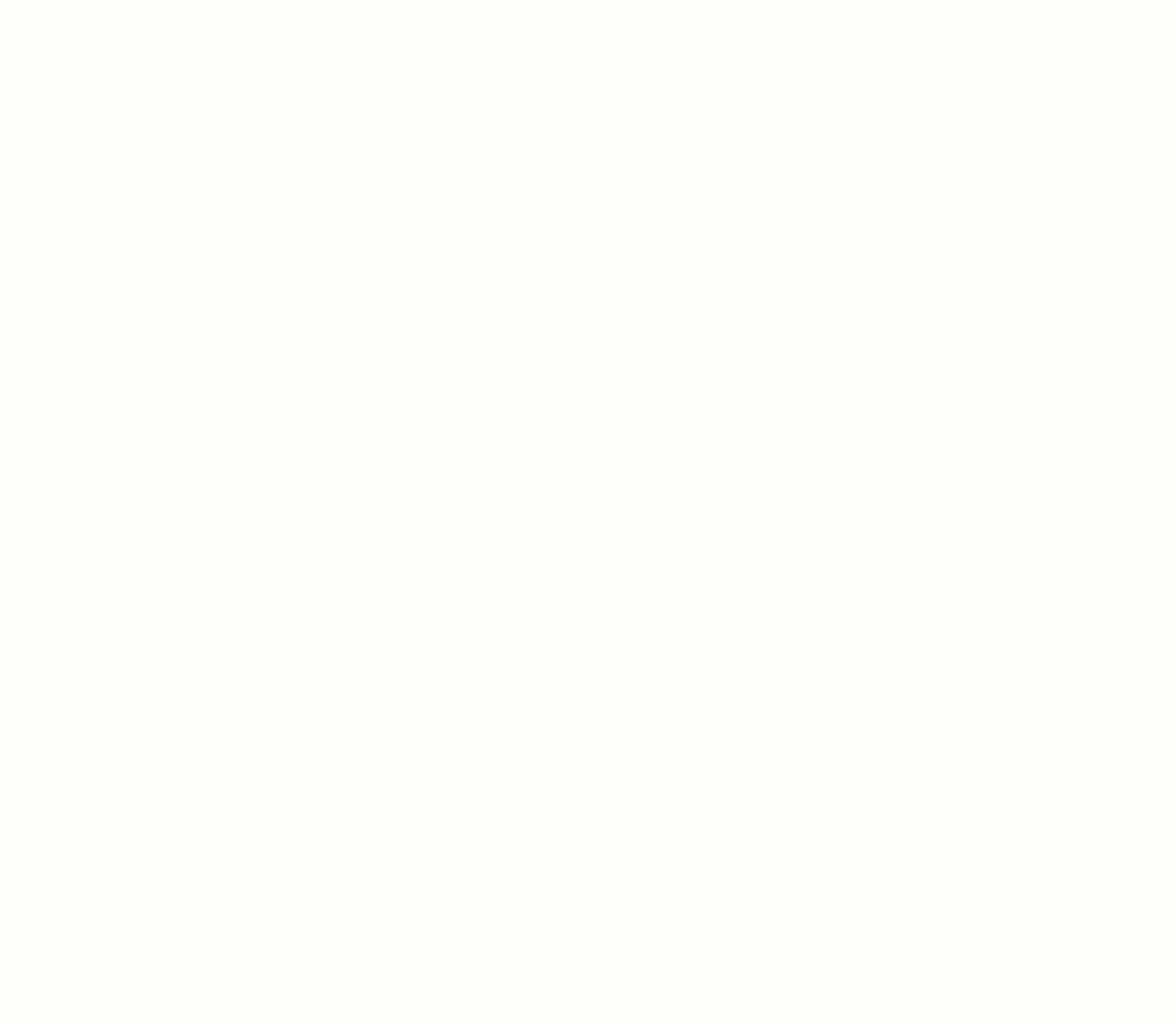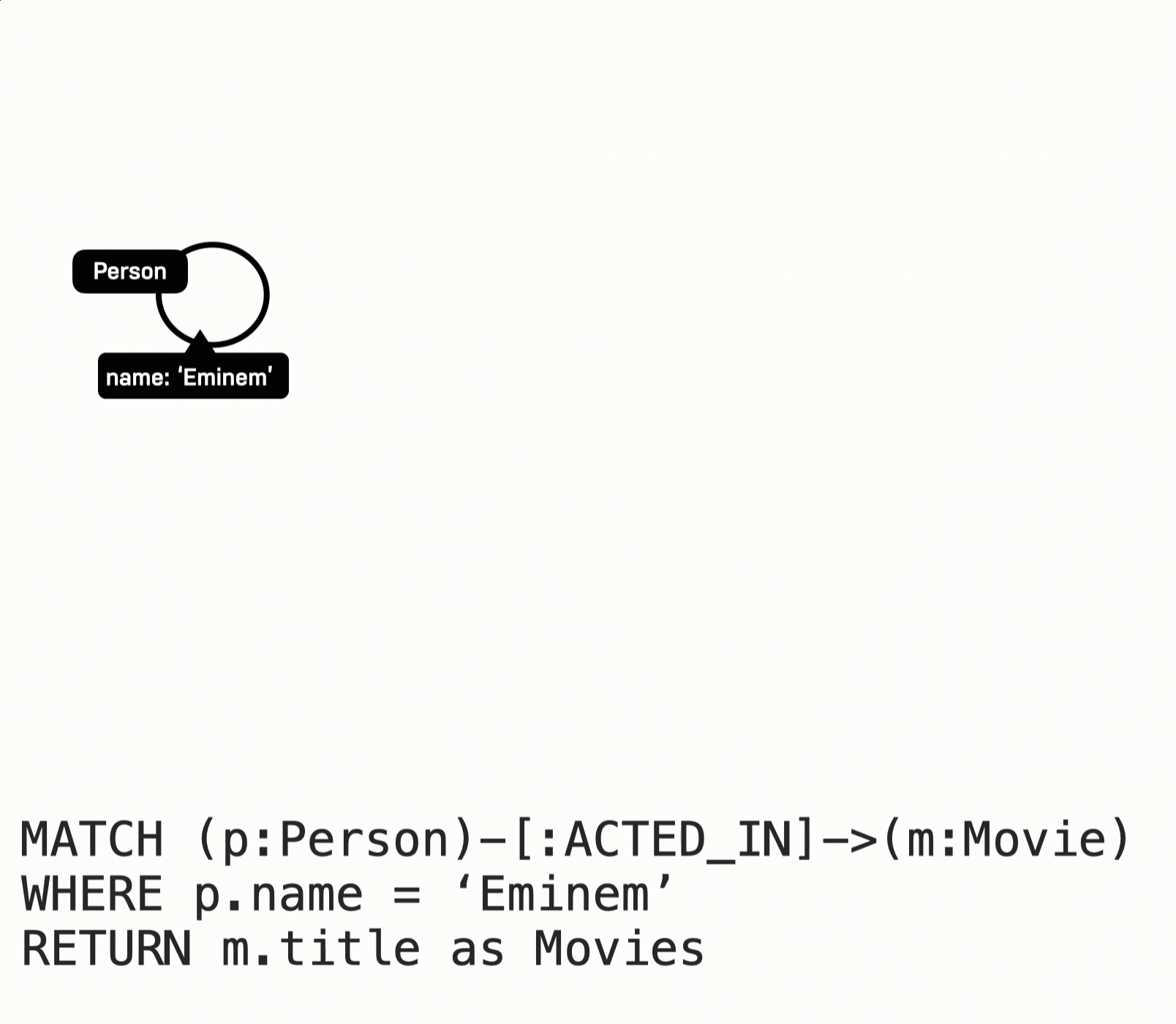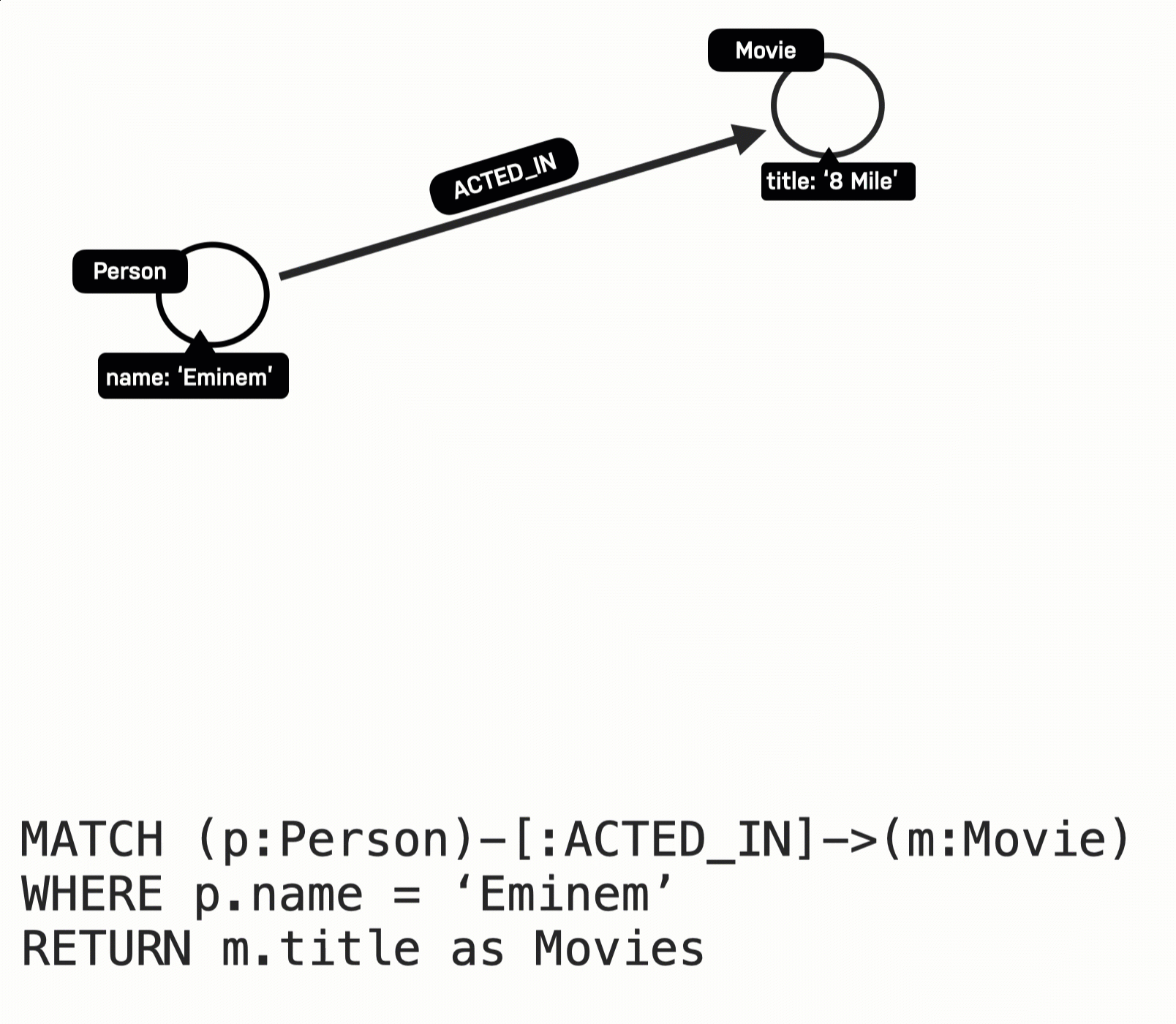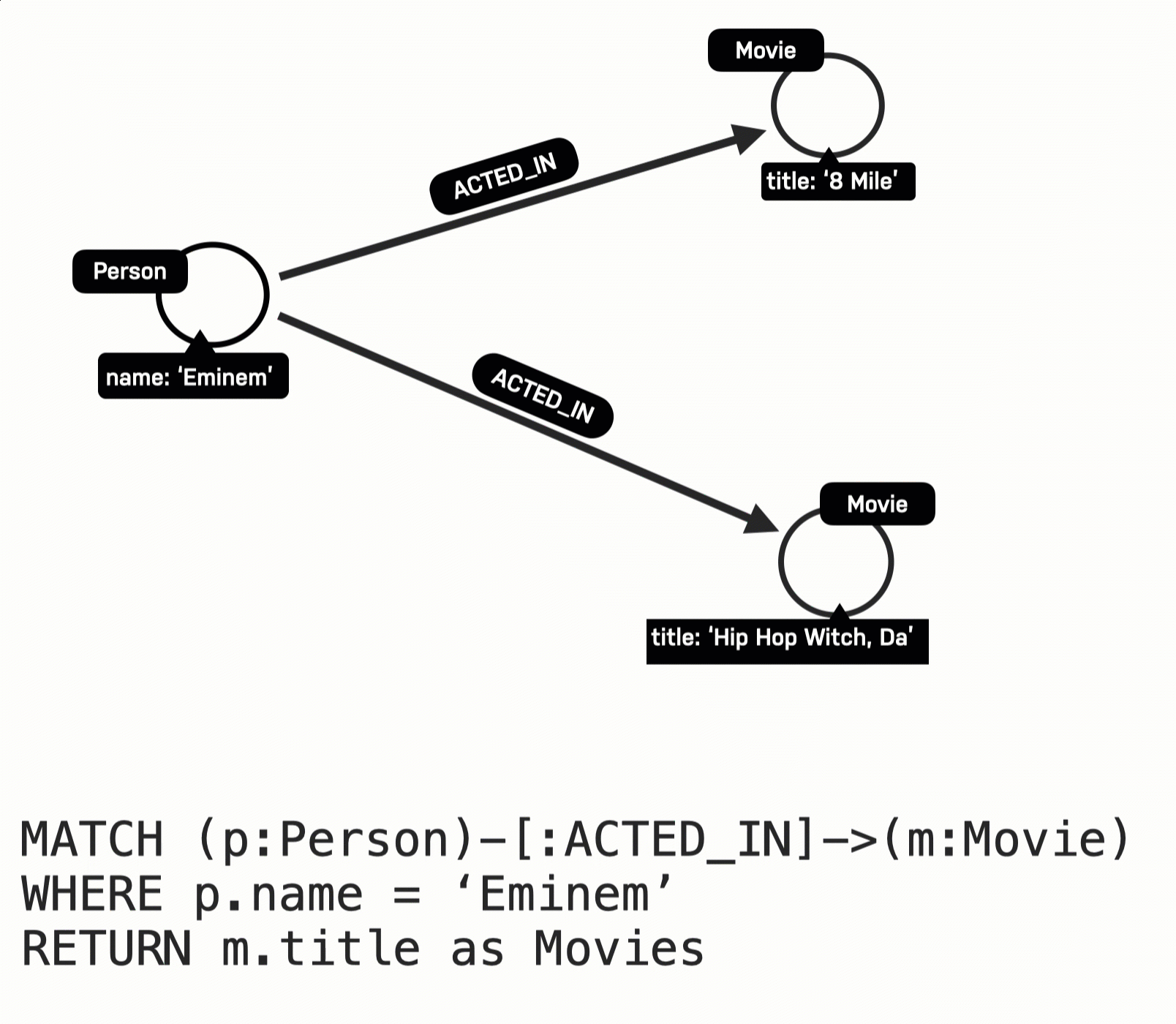
-
The Eminem Person node is retrieved.
-
Then the first ACTED_IN relationship is traversed to retrieve the Movie node for 8 Mile.
-
Then the second ACTED_IN relationship is traversed to retrieve the Movie node for Hip Hop Witch, Da.
-
The title property is retrieved so that the results can be returned.
Query traversal using multiple patterns
MATCH (p:Person)-[:ACTED_IN]->(m:Movie),
(coActors:Person)-[:ACTED_IN]->(m)
WHERE p.name = 'Eminem'
RETURN m.title AS movie ,collect(coActors.name) AS coActors
-
For the first pattern in the query, the Eminem Person node is retrieved.
-
Then the first ACTED_IN relationship is traversed to retrieve the Movie node for 8 Mile.
-
The second pattern in the query is then used.
-
Each ACTED_IN relationship to the same 8 Mile movie is traversed to retrieve three co-actors.
-
If the ACTED_IN relationship has been traversed already, it is not traversed again.
-
Then the second ACTED_IN relationship is traversed to retrieve the Movie node for Hip Hop Witch, Da.
-
Each ACTED_IN relationship to the same Hip Hop Witch, Da movie is traversed to retrieve three co-actors.
-
The title property for the Movie node is retrieved so that the results can be returned.
Anchor Node
The Person label for the anchor node retrieval is good here, but the label for the other side of the pattern is unnecessary. Having the label on the non-anchor node forces a label check, which is really not necessary.
PROFILE MATCH (p:Person)-[:ACTED_IN]->(m)
WHERE p.name = 'Tom Hanks'
RETURN m.title AS movie
Path
MATCH p = ((person:Person)-[]->(movie))
WHERE person.name = 'Walt Disney'
RETURN p
Hops
MATCH (p:Person {name: 'Robert Blake'})-[:ACTED_IN*4]-(others:Person)
RETURN DISTINCT others.name
MATCH (p:Person {name: 'Robert Blake'})-[:ACTED_IN*..4]-(others:Person)
RETURN DISTINCT others.name
MATCH (p:Person {name: 'Robert Blake'})-[:ACTED_IN*2..4]-(others:Person)
RETURN DISTINCT others.name
Pipelining Queries
WITH
MATCH (genre)<-[:IN_GENRE]-(movie:Movie)<-[:ACTED_IN]-(actor)
WHERE movie.imdbRating IS NOT NULL and movie.poster IS NOT NULL
WITH movie, collect(DISTINCT actor.name) as actorList, collect(DISTINCT genre.name) as genreList
WITH {
title: movie.title,
imdbRating: movie.imdbRating,
actors: actorList,
genre: genreList
} AS movieData
ORDER BY movieData.imdbRating DESC
LIMIT 4
RETURN collect(movieData)
- Optimized
MATCH (movie:Movie)
WHERE movie.imdbRating IS NOT NULL AND movie.poster IS NOT NULL
WITH movie {
.title,
.imdbRating,
actors: [ (movie)<-[:ACTED_IN]-(actor) | actor.name ],
genres: [ (movie)-[:IN_GENRE]->(genre) | genre.name ]
} AS movieData
ORDER BY movieData.imdbRating DESC
LIMIT 4
RETURN collect(movieData)
- Aggregation
WITH "Tom Hanks" AS tomHanks
MATCH (movie:Movie)<-[:ACTED_IN]-(actor)
WHERE actor.name = tomHanks
WITH movie as tomHanksMovie
MATCH (tomHanksMovie)<-[rated:RATED]-(user)
WITH tomHanksMovie, avg(rated.rating) AS averageUserRating
ORDER BY averageUserRating DESC
WITH DISTINCT tomHanksMovie LIMIT 4
RETURN tomHanksMovie.title