Csharp9 - shyoutarou/Exam-70-483_Csharp8_Csharp9 GitHub Wiki
Configurar com C# 9 é basicamente o mesmo que configurar com .NET Preview 5.
- Certifique-se de que sua versão do Visual Studio 2019 seja pelo menos 16.7 clicando em Help => Check For Updates dentro do Visual Studio. Em caso de dúvida, atualize.
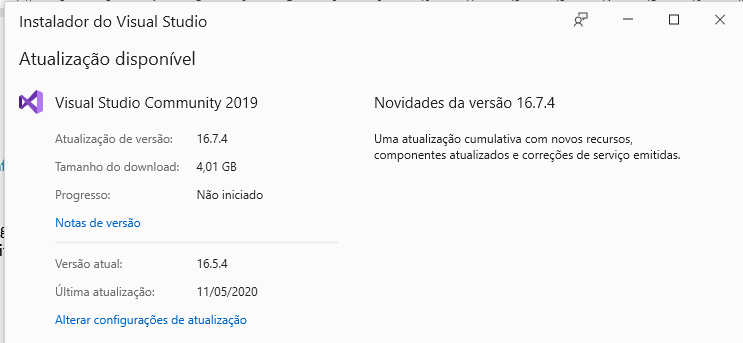
- Vá em Ferramentas => Opções dentro de Ambiente, selecione “Versão Prévia de recursos” e marque a caixa que diz “Usar versão prévia do SDK do .NET Core”. Em seguida, reinicie o Visual Studio.
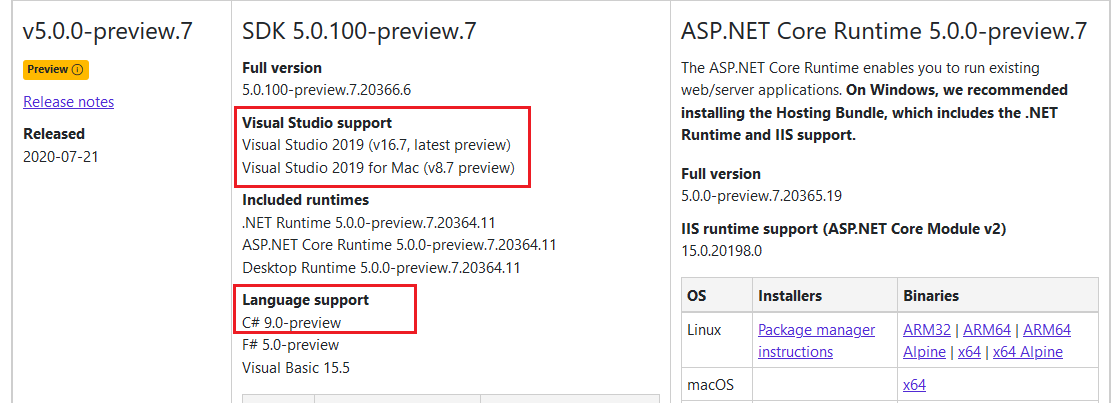
- Baixe e instale um SDK do .NET 5 compatível com a versão de VS 2019 instalada:
- Após a instalação, você pode executar o comando dotnet info em um prompt de comando: dotnet –info

Depois que o SDK do .NET 5 Preview estiver instalado e configurado. Para qualquer projeto existente que você deseja testar em execução no .NET 5 (por exemplo, um pequeno aplicativo de console), tudo o que você precisa fazer é brir o arquivo .csproj. Para abrir o arquivo de projeto * .csproj: Clique com o botão direito do mouse no Gerenciador de Soluções e escolha Editar Arquivo de Projeto.:
<Project Sdk = "Microsoft.NET.Sdk" >
<PropertyGroup>
<OutputType> Exe </OutputType>
<TargetFramework> netcoreapp3.1 </TargetFramework>
</PropertyGroup>
</Project>Para :
<Project Sdk = "Microsoft.NET.Sdk" >
<PropertyGroup>
<OutputType> Exe </OutputType>
<TargetFramework> net5.0 </TargetFramework>
<LangVersion> 9.0 </LangVersion>
</PropertyGroup>
</Project>Observe que alguns modelos, como aplicativos de console, não solicitam a versão do SDK ao criar um novo projeto, eles apenas usam o SDK mais recente disponível. Nesse caso, seu “padrão” para Visual Studio repentinamente se torna uma prévia do SDK do .NET Core.
Se você fez tudo isso e obteve um destes erros:
- Os assemblies de referência para .NET Framework, Version = v5.0 não foram encontrados.
- Opção inválida '9.0' para / langversion. Use '/ langversion :?' para listar os valores suportados.
Então aqui está sua lista de solução de problemas rápida e fácil:
- Tem certeza de que tem o SDK do .NET 5 mais recente instalado? Lembre-se de que é o SDK, não o runtime, e é .NET 5.
- Tem certeza de que o Visual Studio está atualizado? Mesmo se você tiver o SDK instalado, o Visual Studio segue suas próprias regras e precisa ser atualizado.
- Você está usando o Visual Studio 2019? Qualquer versão anterior não funcionará.
- Tem certeza de que ativou os SDKs de visualização? Lembre-se de Ferramentas => Opções e, em seguida, “Visualizar Recurso”
- Para rodar par Visual Studio 2019 version 16.8 e superior, requer o .NET 5 SDK preview 8. NoVisual Studio 2019 version 16.7 e superior, requer o .NET 5 SDK preview 7. O próprio SDK define um VS mínimo que ele suporta e não carregará nas versões do VS antes desse valor para evitar comportamento interrompido. Cada pré-lançamento contínuo do .NET e do SDK será enviado junto com um pré-lançamento do 16.8 VS com o qual são testados. Por exemplo, .NET 5 preview 8 fornecido com o Visual Studio preview 2. RC1 enviado com preview 3. Recomendamos que você use essas combinações juntas para teste, pois eles têm alguns componentes compartilhados e dependências que farão os cenários funcionarem melhor E2E.
| Releases | Visual Studio 2019 Preview |
|---|---|
| September 14, 2020 | version 16.8 Preview 3.1New release icon |
| August 31, 2020 | Visual Studio 2019 version 16.8 Preview 2.1 |
| August 25, 2020 | Visual Studio 2019 version 16.8 Preview 2 |
| August 5, 2020 | Visual Studio 2019 version 16.8 Preview 1 |
Uma nova versão de amostra do .NET 5/C# 9 é lançada a cada poucos meses. Portanto, se você estiver lendo sobre um novo recurso C# 9 ou .NET 5 que alguém está usando, mas parece que não consegue fazê-lo funcionar, volte sempre para https://dotnet.microsoft.com/download/dotnet/5.0 e baixe a última versão de visualização e instale. Semelhante ao Visual Studio, embora normalmente não seja um problema, tente mantê-lo atualizado, já que muitas vezes os recursos mais recentes que não funcionam são simplesmente porque estou em uma versão que estava perfeitamente bem um mês atrás, mas agora está desatualizada.
O C# 9 está lançando uma série de recursos somente init. Isso inclui propriedades somente init, acessadores init e campos somente leitura. Em C#, é comum declarar uma classe com getters e setters:
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
}Claro, você pode lançar um set privado lá para controle de acesso, mas suas opções normalmente são limitadas para seus getters e setters. No entanto, isso força a mutabilidade quando você executa a inicialização do objeto. Para que isso funcione, as propriedades devem ser mutáveis. Para definir valores em uma nova pessoa, você precisará chamar o construtor do objeto (neste caso, como na maioria dos casos, um construtor sem parâmetros) e, em seguida, executar a atribuição dos configuradores.
var person = new Person
{
FirstName = "Tony",
LastName = "Stark",
};E como isso é mutável, você pode fazer isso facilmente:
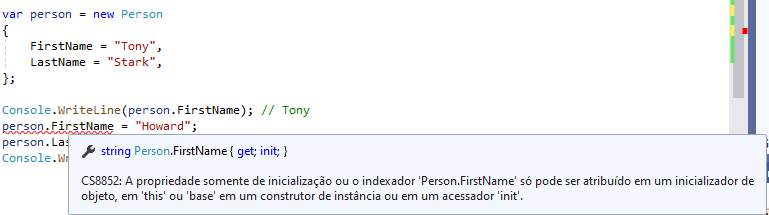
Console.WriteLine(person.FirstName); // Tony
person.FirstName = "Howard";
Console.WriteLine(person.FirstName); // HowardCom C# 9, podemos mudar isso com um acessador init. Variante do acessador set, um acessador init só pode ser chamado para propriedades e indexadores durante a inicialização do objeto, isso significa que você só pode criar e definir uma propriedade ao inicializar o objeto. Se modificarmos nosso modelo Person assim, podemos evitar que o FirstName seja alterado:
public class Person
{
public string FirstName { get; init; }
public string LastName { get; set; }
}Com essa declaração, essas propriedades são ReadOnly quando a construção é concluída, qualquer atribuição subsequente a propriedade FirstName é um erro.
Como os acessadores init só podem ser chamados durante a inicialização, eles têm permissão para modificar os campos somente leitura da classe envolvente, assim como você pode em um construtor. Você pode declarar setters somente init em qualquer tipo que você escreve. Com o uso de campos privados definirá um valor durante a inicialização - caso contrário, podemos lançar uma ArgumentNullException:
public class Person
{
private readonly string lastName;
public string FirstName { get; init; }
public string LastName
{
get => lastName;
init => lastName = (value ?? throw new ArgumentNullException(nameof(LastName)));
}
}Os setters somente init podem ser úteis para definir propriedades de classe base de classes derivadas. Eles também podem definir propriedades derivadas por meio de auxiliares em uma classe base. Registros posicionais declaram propriedades usando somente init setters. Esses setters são usados em expressões with. Você pode declarar setters somente init para qualquer um class ou struct.
O C# 9,0 apresenta tipos de registro, que são um tipo de referência que fornece métodos sintetizados para fornecer a semântica de valor para igualdade. Os registros são imutáveis por padrão. Imutabilidade é uma palavra com a simples premissa: uma vez instanciados ou inicializados, os tipos imutáveis nunca mudam. Por exemplo, System.DateTime é imutável, assim como strings.
Historicamente, os tipos .NET são classificados em grande parte como tipos de referência (incluindo classes e tipos anônimos) e tipos de valor (incluindo structs e tuplas). Embora tipos de valor imutáveis sejam recomendados, os tipos de valores mutáveis geralmente não introduzem erros. As variáveis de tipo de valor contêm os valores para que as alterações sejam feitas em uma cópia dos dados originais quando os tipos de valor são passados para métodos.
A imutabilidade é uma propriedade interessante, pois tende a simplificar a maneira como pensamos sobre um método. Um objeto imutável tem apenas um estado, o estado que você especificou quando criou o objeto. Quando algo é imutável, não precisamos nos preocupar se outra parte do aplicativo pode sofrer mutação. Elimina a necessidade de usar bloqueios e simplifica todas as partes altamente simultâneas do seu sistema. Essas vantagens são mais pronunciadas em programas simultâneos com dados compartilhados.
Os registros do C# 9.0 nos ajudarão a criar tipos imutáveis que são muito úteis em grandes arquiteturas distribuídas ao usar conceitos como mensagens e microsserviços, pois eles são seguros e thread-safe, sem necessidade de sincronização. Dito de outra forma: tipos imutáveis reduzem o risco, são mais seguros e ajudam a prevenir muitos bugs desagradáveis que ocorrem quando você atualiza seus objetos.
Você poderia simular a imutabilidade com structs e até mesmo classes, mas a ideia é ter uma construção que seja simples e direta de implementar. Um dos maiores difereciais de registros sobre estruturas é a reduzida alocação de memória necessária. Como os registros C# são compilados para referenciar tipos nos bastidores, eles são acessados por uma referência e não como uma cópia. Como resultado, nenhuma alocação de memória adicional é necessária além da alocação de registro original. É imutável, pois nenhuma das propriedades pode ser modificada depois de ser criada. Quando você define um tipo de registro, o compilador sintetiza vários outros métodos para você:
- Copiar e clonar Membros
- Métodos para comparações de igualdade com base em valor como Equals(objeto), IEquatable
- Override de GetHashCode()
- PrintMembers e ToString()
- Método Construct/Deconstruct com registros posicionais simplificados
Os registros fornecem uma declaração de tipo para um tipo de referência imutável que usa semântica de valor para igualdade. Os métodos sintetizados para códigos de igualdade e hash consideram dois registros iguais se suas propriedades forem iguais. Considere esta definição:
public record Person
{
public string LastName { get; }
public string FirstName { get; }
public Person(string first, string last) => (FirstName, LastName) = (first, last);
}A definição de registro cria um tipo Person que contém duas propriedades ReadOnly: FirstName e LastName. O tipo Person é um tipo de referência. O Registro tem também suporte à herança.
- Os registros não podem herdar de classes, a menos que a classe seja object
- Classes não podem herdar de registros.
- Os registros podem ser herdados de outros registros. Você pode declarar um novo registro derivado do da Person seguinte maneira:
public record Teacher : Person
{
public string Subject { get; }
public decimal Price { get; }
public Teacher(string first, string last, string sub, decimal price)
: base(first, last) => (Subject, Price) = (sub, price);
}Você também pode criar registros selados para evitar uma maior derivação:
public sealed record Student : Person
{
public int Level { get; }
public Student(string first, string last, int level)
: base(first, last) => Level = level;
}O compilador sintetiza versões diferentes dos métodos acima. As assinaturas de método dependem de se o tipo de registro é selada e se a classe base direta é Object.
Os registros dão suporte à construção de cópia. A construção correta da cópia deve incluir hierarquias de herança e propriedades adicionadas por desenvolvedores. Os registros podem ser copiados com modificações. Essas operações de cópia e modificação oferecem suporte a mutação não destrutiva. Um tipo de registro contém dois membros de cópia:
- Um construtor que assume um único argumento do tipo de registro. Ele é chamado de "Construtor de cópia".
- Um método de "clonagem" de instância pública resumida com um nome reservado de compilador. O método "clone" sintetizado oferece suporte à construção de cópias para hierarquias de registros. O termo "clone" está entre aspas porque o nome real é gerado pelo compilador. Você não pode criar um método denominado Clone em um tipo de registro.
A finalidade do construtor de cópia é copiar o estado do parâmetro para a nova instância que está sendo criada. Esse construtor não executa nenhum campo de instância/inicializadores de propriedade presentes na declaração de registro. Se o construtor não for declarado explicitamente, um construtor será sintetizado pelo compilador. Se o registro estiver selado, o Construtor será privado, caso contrário, ele será protegido.
Vamos supor que em algum momento você deseje criar esse novo objeto Friend e precise alterar o sobrenome desse amigo para Mueller. Observe a atribuição do valor da propriedade FirstName e Middlename do primeiro objeto Friend às propriedades do segundo objeto Friend:
public class Friend
{
public string FirstName { get; init; }
public string MiddleName { get; init; }
public string LastName { get; init; }
}
var friend = new Friend
{
FirstName = "Thomas",
MiddleName = "Claudius",
LastName = "Huber"
};
var newFriend = new Friend
{
FirstName = friend.FirstName,
MiddleName = friend.MiddleName,
LastName = "Mueller"
};Você deve copiar todas as propriedades do antigo objeto Friend. Isso significa que quanto mais propriedades você tem, mais difícil fica. Claro que você pode implementar alguma lógica de cópia com reflexão ou serialização, ou pode usar uma biblioteca de mapeamento automático. Mas o C# 9.0 tem uma maneira melhor de trabalhar com classes de dados imutáveis: Registros.
Os registros têm suporte expressões with. Uma expressão with instrui o compilador a criar uma cópia de um registro, mas com as propriedades especificadas modificadas:
- Uma expressão with não é permitida como uma instrução.
- Uma expressão with permite uma "mutação não destrutiva", projetada para produzir uma cópia da expressão do destinatário com modificações em atribuições no inicializador de objeto para indicar o que é diferente no novo objeto do antigo.
- Um expressão a with válida tem um receptor com um tipo não void. O tipo de receptor deve ser um registro.
- No lado direito da with expressão, há uma lista de inicializador de objeto com uma sequência de atribuições para o identificador, que deve ser um campo de instância acessível ou Propriedade do tipo do destinatário.
Um registro define implicitamente um "construtor de cópia" protegido - um construtor que pega um objeto de registro existente e o copia campo por campo para o novo. Em seguida, cada inicializador de objeto é processada da mesma forma que uma atribuição para um campo ou acesso de Propriedade do resultado da conversão. As atribuições são processadas na ordem léxica.
Person person2 = new Teacher("Bill", "Wagner", "Math", 11.99m);
var newperson2 = person2 with { LastName = "VideoGame" };
Console.WriteLine("Type: " + newperson2.GetType().Name); //Type: Teacher
Console.WriteLine("FirstName: " + newperson2.FirstName); //FirstName: Bill
Console.WriteLine("LastName: " + newperson2.LastName); //LastName: VideoGame
//Console.WriteLine("Subject: " + newperson2.Subject);
//Console.WriteLine("Price: " + newperson2.Price);A linha acima cria um novo Person registro no qual a LastName propriedade é uma cópia de Person e o FirstName é "Bill". Você pode definir qualquer número de propriedades em uma expressão with. Qualquer um dos membros sintetizados, exceto o método "clone", pode ser escrito por você. Se um tipo de registro tiver um método que corresponda à assinatura de qualquer método sintetizado, o compilador não sintetizará esse método.
Podemos retornar ao tipo original Teacher fazendo o cast do tipo:
var teacher2 = (Teacher)newperson2; //available after casting
Console.WriteLine("Type: " + teacher2.GetType().Name); //Type: Teacher
Console.WriteLine("FirstName: " + teacher2.FirstName); //FirstName: Bill
Console.WriteLine("LastName: " + teacher2.LastName); //LastName: VideoGame
Console.WriteLine("Subject: " + teacher2.Subject); //Subject: Math
Console.WriteLine("Price: " + teacher2.Price); //Price: 11,99O método "clone" sintetizado retorna o tipo de registro que está sendo copiado usando o envio virtual. O compilador adiciona modificadores diferentes para o método "clone" dependendo dos modificadores de acesso no registro:
- Se o tipo de registro for abstrato, o método "clone" também será abstrato. Se o tipo base não for objeto, o método também será sobrescrito.
- Para tipos de registro que não são abstratos quando o tipo base é objeto:
- Se o registro for selado, nenhum modificador adicional será adicionado ao método "clone" (o que significa que não é virtual).
- Se o registro não estiver selado, o método "clone" é virtual.
- Para tipos de registro que não são abstratos quando o tipo base não é objeto:
- Se o registro estiver selado, o método "clone" também será selado.
- Se o registro não estiver selado, o método "clone" será substituído.
A igualdade é baseada em valor e inclui uma verificação de que os tipos correspondem. Por exemplo, um Student não pode ser igual a a Person, mesmo que os dois registros compartilhem o mesmo nome. Tecnicamente os registros são um tipo de classe, o que também significa que são tecnicamente, tipos de referência. Todos os objetos herdam um método virtual Equals (objeto) da classe de objeto. Isso é usado como base para o método estático Object.Equals (objeto, objeto) quando ambos os parâmetros são não nulos. Como structs, os registros fozem override do método Equals (objeto) que cada classe tem, para alcançar o valor que buscamos. Structs sobrescrevem isso para ter “igualdade baseada em valor”, comparando cada campo da struct chamando Equals neles recursivamente. Os registros fazem o mesmo. Isso significa que, de acordo com seu “valor”, dois objetos de registro podem ser iguais um ao outro sem serem o mesmo objeto. Por exemplo, se modificarmos o sobrenome da pessoa modificada novamente:
var originalPerson = otherPerson with { LastName = "Hunter" };Teríamos agora ReferenceEquals (person, originalPerson) = false (eles não são o mesmo objeto), mas Equals (person, originalPerson) = true (eles têm o mesmo valor).
var person = new Person("Tony", "Stark", "10880 Malibu Point", "Malibu", "red");
var newPerson = person with { FirstName = "Howard", City = "Pasadena" };
Console.WriteLine(Object.ReferenceEquals(person, newPerson)); // false
Console.WriteLine(Object.Equals(person, newPerson)); // false
var anotherPerson = newPerson with { FirstName = "Tony", City = "Malibu" };
Console.WriteLine(Object.ReferenceEquals(person, anotherPerson)); // false
Console.WriteLine(Object.Equals(person, anotherPerson)); // trueIsso significa que também podemos trabalhar com igualdade baseada em valores. Por exemplo, se criarmos dois novos objetos, sabemos que eles têm referências diferentes na memória, então uma chamada ReferenceEquals (ou mesmo uma chamada ==) retornará falso mesmo se eles tiverem os mesmos valores. Isso é diferente de structs - porque structs são tipos de valor, isso não ocorrerá. Com os registros, compararemos valores. Observe o que acontece enquanto: 1- Crie uma nova pessoa chamada pessoa, Tony Stark 2- Crie outra pessoa, chamada newPerson, Howard Stark, com duas propriedades diferentes (nome e cidade) 3- Crie uma terceira pessoa chamada anotherPerson e defina anotherPerson com os mesmos valores da pessoa original
Repare que está indicando erro. Isso porque em nossas propriedades temos:
public record Person
{
public string LastName { get; }
public string FirstName { get; }
public string Address;
public string City;
public string FavoriteColor;
}
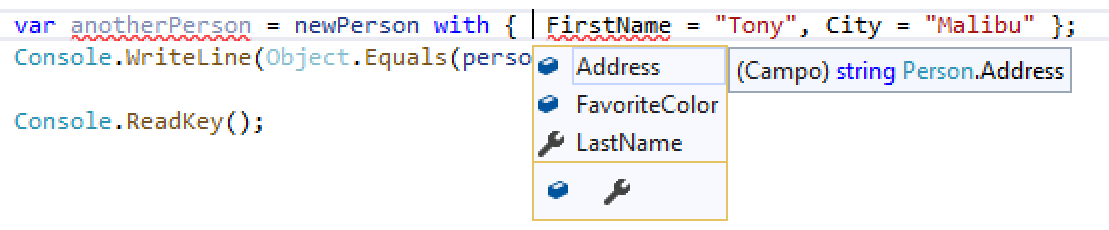
Alguns são campos, outros propriedade... Mas está havendo erro ao setar o valor a uma propriedade. Para corrigir isso temos que utilizar init:
public record Person
{
public string FirstName { get; init; }
public string LastName { get; init; }
public string Address { get; init; }
public string City { get; init; }
public string FavoriteColor { get; init; }
}Se você não gosta do comportamento de comparação campo por campo padrão da substituição Equals gerada, você pode escrever o seu próprio. Você só precisa ter cuidado para entender como a igualdade baseada em valores funciona em registros, especialmente quando a herança está envolvida.
Junto com Equals baseado em valor, há também uma substituição GetHashCode() baseada em valor para acompanhá-lo.
public record Teacher : Person, IEquatable { public string Subject { get; init; } public decimal Price { get; init; }
public void Teachclass() => Console.WriteLine("It's class teaching time");
public bool Equals([AllowNull] Person other)
{
throw new NotImplementedException();
}
public Teacher(string first, string last, string sub, decimal price)
: base(first, last) => (Subject, Price) = (sub, price);
}
public override int GetHashCode() { return Combine(EqualityComparer.Default.GetHashCode(EqualityContract), EqualityComparer.Default.GetHashCode(P1)); }
public static bool operator !=(Person r1, Person r2) { return !(r1 == r2); }
public static bool operator ==(Person r1, Person r2) { return (object)r1 == r2 || (r1?.Equals(r2) ?? false); }
Além das sobrecargas Equals conhecidas, operator == e operator != , o compilador sintetiza uma nova propriedade EqualityContract. A propriedade retorna um Type objeto que corresponde ao tipo do registro.
- Se o tipo base for object, a propriedade será virtual.
- Se o tipo base for outro tipo de registro, a propriedade será um override.
- Se o tipo de registro for sealed, a propriedade será sealed.
product2 “pode pensar” product1 é o mesmo porque irá comparar propriedades compartilhadas (Name e CategoryId), mas product1 pode pensar que product2 é diferente porque há uma propriedade ausente (ISBN).
EqualityContract existe para “arbitrar um consenso”, então product1.Equals (product2) e product2.Equals (product1) devem retornar false;
using System.Runtime.CompilerServices;
protected virtual Type EqualityContract
{
[CompilerGenerated]
get
{
return typeof(Person);
}
}A igualdade é implementada consistentemente em qualquer hierarquia de tipos de registro. Dois registros são iguais entre si se suas propriedades forem iguais e seus tipos forem os mesmos, conforme mostrado no exemplo a seguir:
var person = new Person("Bill", "Wagner");
var student = new Student("Bill", "Wagner", 11);
Console.WriteLine(student == person); // falseOs registros têm uma representação de numérica gerada.
var person = new Person("Bill", "Wagner");
var student = new Student("Bill", "Wagner", 11);
Console.WriteLine(student.GetHashCode()); // -2031643194
Console.WriteLine(person.GetHashCode()); // 327587142O sintetizado GetHashCode usa o GetHashCode de todas as propriedades e campos declarados no tipo base e no tipo de registro. Esses métodos sintetizados impõem a igualdade baseada em valor em uma hierarquia de herança. Isso significa que um Student nunca será considerado igual a um Person com o mesmo nome. Os tipos dos dois registros devem corresponder e todas as propriedades compartilhadas entre os tipos de registro são iguais.
public override int GetHashCode()
{
return ((EqualityComparer<Type>.Default.GetHashCode(EqualityContract) * -1521134295
+ EqualityComparer<string>.Default.GetHashCode(FirstName)) * -1521134295
+ EqualityComparer<string>.Default.GetHashCode(Address)) * -1521134295
+ EqualityComparer<string>.Default.GetHashCode(LastName);
}O compilador sintetiza dois métodos que dão suporte à saída impressa:
- Override do ToString()
- PrintMembers
O PrintMembers usa System.Text.StringBuilder como argumento. Ele acrescenta uma lista separada por vírgulas de nomes de propriedade e valores para todas as propriedades no tipo de registro. PrintMembers chama a implementação de base para todos os registros derivados de outros registros. O override do ToString() retorna a cadeia de caracteres produzida por PrintMembers , cercada por { e } .
public record Person
{
string LastName { get; }
string FirstName { get; }
public void TakeNotes() => Console.WriteLine("It's note taking time");
public Person(string first, string last) => (FirstName, LastName) = (first, last);
protected virtual bool PrintMembers(StringBuilder builder)
{
builder.Append("FirstName");
builder.Append(" = ");
builder.Append((object)FirstName);
builder.Append(", ");
builder.Append("LastName");
builder.Append(" = ");
builder.Append((object)LastName);
return true;
}
public override string ToString()
{
var builder = new StringBuilder();
builder.Append(nameof(Person));
builder.Append(" { ");
if (PrintMembers(builder))
builder.Append(" ");
builder.Append("}");
return builder.ToString();
}
}
public record Teacher : Person
{
public string Subject { get; }
public decimal Price { get; }
public void Teachclass() => Console.WriteLine("It's class teaching time");
protected override bool PrintMembers(StringBuilder builder)
{
if (base.PrintMembers(builder))
builder.Append(", ");
builder.Append(nameof(Subject));
builder.Append(" = ");
builder.Append(this.Subject); // or builder.Append(this.P2); if P2 has a value type
builder.Append(", ");
builder.Append(nameof(Price));
builder.Append(" = ");
builder.Append(this.Price); // or builder.Append(this.P3); if P3 has a value type
return true;
}
public override string ToString()
{
var builder = new StringBuilder();
builder.Append(nameof(Teacher));
builder.Append(" { ");
if (PrintMembers(builder))
builder.Append(" ");
builder.Append("}");
return $"{builder.ToString()} is a Class";
}
public Teacher(string first, string last, string sub, decimal price)
: base(first, last) => (Subject, Price) = (sub, price);
}
public sealed record Student : Person
{
public int Level { get; }
protected override bool PrintMembers(StringBuilder builder)
{
if (base.PrintMembers(builder))
builder.Append(", ");
builder.Append(nameof(Level));
builder.Append(" = ");
builder.Append(this.Level);
return true;
}
public override string ToString()
{
var builder = new StringBuilder();
builder.Append(nameof(Student));
builder.Append(" { ");
if (PrintMembers(builder))
builder.Append(" ");
builder.Append("}");
return $"{builder.ToString()}";
}
public Student(string first, string last, int level)
: base(first, last) => Level = level;
}Por exemplo, o método ToString() retorna um string semelhante ao seguinte código:
var person = new Person("Bill", "Wagner");
var student = new Student("Jean", "Woo", 11);
//Person { FirstName = Bill, LastName = Wagner }
Console.WriteLine(person.ToString());
//Student { FirstName = Jean, LastName = Woo, Level = 11 }
Console.WriteLine(student.ToString());
var teacher = new Teacher("Mike", "Todd", "Math", 11.99m);
//Teacher { FirstName = Mike, LastName = Todd, Subject = Math, Price = 11,99 } is a Class
Console.WriteLine(teacher.ToString());Os registros também têm um Construtor sintetizado e um método de "clonagem" para a criação de cópias. O Construtor sintetizado tem um argumento do tipo de registro. Ele produz um novo registro com os mesmos valores para todas as propriedades do registro. Esse construtor é private se o registro estiver selado, caso contrário, será protect.
Todos os registros dão suporte à desconstrução. O compilador produz um Deconstruct método para registros posicionais.
public record Person
{
public string LastName { get; }
public string FirstName { get; }
public string Address;
public string City;
public string FavoriteColor;
public Person(string firstName, string lastName, string address, string city, string favoriteColor)
=> (FirstName, LastName, Address, City, FavoriteColor) = (firstName, lastName, address, city, favoriteColor);
public Person(string first, string last) => (FirstName, LastName) = (first, last);
public void Deconstruct(out string firstName, out string lastName, out string address,
out string city, out string favoriteColor)
=> (firstName, lastName, address, city, favoriteColor) = (FirstName, LastName, Address, City, FavoriteColor);
}O Deconstruct método tem parâmetros que correspondem aos nomes de todas as propriedades públicas no tipo de registro. O Deconstruct método pode ser usado para desconstruir o registro em suas propriedades de componente:
var person = new Person("Bill", "Wagner");
var (first, last, address, city, color) = person;
Console.WriteLine(person.FirstName); // Bill
Console.WriteLine(person.LastName); // Wagner
Console.WriteLine(first); // Bill
Console.WriteLine(last); // Wagner
Console.WriteLine(address); //
Console.WriteLine(city); //
Console.WriteLine(color); //
var hero = new Person("Tony", "Stark", "10880 Malibu Point", "Malibu", "red");
var (firsth, lasth, addressh, cityh, colorh) = hero;
Console.WriteLine(hero.FirstName); // Tony
Console.WriteLine(hero.LastName); // Stark
Console.WriteLine(firsth); // Tony
Console.WriteLine(lasth); // Stark
Console.WriteLine(addressh); // 10880 Malibu Point
Console.WriteLine(cityh); // Malibu
Console.WriteLine(colorh); // red
Console.ReadKey();Os exemplos mostrados até agora usam a sintaxe tradicional para declarar Propriedades. Há uma forma mais concisa chamada registros posicionais. Aqui estão os três tipos de registro definidos anteriormente como registros posicionais:
public record Person2(string FirstName, string LastName);
public record Teacher2(string FirstName, string LastName, string Subject, decimal Price) : Person(FirstName, LastName);
public sealed record Student2(string FirstName, string LastName, int Level) : Person(FirstName, LastName);Os Registros posicionais, permite uma sintaxe mais curta por uma posição específica de membros: e torna as propriedades FirstName e LastName registro imutável e sua atribuição de valor é determinada por sua posição. A construção (por posição) e a desconstrução (por posição) funcionarão bem com a sintaxe que você já conhece nas versões anteriores do C#.
Essas declarações criam a mesma funcionalidade da versão anterior. Essas declarações terminam com um ponto e vírgula em vez de colchetes porque esses registros não adicionam outros métodos. Você pode adicionar um corpo e também incluir outros métodos:
public record Person
{
string LastName { get; }
string FirstName { get; }
public void TakeNotes() => Console.WriteLine("It's note taking time");
public Person(string first, string last) => (FirstName, LastName) = (first, last);
protected virtual bool PrintMembers(StringBuilder builder)
{
builder.Append("FirstName");
builder.Append(" = ");
builder.Append((object)FirstName);
builder.Append(", ");
builder.Append("LastName");
builder.Append(" = ");
builder.Append((object)LastName);
return true;
}
public override string ToString()
{
var builder = new StringBuilder();
builder.Append(nameof(Person));
builder.Append(" { ");
if (PrintMembers(builder))
builder.Append(" ");
builder.Append("}");
return builder.ToString();
}
}
public record Teacher : Person
{
public string Subject { get; }
public decimal Price { get; }
public void Teachclass() => Console.WriteLine("It's class teaching time");
public Teacher(string first, string last, string sub, decimal price)
: base(first, last) => (Subject, Price) = (sub, price);
}Quando criamos um novo aplicativo de console C#, é criado esta estrutura:
using System;
namespace C9_TopLevel
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
}
}
}Imagine que você está tentando ensinar a alguém como um programa funciona. Antes mesmo de executar uma linha de código, você precisa falar sobre:
- O que são declarações using e por que precisamos de referência a System?
- O que são namespace, é somente o nome do programa?
- O que é uma classe?
- O que é uma função, static, void?
- O que são parâmetros, o que é uma matriz de string args?
Dificultando o entendimento para novos programadores, especialmente se comparado a linguagens Python ou JavaScript. As instruções de nível superior removem a cerimônia desnecessária de muitos aplicativos, se você quisesse um programa de uma linha, poderia remover todo o código e colocar a diretiva using de modo totalmente qualificado:
System.Console.WriteLine("Hello World!");Se você olhar o que Roslyn gera, a partir do Sharplab:
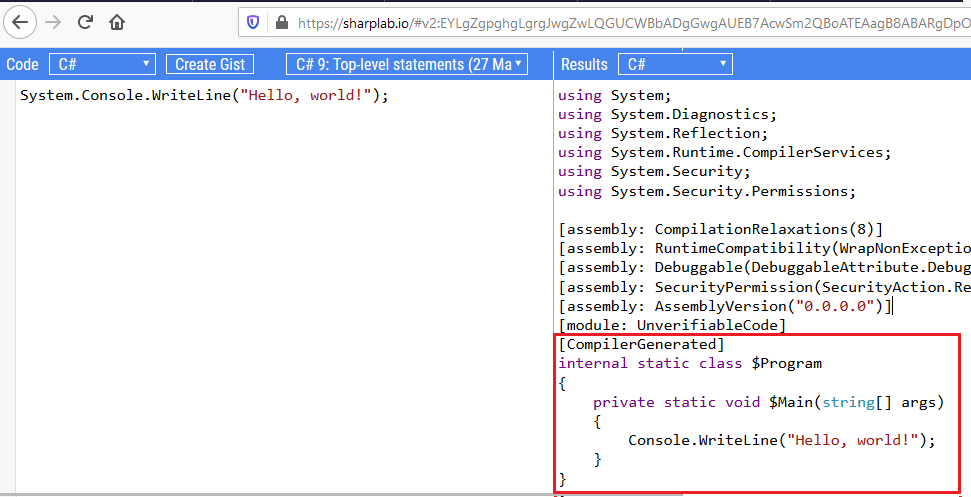
Ele irá gerar uma classe de programa e o método principal tradicional para você. Somente um arquivo em seu aplicativo pode usar instruções de nível superior. Se o compilador encontrar instruções de nível superior em vários arquivos de origem, será um erro. Também será um erro se você combinar instruções de nível superior com um método de ponto de entrada de programa declarado, normalmente um Main método. De certa forma, você pode imaginar que um arquivo contém as instruções que normalmente estaria no Main método de uma Program classe.
Um dos usos mais comuns para esse recurso é a criação de materiais de ensino. No entanto, os desenvolvedores experientes também encontrarão muitos usos para esse recurso. As instruções de nível superior permitem uma experiência semelhante a um script para experimentação semelhante ao que os notebooks Jupyter fornecem. As instruções de nível superior são ótimas para pequenos programas de console e utilitários. O Azure Functions é um caso de uso ideal para instruções de nível superior.
O mais importante é que as instruções de nível superior não limitam o escopo ou a complexidade do aplicativo. Essas instruções podem:
- Acessar ou usar qualquer classe .NET.
- Normalmente, isso é feito analisando os acessar uma matriz de cadeias de caracteres denominadas args[] que você passa para o método Main como vimos anteriormente. Agora os args estão disponíveis como um parâmetro oculto, o que significa que você deve ser capaz de acessá-los sem transmiti-los. Digamos que eu quisesse algo assim:
var param1 = args[0];
var param2 = args[1];
System.Console.WriteLine($"Your params are {param1} and {param2}.");
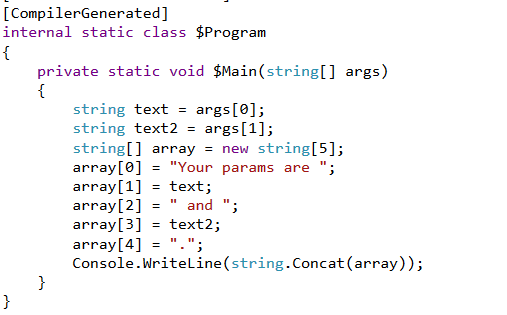
- Não limitam o uso de valores de retorno. Se retornarem um valor inteiro, esse valor se tornará o código de retorno de inteiro de um método sintetizado Main.
System.Console.WriteLine("Hello, world!");
return 0;- Podem conter expressões assíncronas utilizando await.
using (var httpClient = new HttpClient())
{
httpClient.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("text/plain"));
Console.WriteLine(httpClient.GetStringAsync(new Uri("http://www.microsoft.com")).Result);
}
Se as expressões assíncronas retorna um Task, ou Task.
async System.Threading.Tasks.Task<string> AwaitableMethodAsync()
{
using (var httpClient = new System.Net.Http.HttpClient())
{
httpClient.DefaultRequestHeaders.Accept.Add(new System.Net.Http.Headers.MediaTypeWithQualityHeaderValue("text/plain"));
string tarefa = await httpClient.GetStringAsync(new System.Uri("http://www.microsoft.com"));
return tarefa;
}
}
var textao = await AwaitableMethodAsync();
System.Console.WriteLine(textao);Se você olhar o que Roslyn gera, a partir do Sharplab, temos um extenso código que utiliza um TaskAwaiter e um AsyncStateMachine.
Este não é um recurso completamente novo, mas algo que evoluiu desde que foi lançado no C# 7, embora na forma básica. A correspondência de padrões melhorou muito no C# 8, com o operador is e com expressões de switch. O C# 9 inclui novas melhorias de correspondência de padrões, muitos deles são baseados na sintaxe de switch aprimorada do C# 8.
string languagePhrase = languageInput switch
{
"C#" => "C# is fun!",
"JavaScript" => "JavaScript is mostly fun!",
_ => throw new Exception("You code in something else I don't recognize."),
};A correspondência de padrões permite que você simplifique os cenários em que é necessário gerenciar de forma coesa os dados de diferentes fontes. Um exemplo óbvio é quando você chama uma API externa onde você não tem nenhum controle sobre os tipos de dados que está recebendo. Claro, normalmente você criaria tipos em seu aplicativo para todos os diferentes tipos que poderia obter dessa API. Então, você construiria um modelo de objeto a partir desses tipos. Imagine se você estiver trabalhando com várias APIs. Partindo de um código C# 8 switch:.
var person = new Person
{
FirstName = "Tony",
LastName = "Ramos",
Age = 45
};
string Switch_C8(object pessoa) => pessoa switch
{
Person s when s.Age < 10 => "Criança",
Person s when s.Age <= 40 => "Adulto",
Person _ => "Senior",
_ => throw new ArgumentException("I do not know this one", nameof(pessoa))
};
Console.WriteLine(Switch_C8(person)); "Senior"A correspondência de padrões pode ser usado em qualquer contexto em que os padrões são permitidos:
- Expressões is
- Expressões switch
- Padrões aninhados
- Padrão switch/case
C# 9 inclui novas melhorias de correspondência de padrões:
Atualmente, um padrão de tipo precisa declarar um identificador quando o tipo corresponder, mesmo se esse identificador for um discard _ , como em Person _ => "Senior". Mas agora você pode simplesmente escrever o tipo:
static string SwitchTipoSimples_C9(object simply) => simply switch
{
Person s when s.Age < 10 => "Criança",
Person s when s.Age <= 40 => "Adulto",
Person => "Senior",
_ => throw new ArgumentException("I do not know this one", nameof(simply))
};Permitimos um tipo como padrão, podemos também escrever:
void TypePattern(object tipo1, object tipo2)
{
var t = (tipo1, tipo2);
if (t is (int, string)) {
Console.WriteLine("É inteiro ou string!");
}
switch (tipo1)
{
case int:
Console.WriteLine("É inteiro!");
break;
case System.String:
Console.WriteLine("É string!");
break;
}
}Podemos simplificar esse switch usando os operadores relacionais, como <, <=, > e >=. Podemos
static string SwitchRelacional_C9(Person hero) => hero.Age switch
{
< 10 => "Criança",
<= 40 => "Adulto",
_ => "Senior"
};Podemos usar operadores lógicos conjuntivos (and), disjuntivos (or) ou de negação (not) como uma opção mais legível.
static string SwitchLogico_C9(Person hero) => hero.Age switch
{
1 or 2 => "Bebê",
< 10 and < 18 => "Criança",
<= 40 => "Adulto",
_ => "Senior"
};É conveniente se você usar o padrão de constante nula em conjunto com padrão not para dividir o tratamento de casos desconhecidos dependendo de serem nulos ou em não nulos
static string SwitchTipoSimples_C9(object simply) => simply switch
{
Person s when s.Age < 10 => "Criança",
Person s when s.Age <= 40 => "Adulto",
Person => "Senior",
not null => throw new ArgumentException($"I do not know this one: {simply}", nameof(simply)),
null => throw new ArgumentNullException(nameof(simply))
};O not é útil também em condições if contendo expressões is onde, oferecendo maior clareza sobre a lógica da negação.
if (!(person is Person)) { }
if (person is not Person) { }Como alternativa, com parênteses opcionais para deixá-lo claro que and tem precedência maior do que or:
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
public bool IsChild() => Age is >= 10 and <= 18;
public bool TakeNotes(char c) => c is >= 'a' and <= 'z' or >= 'A' and <= 'Z';
public bool TakeNotesOrSeparator(char c) => c is (>= 'a' and <= 'z') or (>= 'A' and <= 'Z') or '.' or ',';
}Três novos recursos melhoram o suporte para a interoperabilidade nativa e bibliotecas de nível baixo que exigem alto desempenho:
- Inteiros de tamanho nativo
- Ponteiros de função
- Suprimir emissão do sinalizador localsinit
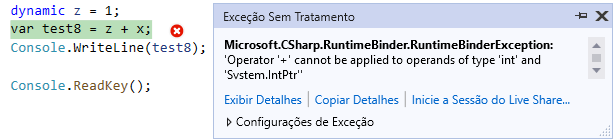
Os inteiros de tamanho nativo são projetados para ser um número inteiro cujo tamanho é específico para a plataforma. Em outras palavras, uma instância desse tipo deve ser de 32 bits em hardwares/sistemas operacionais de 32 bits, 64 bits em hardwares/sistemas operacionais de 64 bits. Inteiros de tamanho nativo nint e nuint, são tipos inteiros. Os tipos nint e nuint são representados pelos tipos subjacentes System.IntPtr e System.UIntPtr com o compilador mostrando conversões e operações adicionais para esses tipos como ints nativos.
- As constantes nint estão no intervalo [int.MinValue, int.MaxValue].
- As constantes nuint estão no intervalo [uint.MinValue, uint.MaxValue].
- Não há MinValue ou MaxValue o nint ou nuint porque esses valores não podem ser emitidos como constantes pois dependem do tamanho nativo de um inteiro no computador de destino. Exceto nuint.MinValue, que tem um MinValue de 0
O compilador executa o dobramento constante para todos os operadores unários e binários usando os tipos System.Int32 e System.UInt32, se o resultado não couber em 32 bits, a operação será executada em tempo de execução e não será considerada uma constante.
O CLR/JIT/MSIL suporta a definição e o uso de inteiros nativos/inteiros sem sinal. Desde o CLR do .NET 4.0, é possível adicionar/subtrair um inteiro de um System.IntPtr/System.UIntPtr, e é possível fazer comparações == e != com outro System.IntPtr/System.UIntPtr, mas qualquer outra operação de comparação não é possível, ou seja, eles não podem ser comparados com >, > = etc. Então System.IntPtr/System.UIntPtr permanece muito básico na quantidade de aritmética de ponteiro.
C# 9 traz o que mono trouxe antes: suporte de idioma para tipos inteiros assinados e não assinados de tamanho nativo com palavras-chave nint e nuint. A motivação aqui é para cenários de interoperabilidade e para bibliotecas de baixo nível, portanto, o uso não é muito frequente. Os inteiros de tamanho nativo podem aumentar o desempenho em cenários em que a matemática de inteiros é usada extensivamente e precisa ter o desempenho mais rápido possível.
nint x = 3;
int y = 3;
long v = 10;
Console.WriteLine(nint.Equals(x, y)); // False
Console.WriteLine(nint.Equals(x, (nint)y)); // True
Console.WriteLine(y + 1 > x); // True
Console.WriteLine(y - 1 == x); // False
Console.WriteLine(typeof(nint)); // System.IntPtr
Console.WriteLine(typeof(nuint)); // System.UIntPtr
Console.WriteLine((x + 1).GetType()); // System.IntPtr
Console.WriteLine((x + y).GetType()); // System.IntPtr
Console.WriteLine((x + v).GetType()); // System.Int64Quando você adiciona um int a um nint, o resultado é um nint, mas se você adicionar um long a um nint, o resultado será um longo. Isso ocorre porque o nativo dependendo da plataforma pode ser um inteiro de 32 bits ou um inteiro de 64 bits.
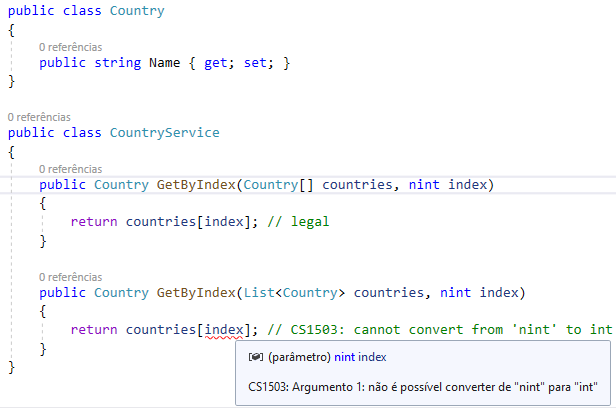
Você pode notar que os arrays suportam tipo assinado de tamanho nativo como índice, mas não listas, exemplo:
Os ponteiros de função do C# 9.0, fornecem uma maneira eficiente de declarar ponteiros para chamar funções nativas gerenciadas e não gerenciadas. Ponteiros de função é uma variável que armazena o endereço de uma função que pode ser chamada posteriormente por meio desse ponteiro de função. Os ponteiros de função podem ser invocados e passados argumentos exatamente como em uma chamada de função normal.
O runtime oferece suporte e complementar as partes relacionadas à interoperabilidade do recurso, fornecendo uma solução simétrica para chamar funções gerenciadas a partir do código nativo.
UnmanagedCallersOnlyAttribute indica que uma função será chamada apenas a partir do código nativo, permitindo que o runtime reduza o custo de chamar a função gerenciada. Para limitar a complexidade do cenário, o uso deste atributo é restrito a métodos que devem:
- Seja estático
- Só tem argumentos blittable
- Remove a dependência de qualquer lógica especial de empacotamento
- Não ser chamado de código gerenciado
- Limita os cenários que precisam ser tratados (por exemplo, nenhuma chamada por meio de reflexão), permitindo que o foco permaneça na redução do custo de chamar a função gerenciada a partir do código nativo
Um cenário de uso básico de passar um retorno de chamada gerenciado para uma função nativa teria, sem UnmanagedCallersOnlyAttribute, a seguinte aparência:
private static void Callback(int i)
{
throw new NotImplementedException();
}
private delegate void CallbackDelegate(int i);
private static CallbackDelegate s_callback = new CallbackDelegate(Callback);
static void Main(string[] args)
{
IntPtr callback = Marshal.GetFunctionPointerForDelegate(s_callback);
NativeFunctionWithCallback(callback);
}
[DllImport("NativeLib")]
private static extern void NativeFunctionWithCallback(IntPtr callback);O acima requer a alocação de um delegado e o marshalling desse delegado para um ponteiro de função. Se a função nativa que está sendo chamada puder reter o retorno de chamada, também precisamos garantir que o delegado não seja coletado como lixo. Esse detalhe costuma ser esquecido, levando a travamentos intermitentes de “retorno de chamada no delegado coletado”. Com a combinação de ponteiros de função e UnmanagedCallersOnlyAttribute, isso pode ser reescrito como:
Ponteiros de função fornecem uma sintaxe fácil para acessar os opcodes de IL ldftn e calli. Você pode declarar ponteiros de função usando a sintaxe de tipo de ponteiro new delegate*. Invocar o tipo delegate* usa calli, em contraste com um delegado que usa callvirt no método Invoke(). Sintaticamente, as invocações são idênticas. Invocação de ponteiro de função usa a Convenção managed de chamada. Você adiciona a palavra-chave unmanaged após a sintaxe delegate* para declarar que deseja a Convenção de chamada unmanaged. Outras convenções de chamada podem ser especificadas usando atributos na declaração delegate*.
Por fim, você pode adicionar o System.Runtime.CompilerServices.SkipLocalsInitAttribute para instruir o compilador C# Roslyn a não emitir o localsinit sinalizador. Esse sinalizador instrui o CLR a inicializar zero todas as variáveis locais. O localsinit sinalizador tem sido o comportamento padrão para C# desde 1,0. No entanto, a inicialização zero extra pode ter um impacto mensurável no desempenho em alguns cenários. Em particular, quando você usa o stackalloc. Nesses casos, você pode adicionar o SkipLocalsInitAttribute ao Core CLR. Você pode adicioná-lo a um único método ou propriedade, ou a um class, struct interface ou até mesmo a um módulo. Esse atributo não afeta abstract os métodos; ele afeta o código gerado para a implementação.
Esses recursos podem melhorar o desempenho em alguns cenários. Eles devem ser usados somente após um parâmetro de comparação cuidadoso antes e depois da adoção. O código que envolve inteiros de tamanho nativo deve ser testado em várias plataformas de destino com tamanhos de inteiro diferentes. Os outros recursos exigem código não seguro.
No aplicativo de alto desempenho, o custo da inicialização zero forçada pode ser perceptível. É particularmente perceptível quando o stackalloc é usado. Em alguns casos, o JIT pode Elide inicialização zero inicial de locais individuais quando tal inicialização é "eliminada" por atribuições subsequentes. Nem todos os JITs fazem isso e essa otimização tem limites. Ele não ajuda com o stackalloc .
Para ilustrar que o problema é real, há um bug conhecido em que um método que não contém nenhum IL local não teria um localsinit sinalizador. O bug já está sendo explorado pelos usuários, colocando stackalloc -se em tais métodos, intencionalmente, para evitar os custos de inicialização. Isso é apesar do fato de que a ausência de IL locais é uma métrica instável e pode variar dependendo das alterações na estratégia de codegen. O bug deve ser corrigido e os usuários devem ter uma maneira mais documentada e confiável de suprimir o sinalizador.
Desvantagens
- Os compiladores antigos/outros podem não honrar o atributo. Ignorar o atributo é um comportamento compatível. Pode resultar apenas em uma ligeira queda de desempenho.
- O código sem localinits sinalizador pode disparar falhas de verificação. Os usuários que solicitam esse recurso geralmente não são preocupados com a capacidade de verificação.
- A aplicação do atributo em níveis mais altos do que um método individual tem efeito não local, que é observável quando stackalloc é usado. Ainda assim, esse é o cenário mais solicitado.
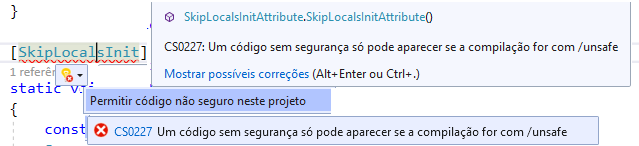
Esse novo recurso só pode ser usado com a opção unsafe do compilador:
O CLR suporta um atributo .localsinit para métodos que, quando definido, garante que todas as variáveis sejam zeradas antes de executar o método. Veja o seguinte erro:
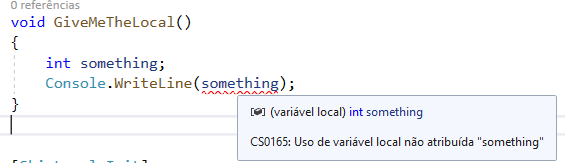
Isso não é válido em C# porque ele verifica a atribuição definitiva. A análise de atribuição definitiva é um processo que verifica se todas as variáveis foram atribuídas antes de serem utilizadas. Isso me ajuda a evitar erros como desenvolvedor, pois eu nunca deveria realmente querer usar variáveis antes de atribuí-las, mesmo que seja uma pequena questão de escrever int something = default para deixar as coisas claras.
A equipe C# tem nos últimos anos priorizado o desempenho da linguagem para promover o C# como um sério competidor para aplicativos de alto desempenho. (por exemplo, em structs e readonly). Por exemplo, os desenvolvedores de jogos precisam chegar à velocidade do metal para fornecer uma experiência de usuário tranquila e, portanto, procurar qualquer oportunidade para remover ineficiências. Portanto, não é surpreendente que alguns vejam o sinalizador localsinit como um obstáculo desnecessário ao desempenho, especialmente quando se considera que o C# tem Atribuição definida embutida e, portanto, mesmo se os locais não fossem zerados, eles ainda seriam sobrescritos na maioria das vezes.
Assim nasceu SkipLocalsInitAttribute para instruir Roslyn a evitar a emissão .localsinit de métodos críticos de desempenho. O maior ganho aqui é para métodos com um quadro de pilha grande, portanto, especialmente para métodos stackalloc que usam o qual aloca um array na pilha. O CLR zera esse array se .localsinit estiver definido, e se o array for grande e o programa estiver prestes a atribuir todos os slots do array de qualquer maneira, é um desperdício total. Vamos iniciar a pré-visualização do VS2019 com um projeto unsafe e e criar um método que mantém uma contagem de invocação na pilha usando stackalloc:
static void Main(string[] args)
{
for (int i = 0; i < 10; i++)
{
PrintRunningCount();
}
}
[SkipLocalsInit]
static void PrintRunningCount()
{
const int Magic = 123214;
Span<int> arr = stackalloc int[2];
if (arr[0] != Magic)
{
arr[0] = Magic;
arr[1] = 0;
}
Console.WriteLine($"Hello World stackalloc {arr[1]++}!");
}Podemos ver que cada vez que PrintRunningCount é invocado, ele cria um array que contém 2 valores. O primeiro arr[0] é um valor mágico para controlar se o método está sendo executado pela primeira vez. Como localsinit não está mais lá para ajudar, não podemos presumir que nosso contador comece em 0. O segundo valor contém a contagem real.
Este exemplo é bastante seguro se você me perguntar; o desenvolvedor optou por usar [SkipLocalsInit] e, portanto, pode contar com uma atribuição definida, exceto para stackalloc. No entanto, agora nos movemos para o território mais inseguro ... para quando a Análise de Atribuição Definida falhar! As regras são bem claras quando se trata de variáveis atribuídas como um todo ( variable = ...). No entanto, as estruturas são especiais e podem ser atribuídas por partes, como no exemplo a seguir.
static void Main(string[] args)
{
for (int i = 0; i < 10; i++)
{
PrintRunningCountStruct();
}
}
struct StackCounter
{
public long A;
public static long Increment(ref StackCounter c) { return c.A++; }
}
[SkipLocalsInit]
static void PrintRunningCountStruct()
{
StackCounter counter;
counter.A = default;
// counter is definitely assigned since we've set all of it's fields
var count = StackCounter.Increment(ref counter);
Console.WriteLine($"Hello World {count}!");
}Compile o acima e conforme o esperado, você observará impresso algumas vezes no console Hello World 0!. No entanto, esta regra para atribuição definitiva tem um problema. E se alguém mover StackCounter para outra biblioteca e compilar o programa de console como está? A Atribuição Definida é verificada no momento da compilação e, portanto, o programa de console é compilado com sucesso.
E se alguém "atualizar" a biblioteca, recompilá-la e sobrescrever o arquivo dll antigo? Esse tipo de coisa acontece com frequência - por exemplo, um projeto pode fazer referência a uma versão mais antiga de uma biblioteca na mesma solução de um projeto que faz referência a uma nova versão e, quando tudo é construído, o mais novo é usado para ambos. No meu caso, eu "atualizei" StackCounter da seguinte maneira.
public struct StackCounter
{
public long A;
public long Count;
public long Magic;
public static long Increment(ref StackCounter c)
{
const long Magic = 23872139472367;
if (c.Magic != Magic)
{
c.Magic = Magic;
c.Count = 0;
}
return c.Count++;
}
}
[SkipLocalsInit]
static void PrintRunningCountStruct()
{
long count;
StackCounter counter;
//StackCounter counter = default(StackCounter);
//StackCounter counter = new StackCounter();
counter.A = default;
counter.Count = default;
counter.Magic = default;
// counter is definitely assigned since we've set all of it's fields
count = StackCounter.Increment(ref counter);
Console.WriteLine($"Hello World {count}!");
}Se executarmos o mesmo programa agora, veremos que a contagem aumenta de Hello World 0! a Hello World 9!. Para quem está olhando para a fonte, este exemplo é muito menos claramente quebrado do que o stackallocexemplo. É o desenvolvedor da biblioteca que agora armazena o estado na pilha de outro método.
C# 9 inclui suporte aprimorado para target-typing. Target-typing o que C# usa, normalmente em expressões, para obter um tipo de seu contexto. Um exemplo comum seria o uso da palavra-chave var. O tipo pode ser inferido de seu contexto, sem que você precise declará-lo explicitamente.
O aprimoramento do target-typing no C# 9 vem em:
- Expressão new
- Expressão condicional de Target-typing ?? e ?. (Ainda não funciona)
Muitos dos outros recursos ajudam a escrever código com mais eficiência. No C# 9,0, você pode omitir o tipo em uma expressão new quando o tipo do objeto criado já é conhecido. O uso mais comum está em declarações de campo:
Person person = new("Bob", "Dyla");
List<Person> _observations = new();
var personList = new List<Person>
{
new ("Bob", "Marei"),
new ("Bob", "Quened"),
new ("Uncle", "Bob"),
new ("Rick", "Bob")
};O tipo de destino New também pode ser usado quando você precisa criar um novo objeto para passar como um parâmetro para um método. Considere um método Encontro() com a seguinte assinatura:
public class Person
{
//....
public void Encontro(DateTime dia, Opcoes options) => Console.WriteLine("It's class teaching time: " + dia.ToString() + "-" + options.texto);
}
public class Opcoes
{
private int _num;
private string _txt;
public Opcoes(){ }
public Opcoes(int numero, string texto)
{
_num = numero;
_txt = texto;
}
public int numero { get { return _num; } set { _num = value; } }
public string texto { get { return _txt; } set { _txt = value; } }
}Você pode chamá-lo da seguinte maneira:
person.Encontro(DateTime.Now.AddDays(2), new(1, "oi"));Outro bom uso para esse recurso é combiná-lo com propriedades init somente para inicializar um novo objeto:
Opcoes opcoes = new() { numero = 42, texto = "Seattle, WA" };Você pode retornar uma instância criada pelo construtor padrão usando uma expressão return new();.
Um recurso semelhante melhora a resolução de tipo de destino de expressões condicionais. Com essa alteração, as duas expressões não precisam ter uma conversão implícita de uma para a outra, mas podem ter conversões implícitas em um tipo comum. Você provavelmente não perceberá essa alteração. O que você observará é que algumas expressões condicionais que antes exigiam conversões ou que não compilaram agora só funcionam.
Por falar em declarações ternárias, agora podemos inferir tipos usando os operadores condicionais. Isso funciona bem com ??, o operador de coalescência nula. O ?? operador retorna o valor do que está à esquerda se não for nulo. Caso contrário, o lado direito é avaliado e retornado. Então, imagine que temos alguns objetos que compartilham a mesma classe base, como este:

Com a covariância do tipo de retorno, você pode substituir um método de classe base (que possui um tipo menos específico) por um que retorna um tipo mais específico. Você não precisará mais implementar soluções alternativas de interface. Antes do C# 9, você teria que retornar o mesmo tipo em uma situação como esta:
public class Person
{
private string _firstName;
private string _lastName;
public Person(string firstName, string lastName)
{
_firstName = firstName;
_lastName = lastName;
}
public virtual Person GetPerson()
{
return new Person(_firstName, _lastName);
}
}
public class Student : Person
{
private string _favoriteSubject;
private string _firstName;
private string _lastName;
public Student(string firstName, string lastName, string favoriteSubject) : base(firstName, lastName)
{
_favoriteSubject = favoriteSubject;
_firstName = firstName;
_lastName = lastName;
}
public override Person GetPerson()
{
// you can return the child class, but still return a Person
return new Student(_firstName, _lastName, "None");
}
}Agora, você pode retornar o tipo mais específico em C# 9.
public override Student GetPerson()
{
// you can return the child class, but still return a Person
return new Student(_firstName, _lastName, "None");
}

Isso pode ser útil para registros e para outros tipos que dão suporte a métodos de clonagem ou de alocador virtual.
A partir do C# 9,0, você pode adicionar o static modificador a expressões lambda ou a métodos anônimos. As expressões lambda estáticas são análogas às static funções locais: uma função lambda ou anônima estática não pode capturar variáveis locais ou estado de instância. O static modificador impede capturar inadvertidamente o estado do contexto envolvente, o que pode resultar na retenção inesperada de objetos capturados (captura acidental de outras variáveis) ou em alocações adicionais inesperadas.
static void Main(string[] args)
{
int y = 10;
someMethod(x => x + y); // captures 'y', causing unintended allocation.
}
private static void someMethod(Func<int, int> soma_func)
{
Console.WriteLine(soma_func(2));//12
Console.WriteLine(soma_func(12));//22
}Em C#, as funções anônimas que se referem a variáveis locais requerem a alocação de um objeto temporário. O parâmetro local é então movido para fora do método e para dentro do objeto, de forma que continuará a existir após o término da função atualmente em execução. Isso é necessário porque uma função anônima pode existir por mais tempo do que a função que a criou.
Adicionar a palavra-chave static indica que a função anônima impede essa alocação de memória.
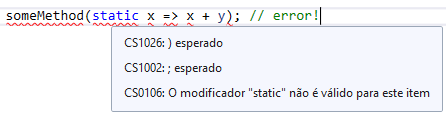
Para corrigir o erro, a variável y precisa ser transformada em um campo constante ou estático.
const int y = 10;
algumMétodo (estático x => x + y); // OK :-)Abaixo estão as principais regras para este recurso:
- O modificador estático em um lambda ou método anônimo indica é uma função anônima estática.
- Uma função anônima estática pode fazer referência a membros estáticos do escopo delimitador.
- Uma função anônima estática não pode capturar o estado do escopo delimitador. Como resultado, locais, parâmetros e isso do escopo delimitador não estão disponíveis em uma função anônima estática.
- Uma função anônima estática não pode fazer referência a membros de instância de uma referência implícita ou explícita this ou base.
- Uma função anônima estática pode fazer referência a membros estáticos do escopo delimitador.
- Uma função anônima estática pode fazer referência a definições constantes do escopo delimitador.
- nameof () em uma função anônima estática pode referenciar locais, parâmetros, ou this ou base do escopo envolvente.
- As regras de acessibilidade para membros privados no escopo delimitador são as mesmas para funções anônimas estáticas e não estáticas.
- Nenhuma garantia é feita se uma definição de função anônima estática é emitida como um método estático em metadados. Isso é deixado para a implementação do compilador para otimizar.
- Uma função local não estática ou função anônima pode capturar o estado de uma função anônima estática envolvente, mas não pode capturar o estado fora da função anônima estática envolvente.
- Remover o modificador estático de uma função anônima em um programa válido não altera o significado do programa.
Permitir usar os descartes como parâmetros para:
- Expressões Lambdas: (_, _) => 0, (int _, int _) => 0
- Métodos anônimos: delegate (int _, int _) { return 0; }
Essa conveniência permite que você evite nomear o argumento, e o compilador pode evitar usá-lo. Você usa o _ para qualquer argumento. Permite que o lambda tenha várias declarações dos parâmetros denominados _. Nesse caso, os parâmetros são "descartados" e não podem ser usados dentro do lambda.
A função local estática é um novo recurso introduzido no C# 8.0. Antes do C# 8.0, não podíamos ter uma função local como uma função estática. Em C# 7.x, o código abaixo não é compilado.
int num1 = 5, num2 = 7;
static int Sum(int x, int y)
{
return x + y;
};
var result = Sum(num1, num2);
Console.WriteLine(result); //12Enquanto no C# 8.0, o código acima é compilado com sucesso. Mas como sabemos que existem algumas condições com função estática, essas condições também se aplicam à função estática local. O último exemplo de código que tomamos também pode ser reescrito conforme mostrado abaixo:
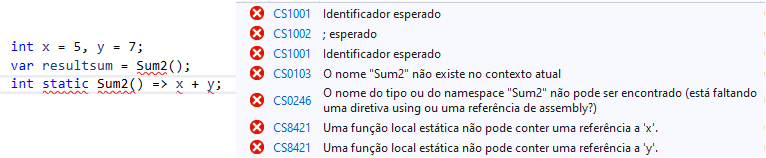
int num1 = 5, num2 = 7;
int Sum2() => num1 + num2;
var resultsum = Sum2();
Console.WriteLine(resultsum); //12Portanto, no trecho de código acima, podemos ver que estamos usando a variável do método pai em uma função local e essas variáveis são variáveis não estáticas. Mas se tentarmos colocar uma palavra-chave estática com a função local, que está acessando variáveis do método pai, então não funcionará. A seguir está a captura de tela para este princípio.
Por fim, agora você pode aplicar atributos a funções locais. Por exemplo, você pode aplicar anotações de atributo anulável ou condicional a funções locais.
int num1 = 5, num2 = 7;
int Sum2() => num1 + num2;
var resultsum = Sum2();
Console.WriteLine(resultsum); //12
Sum_C9(num1, num2);
[Conditional("DEBUG")]
static void Sum_C9([NotNull] int x, [NotNull] int y)
{
Console.WriteLine(x + y); //12
}Se retirar o modificador static emitirá erro no atributo Condicional, mas não terá problemas no atributo NotNull

Outro exemplo de uso com EnumeratorCancellation no parâmetro CancelamentoToken de uma função local que implementa um iterador assíncrono, que é comum ao implementar operadores de consulta.
public static IAsyncEnumerable<int> Where(this IAsyncEnumerable<int> source, Func<int, int> predicate)
{
if (source == null)
throw new ArgumentNullException(nameof(source));
if (predicate == null)
throw new ArgumentNullException(nameof(predicate));
return Core();
async IAsyncEnumerable<int> Core([EnumeratorCancellation] CancellationToken token = default)
{
await foreach (var item in source.WithCancellation(token))
{
if (predicate(item) == 1)
{
yield return item;
}
}
}
}Alguns tipos de coleção oferecem o método GetEnumerator. Este método retorna um objeto Enumerator que pode ser usado para percorrer a coleção. Não é necessário conhecimento completo do tipo de coleção real.
O exemplo abaixo mostra como funciona o método GetEnumerator no tipo List. Apartir de uma Lista(int) de inteiros o GetEnumerator retorna um objeto Enumerador List (int). Este objeto implementa IEnumerator (int).
static void Main(string[] args)
{
List<int> list = new List<int>();
list.Add(1);
list.Add(5);
list.Add(9);
List<int>.Enumerator e = list.GetEnumerator();
Write(e);
Console.ReadKey();
}
static void Write(IEnumerator<int> e)
{
while (e.MoveNext())
{
int value = e.Current;
Console.WriteLine(value);
}
}Podemos então escrever um método Write que recebe IEnumerator(int) e percorre seus elementos com uma construção while e a instrução MoveNext. O IEnumerator é uma interface implementada por objetos Enumerator e é diferente de IEnumerable. IEnumerable é geralmente é usado em uma coleção que pode ser repetida com foreach-loops. Outros tipos de coleção também fornecem GetEnumerator. Por exemplo,
- LinkedList
- Dictionary
O loop foreach é usado para iterar sobre uma coleção e automaticamente armazena o item atual em uma variável de loop. O loop foreach monitora onde está a coleção e protege você contra a iteração após o final da coleção. O C# fornece a instrução foreach para iterar com coleções de itens em que a quantidade não é conhecida no tempo de execução, como alocações dinâmicas com base na entrada do usuário. Por exemplo, você pode criar uma matriz de caracteres a partir dos caracteres individuais de uma sequência de texto inserida por um usuário em tempo de execução. Outras possibilidades podem ser um conjunto de dados criado após o acesso a um banco de dados. Nos dois casos, você não saberá o número de valores no momento em que escreve o código. O código abaixo mostra um exemplo de como usar o loop foreach.
int[] values = { 1, 2, 3, 4, 5, 6 };
foreach (int i in values)
{
Console.Write(i);
}Como você pode ver, o loop foreach armazena automaticamente o item atual em uma variável fortemente tipada. Você pode usar as instruções continue e interromper para influenciar o funcionamento do loop foreach. Coleções são tipicamente matrizes, mas também outros objetos .NET que implementaram as interfaces IEnumerable. A variável de loop não pode ser modificada. Você pode fazer modificações no objeto para o qual a variável aponta, mas não pode atribuir um novo valor a ele. O código a seguir mostra essas diferenças.
class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
}
static void CannotChangeForeachIterationVariable()
{
var people = new List<Person>
{
new Person() { FirstName ="John", LastName ="Doe"},
new Person() { FirstName ="Jane", LastName = "Doe"},
};
foreach (Person p in people)
{
p.LastName = "Changed"; // This is allowed
//p = new Person(); // This gives a compile error
}
}Você pode entender esse comportamento quando souber como o foreach realmente funciona. Quando o compilador encontra uma instrução foreach, ele gera algum código em seu nome; foreach é um açúcar sintático que permite escrever um código de maneira agradável. O exemplo abaixo mostra o que está acontecendo.
var people = new List<Person>{
new Person() { FirstName ="John", LastName ="Doe"},
new Person() { FirstName ="Jane", LastName = "Doe"}};
List<Person>.Enumerator e = people.GetEnumerator();
try
{
Person v;
while (e.MoveNext())
{
v = e.Current;
}
}
finally
{
System.IDisposable d = e as System.IDisposable;
if (d != null) d.Dispose();
}Se você alterar o valor de e.Current para outra coisa, o padrão do iterador não pode determinar o que fazer quando o e.MoveNext é chamado. É por isso que não é permitido alterar o valor da variável de iteração em uma instrução foreach.
É importante saber que o método foreach da linguagem C# trabalha com todos os tipos que implementam a interface IEnumerable, ou seja, ArrayList e Queue.O loop foreach chama o método GetEnumerator da "lista", que gera um valor de retorno do índice de cada matriz em cada iteração. Portanto, myArrayList agora se tornou uma coleção personalizada devido ao IEnumerable. Na imagem a seguir, você pode ver um valor yield de retorno do índice de cada matriz em cada iteração.
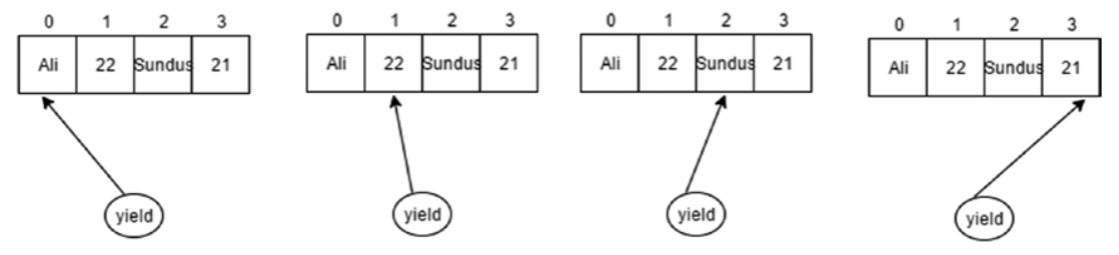
A partir do C# 9,0, o loop foreach reconhecerá e usará um método de extensão GetEnumerator que, de outra forma, atende ao foreach padrão. Essa alteração significa que o foreach pode ser consistente com outras construções baseadas em padrões, como o padrão assíncrono e a desconstrução baseada em padrões. Na prática, essa alteração significa que você pode adicionar suporte foreach a qualquer tipo.
Dois recursos finais dão suporte a geradores de código C#. Os geradores de código C# são um componente que você pode escrever que é semelhante a um analisador de Roslyn ou a uma correção de código. A diferença é que os geradores de código analisam o código e gravam novos arquivos de código-fonte como parte do processo de compilação. Um gerador de código típico pesquisa código em busca de atributos ou outras convenções.
Um gerador de código lê atributos ou outros elementos de código usando as APIs de análise de Roslyn. A partir dessas informações, ele adiciona um novo código à compilação. Os geradores de origem só podem adicionar código; Eles não têm permissão para modificar nenhum código existente na compilação.
Os dois recursos adicionados para geradores de código são:
- Extensões para sintaxe de método parcial
- Inicializadores de módulo.
Antes do C# 9,0, haviam algumas restrições em relação aos métodos parciais:
- Devem ter um tipo de retorno void
- Não podem ter parâmetros de saída out
- Por padrão são private, e não podem especificar um modificador de acesso (pública, privada, protegida, etc)
Abaixo estão alguns exemplos do que acontece quando um método parcial tem ou não uma palavra-chave de acessibilidade, tem ou não um parâmetro out, um tipo void ou not return, implementa uma interface:
partial class MyService : IMyService
{
partial void MyFirstFunction(); // Ok
// CS0750 A partial method cannot have access modifiers or the virtual, abstract, override, new, sealed, or extern modifiers
private partial void MySecondFunction();
// CS0750 A partial method cannot have .....
private partial void MyThirdFunction();
// CS0750 E CS0766 Partial methods must have a void return type
private partial object MyFourthFunction();
// CS0750 E CS0766 Partial methods must have a void return type
private partial object MyFifthFunction();
// CS0750 E CS0752 A partial method cannot have out parameters
private partial void MySixthFunction(out int result);
// CS0750 A partial method cannot have .....
public partial void MySeventhFunction();
}
partial class MyService
{
// CS0750 A partial method cannot have .....
private partial void MyThirdFunction() { }
// CS0750 E CS0766 Partial methods must have a void return type
private partial object MyFifthFunction() { return new { }; }
// CS0750 E CS0752 A partial method cannot have out parameters
private partial void MySixthFunction(out int result) { result = 42; return; }
// CS0750 A partial method cannot have .....
public partial void MySeventhFunction() { }
}
public interface IMyService
{
void MySeventhFunction();
}Como, até o C# 8, não oferecia suporte a palavra-chave de acessibilidade em métodos parciais, na implementação da interface é impossível implementar o método parcial a partir de sua assinatura de interface, porque sem nenhuma palavra-chave, o método é implicitamente um método privado.
Essas restrições destinam-se que, se nenhuma implementação de método for fornecida, o compilador removerá todas as chamadas para o método parcial. O C# 9,0 remove essas restrições, mas requer que as declarações de método parciais tenham uma implementação. Os geradores de código podem fornecer essa implementação. Para evitar a introdução de uma alteração significativa, o compilador considera qualquer método parcial sem um modificador de acesso para seguir as regras antigas. Se o método parcial incluir o private modificador de acesso, as novas regras regem esse método parcial.
partial class MyService : IMyService
{
partial void MyFirstFunction(); // Ok
// CS8795 Partial method must have an implementation part because it has accessibility modifiers
private partial void MySecondFunction();
private partial void MyThirdFunction(); // Ok
// CS8795 Partial method must have an implementation part ....
private partial object MyFourthFunction();
private partial object MyFifthFunction(); // Ok
private partial void MySixthFunction(out int result);
public partial void MySeventhFunction(); // Ok
}
partial class MyService
{
private partial void MyThirdFunction() { } // Ok
private partial object MyFifthFunction() { return new { }; } // Ok
private partial void MySixthFunction(out int result) { result = 42; return; } // Ok
public partial void MySeventhFunction() { } // Ok
}
public interface IMyService
{
void MySeventhFunction();
}C# 9 permite agora o que faltava em C# 8, mas agora requer uma implementação de métodos que são definidos com:
- void or not return type
- parâmetros de saída
- palavra-chave de acessibilidade (pública, privada, protegida, etc ...)
Como você pode ver acima, C# 9 traz um novo código de erro com sua mensagem caso as condições anteriores não sejam atendidas:
CS8795: Partial method must have an implementation part because it has accessibility modifiersUm "inicializador de módulo" é uma função executada quando um assembly é carregado pela primeira vez. Eles são métodos estáticos globais chamados .cctor cuja execução é garantida antes que qualquer outro código (inicializadores de tipo, construtores estáticos) em um assembly seja executado. Em muitos aspectos, é como um construtor estático em C#, mas em vez de se aplicar a uma classe, ele se aplica a todo o assembly. Esse recurso existe no CLR desde o início, mas até agora não estava disponível diretamente em C# ou VB.NET. Para utilizar este recurso era necessário utilizar ferramentas de terceiros para “injetar” os inicializadores de módulo.
O C# 9 adicionou um segundo novo recurso para geradores de código que é inicializadores de módulo para:
- Permitir que as bibliotecas façam uma inicialização rápida, única quando carregadas, com sobrecarga mínima e sem o usuário precisar chamar explicitamente qualquer coisa
- Um ponto problemático específico das abordagens do Construtor static atual é que o tempo de execução deve fazer verificações adicionais no uso de um tipo com um construtor estático, a fim de decidir se o construtor estático precisa ser executado ou não. Isso adiciona sobrecarga mensurável.
- Habilitar os geradores de origem para executar alguma lógica de inicialização global sem que o usuário precise chamar explicitamente nada. Um inicializador de módulo é previsível; todo o código nele é executado sequencialmente. Com construtores estáticos, a ordem em que eles são executados não é determinística do ponto de vista da montagem. Dependendo do código do cliente, o construtor da Classe A pode ser executado antes ou depois da Classe B.
Inicializadores de módulo são métodos que têm o ModuleInitializerAttribute atributo anexado a eles.
class C
{
[ModuleInitializer]
internal static void M1()
{
// ...
}
}Como você pode ver neste exemplo, um atributo de nível de módulo é marcado com um nome de classe. O construtor estático dessa classe é então promovido ao nível do inicializador de módulo. Esse recurso pode resultar em ganhos de desempenho em relação aos construtores estáticos normais. Esses métodos serão chamados em tempo de execução quando o assembly for carregado. Atualmente, o tempo de execução leva um bloqueio de inicialização que é usado para verificar se a lógica de construção estática foi processada. Adicionando até mesmo um campo estático somente leitura a uma classe.
Alguns requisitos são impostos sobre o método de destino com este atributo:
- O método deve ser static .
- O método deve ser sem parâmetros.
- O método deve retornar void.
- O método não deve ser genérico ou estar contido em um tipo genérico.
- O método deve ser acessível do módulo que o contém.
- Isso significa que a acessibilidade efetiva do método deve ser internal ou public .
- Isso também significa que o método não pode ser uma função local.
Quando um ou mais métodos válidos com esse atributo forem encontrados em uma compilação, o compilador emitirá um inicializador de módulo que chama cada um dos métodos atribuídos. As chamadas serão emitidas em uma ordem reservada, mas determinística.