Csharp8 - shyoutarou/Exam-70-483_Csharp8_Csharp9 GitHub Wiki
- HABILITANDO O C# 8
- Padrões do compilador
- Substituir um padrão
- Editar o arquivo de projeto
- Configurar vários projetos
A primeira etapa é garantir que estejamos usando o Visual Studio 2019 versão 16.3 ou superior. Verifique no menu Ajuda > Informações sobre o Visual Studio.
Em seguida, precisamos configurar o projeto para o C# 8. Se estivermos acostumados a trabalhar com o Visual Studio, talvez espere alterar de maneira simples a configuração de um projeto. Antes era só ir para Compilar da janela de propriedades do projeto e selecionar a versão do idioma C# :
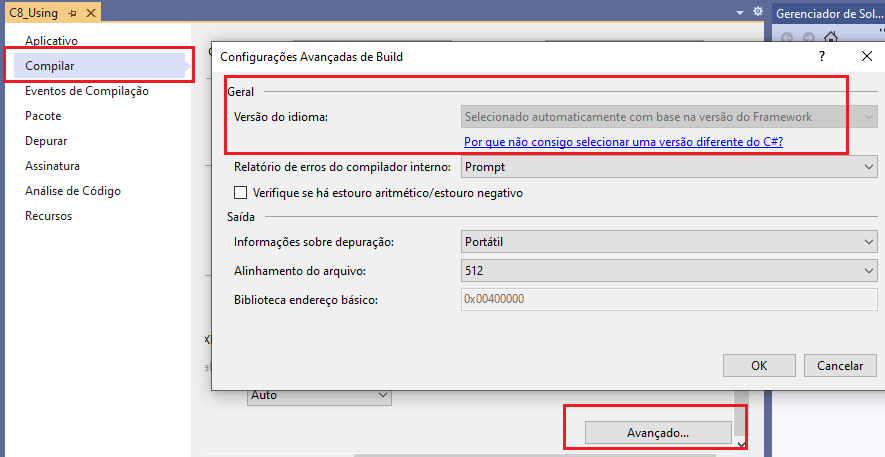
Infelizmente, isso não funciona mais. Sob as novas regras, a versão padrão do C# é determinada por qual framework estamos direcionando. Os compiladores do C# que fazem parte da instalação do Visual Studio 2017 ou de versões anteriores do SDK do .NET Core são direcionados ao C# 7.0 por padrão. O C# 8,0 tem suporte apenas no .NET Core 3. x e em versões mais recentes. Muitos dos recursos mais recentes exigem recursos de biblioteca e tempo de execução introduzidos no .NET Core 3. x:
- A implementação de interface padrão requer novos recursos no .net Core 3,0 CLR.
- Os fluxos assíncronos exigem os novos tipos:
- System.IAsyncDisposable,
- System.Collections.Generic.IAsyncEnumerable
- System.Collections.Generic.IAsyncEnumerator .
- Índices e intervalos exigem os novos tipos System.Index e System.Range .
- Os tipos de referência anuláveis fazem uso de vários atributos para fornecer avisos melhores. Esses atributos foram adicionados no .NET Core 3,0. Outras estruturas de destino não foram anotadas com nenhum desses atributos. Isso significa que os avisos anuláveis podem não refletir com precisão possíveis problemas.
O C# 9,0 tem suporte apenas no .NET 5 e em versões mais recentes.
O compilador determina um padrão com base nestas regras:
| Estrutura de destino | version | Padrão da versão da linguagem C# |
|---|---|---|
| .NET | 5 | C# 9,0 |
| .NET Core | 3.x | C# 8.0 |
| .NET Core | 2. x | C# 7.3 |
| .NET Standard | 2.1 | C# 8.0 |
| .NET Standard | 2.0 | C# 7.3 |
| .NET Standard | 1.x | C# 7.3 |
| .NET Framework | all | C# 7.3 |
Abra o prompt de comando do desenvolvedor para o Visual Studioe execute o comando a seguir para ver a lista de versões de idioma disponíveis em seu computador.
csc -langversion:?Questionando a opção de compilação -langversion como essa, imprimirá algo semelhante ao seguinte:
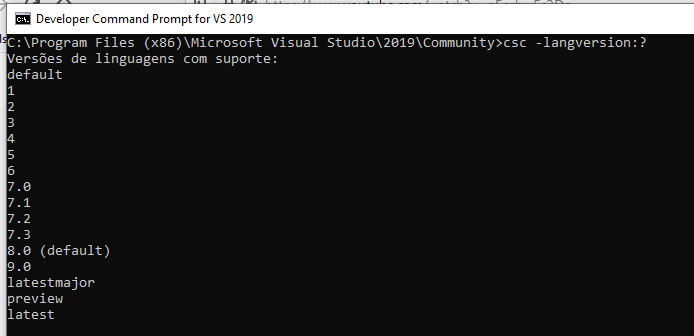
A tabela a seguir mostra todas as versões atuais da linguagem C#. Seu compilador pode não entender necessariamente todos os valores se for mais antigo. Se você instalar o .NET Core 3,0 ou posterior, terá acesso a todos os itens listados.
| Valor | Significado |
|---|---|
| preview | O compilador aceita todas as sintaxes de linguagem válidas da versão prévia mais recente. |
| latest | O compilador aceita a sintaxe da versão lançada mais recente do compilador (incluindo a versão secundária). |
| latestMajor (default) | O compilador aceita a sintaxe da versão principal mais recente lançada do compilador. |
| 8.0 | O compilador aceita somente a sintaxe incluída no C# 8.0 ou inferior. |
| 7.3 | O compilador aceita somente a sintaxe incluída no C# 7.3 ou inferior. |
| 7.2 | O compilador aceita somente a sintaxe incluída no C# 7.2 ou inferior. |
| 7.1 | O compilador aceita somente a sintaxe incluída no C# 7.1 ou inferior. |
| 7 | O compilador aceita somente a sintaxe incluída no C# 7.0 ou inferior. |
| 6 | O compilador aceita somente a sintaxe incluída no C# 6.0 ou inferior. |
| 5 | O compilador aceita somente a sintaxe incluída no C# 5.0 ou inferior. |
| 4 | O compilador aceita somente a sintaxe incluída no C# 4.0 ou inferior. |
| 3 | O compilador aceita somente a sintaxe incluída no C# 3.0 ou inferior. |
| ISO-2(ou 2) | O compilador aceita apenas a sintaxe que está incluída em ISO/IEC 23270:2006 C# (2,0). |
Para saber qual versão de idioma você está usando no momento, coloque #error em seu código. Isso faz com que o compilador produza um diagnóstico, CS8304, com uma mensagem que contém a versão do compilador que está sendo usada e a versão atual do idioma selecionado.
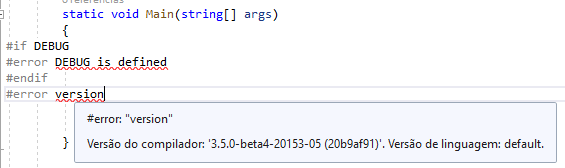
Somente o .NET Core 3.0 e o .NET Standard 2.1 possuem o C# 8, o restante começa com o C# 7.3. Crie um projeto console Core 3.0:
Se precisar especificar sua versão do C# explicitamente, poderá fazer isso de várias maneiras:
- Edite manualmente o arquivo de projeto (csproj).
- Definir a versão da linguagem para vários projetos em um subdiretório.
- Configure a -langversion opção do compilador.
É possível definir a versão da linguagem em seu arquivo de projeto. Por exemplo, se você quiser explicitamente acesso às versões prévias dos recursos, adicione um elemento como este:
<PropertyGroup>
<LangVersion>preview</LangVersion> OU <LangVersion>8.0</LangVersion>
</PropertyGroup>O valor preview usa a versão prévia mais recente da linguagem C# compatível com seu compilador. Se estivermos usando um formato de projeto moderno, podemos abri-lo clicando duas vezes no projeto no Solution Explorer. Podemos reconhecer esse formato porque a raiz do arquivo XML é parecida com esta:
<Project Sdk="Microsoft.NET.Sdk">Se estivermos usando o formato do projeto legado, podemos editá-lo diretamente, mas será um pouco mais complicado. Uma opção é fechar o Visual Studio e usar o bloco de notas ou algum editor de texto. Como alternativa, podemos instalar o Power Commands do Visual Studio, que adiciona um comando "Edit Project File". Para referência, a raiz do arquivo XML será mais ou menos assim:
<Project ToolsVersion="14.0" DefaultTargets="Build" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">Para configurar vários projetos, você pode criar um arquivo Directory. Build. props que contém o <LangVersion> elemento. Normalmente, você faz isso no diretório da solução. Adicione o seguinte a um arquivo Directory. Build. props no diretório da solução:
<Project>
<PropertyGroup>
<LangVersion>preview</LangVersion>
</PropertyGroup>
</Project>As compilações em todos os subdiretórios do diretório que contém esse arquivo usarão a versão preview C#. Para obter mais informações, confira o artigo sobre como personalizar o build. C# 8.0 adiciona os seguintes recursos e aprimoramentos à linguagem C#:
Você pode aplicar o modificador readonly a membros de uma estrutura. Indica que o membro não modifica o estado. É mais granular do que aplicar o modificador readonly a uma declaração struct. Como a maioria dos structs, o método ToString() não modifica o estado. Você pode indicar isso adicionando o modificador readonly à declaração de ToString():
public struct Point
{
public double X { get; set; }
public double Y { get; set; }
public readonly double Distance => Math.Sqrt(X * X + Y * Y);
public readonly override string ToString() =>
$"({X}, {Y}) is {Distance} from the origin";
}A alteração anterior gera um aviso do compilador, porque ToString acessa a propriedade Distance, que não está marcada readonly:
warning CS8656: Call to non-readonly member 'Point.Distance.get' from a 'readonly' member results in an implicit copy of 'this'O compilador avisa quando é necessário criar uma cópia defensiva. A propriedade Distance não muda de estado, então você pode corrigir esse aviso adicionando o modificador readonly à declaração:
public readonly double Distance => Math.Sqrt(X * X + Y * Y)Observe que o modificador readonly é necessário em uma propriedade somente leitura. O compilador não assume que os acessadores get não modificam o estado; você deve declarar readonly explicitamente. As propriedades implementadas automaticamente são uma exceção; o compilador tratará todos os getters implementados automaticamente como readonly, portanto, aqui não há necessidade de adicionar o readonly às propriedades X e Y. O compilador impõe a regra de que os membros readonly não modificam o estado. O método a seguir não será compilado a menos que você remova o modificador readonly:
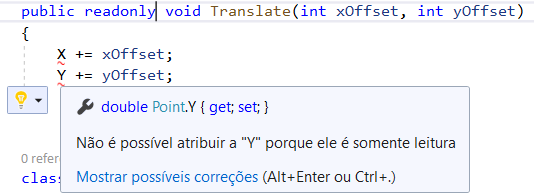
Ao retirar modificador readonly do método, podemos executar a Struct:
static void Main(string[] args)
{
var ponto = new Point();
ponto.X = 10;
ponto.Y = 20;
Console.WriteLine(ponto.ToString());
//(10, 20) is 22,360679774997898 from the origin
ponto.Translate(2, 8);
Console.WriteLine(ponto.ToString());
//(12, 28) is 30,463092423455635 from the origin
}Este recurso permite que você especifique a intenção do projeto para que o compilador possa aplicá-la e fazer otimizações com base nessa intenção.
Agora você pode adicionar membros às interfaces e fornecer uma implementação para esses membros. Este recurso de linguagem permite que os autores da API adicionem métodos a uma interface em versões posteriores sem quebrar a compatibilidade de origem ou binária com as implementações existentes dessa interface. As implementações existentes herdam a implementação padrão. Esse recurso também permite que o C# interopere com APIs voltadas para Android ou Swift, que oferecem suporte a recursos semelhantes. Os métodos de interface padrão também permitem cenários semelhantes a um recurso de linguagem de "características".
Os métodos de interface padrão afetam muitos cenários e elementos de linguagem. Por esse tutorial você pode definir uma implementação ao declarar um membro de uma interface. O cenário mais comum é adicionar membros com segurança a uma interface já lançada e usada por inúmeros clientes. Neste tutorial, você aprenderá como:
- Estenda interfaces com segurança adicionando métodos com implementações.
- Crie implementações parametrizadas para fornecer maior flexibilidade.
- Permita que os implementadores forneçam uma implementação mais específica na forma de uma substituição.
Uma empresa que construiu uma biblioteca pretendia que os clientes com aplicativos existentes adotassem sua biblioteca. Eles forneceram definições mínimas de interface para os usuários de sua biblioteca implementarem. Esta é a definição de interface para um cliente:
public interface ICustomer
{
IEnumerable<IOrder> PreviousOrders { get; }
DateTime DateJoined { get; }
DateTime? LastOrder { get; }
string Name { get; }
IDictionary<DateTime, string> Reminders { get; }
}Eles definiram uma segunda interface que representa um pedido:
public interface IOrder
{
DateTime Purchased { get; }
decimal Cost { get; }
}A partir dessas interfaces, a equipe poderia construir uma biblioteca para seus usuários, a fim de criar uma experiência melhor para seus clientes. Depois de um tempo, chega a hora de atualizar a biblioteca para a próxima versão.
Um dos recursos solicitados permite um desconto de fidelidade para clientes que têm muitos pedidos. Este novo desconto de fidelidade é aplicado sempre que um cliente faz um pedido. O desconto específico é propriedade de cada cliente individual. Cada implementação de ICustomer pode definir regras diferentes para o desconto de fidelidade. A maneira mais natural de adicionar essa funcionalidade é aprimorar a interface ICustomer com um método para aplicar qualquer desconto de fidelidade. Esta sugestão de design causou preocupação entre os desenvolvedores experientes: "As interfaces são imutáveis depois de serem lançadas! Esta é uma alteração “breaking change”!"
Para que isso não ocorra mais, o C# 8.0 adiciona implementações de interface padrão para atualização de interfaces. Os autores da biblioteca podem adicionar novos membros à interface e fornecer uma implementação padrão para esses membros. As implementações de interface padrão permitem que os desenvolvedores atualizem uma interface enquanto ainda permitem que qualquer implementador substitua essa implementação. Os usuários da biblioteca podem aceitar a implementação padrão como uma alteração ininterrupta. Se suas regras de negócios forem diferentes, eles podem ser substituidas.
A equipe concordou com a implementação padrão mais provável: um desconto de fidelidade para clientes. A atualização deve fornecer a funcionalidade para definir duas propriedades:
- o número de pedidos necessários para ter direito ao desconto
- a porcentagem do desconto.
Isso o torna um cenário perfeito para métodos de interface padrão. Você pode adicionar um método à ICustomerinterface e fornecer a implementação mais provável. Todas as implementações existentes e quaisquer novas podem usar a implementação padrão ou fornecer a sua própria. Primeiro, adicione o novo método à interface ICustomer, incluindo o corpo do método:
// Version 1 : HARD CODE
public decimal ComputeLoyaltyDiscount()
{
DateTime TwoYearsAgo = DateTime.Now.AddYears(-2);
if ((DateJoined < TwoYearsAgo) && (PreviousOrders.Count() > 1))
{
return 0.10m;
}
return 0;
}O autor da biblioteca escreveu um primeiro teste para verificar a implementação:
static void Main(string[] args)
{
SampleCustomer c = new SampleCustomer("customer one", new DateTime(2010, 5, 31))
{
Reminders =
{
{ new DateTime(2010, 08, 12), "childs's birthday" },
{ new DateTime(1012, 11, 15), "anniversary" }
}
};
SampleOrder o = new SampleOrder(new DateTime(2012, 6, 1), 5m);
c.AddOrder(o);
o = new SampleOrder(new DateTime(2103, 7, 4), 25m);
c.AddOrder(o);
// Check the discount:
ICustomer theCustomer = c;
Console.WriteLine($"Current discount: {theCustomer.ComputeLoyaltyDiscount()}"); // 0,10
}O Cast de SampleCustomer para ICustomer é necessário. A classe SampleCustomer não precisa fornecer uma implementação para ComputeLoyaltyDiscount; que é fornecido pela interface ICustomer.
public class SampleCustomer : ICustomer
{
public SampleCustomer(string name, DateTime dateJoined) =>
(Name, DateJoined) = (name, dateJoined);
private List<IOrder> allOrders = new List<IOrder>();
public IEnumerable<IOrder> PreviousOrders => allOrders;
public DateTime DateJoined { get; }
public DateTime? LastOrder { get; private set; }
public string Name { get; }
private Dictionary<DateTime, string> reminders = new Dictionary<DateTime, string>();
public IDictionary<DateTime, string> Reminders => reminders;
public void AddOrder(IOrder order)
{
if (order.Purchased > (LastOrder ?? DateTime.MinValue))
LastOrder = order.Purchased;
allOrders.Add(order);
}
}
public class SampleOrder : IOrder
{
public SampleOrder(DateTime purchase, decimal cost) =>
(Purchased, Cost) = (purchase, cost);
public DateTime Purchased { get; }
public decimal Cost { get; }
}No entanto, a classe SampleCustomer não herda membros de suas interfaces. Essa regra não mudou. Para chamar qualquer método declarado e implementado na interface, a variável deve ser o tipo da interface, ICustomer neste exemplo.
Porém, a implementação padrão é muito restritiva, pois os consumidores desse sistema gostariam de escolher limites diferentes para o número de compras, um período de assinatura diferente ou um desconto percentual diferente. O ideal seria ser possível fornecer uma maneira de definir esses parâmetros. Vamos adicionar um método estático que define esses três parâmetros que controlam a implementação padrão:
// Version 2: PARAMETERS !!!
public static void SetLoyaltyThresholds(
TimeSpan ago,
int minimumOrders = 1,
decimal percentageDiscount = 0.10m)
{
length = ago;
orderCount = minimumOrders;
discountPercent = percentageDiscount;
}
private static TimeSpan length = new TimeSpan(365 * 2, 0, 0, 0); // two years
private static int orderCount = 1;
private static decimal discountPercent = 0.10m;
public decimal ComputeLoyaltyDiscount()
{
DateTime start = DateTime.Now - length;
if ((DateJoined < start) && (PreviousOrders.Count() > orderCount))
{
return discountPercent;
}
return 0;
}Existem muitos novos recursos de linguagem mostrados nesse pequeno fragmento de código. As interfaces agora podem incluir membros estáticos, incluindo campos e métodos. Diferentes modificadores de acesso também estão ativados. Os campos adicionais são privados, o novo método é público. Qualquer um dos modificadores é permitido em membros da interface.
Os aplicativos que usam a fórmula geral para calcular o desconto de fidelidade, mas parâmetros diferentes, não precisam fornecer uma implementação personalizada; eles podem definir os argumentos por meio de um método estático. Por exemplo, o código a seguir define uma "apreciação do cliente" que recompensa qualquer cliente com mais de um mês de assinatura:
ICustomer theCustomer = c;
ICustomer.SetLoyaltyThresholds(new TimeSpan(30, 0, 0, 0), 1, 0.25m);
Console.WriteLine($"Current discount: {theCustomer.ComputeLoyaltyDiscount()}"); // 0,25Para um recurso final, vamos refatorar o código um pouco para habilitar cenários onde os usuários podem querer construir sobre a implementação padrão. Considere uma startup que deseja atrair novos clientes. Eles oferecem um desconto de 50% no primeiro pedido de um novo cliente. Caso contrário, os clientes existentes obtêm o desconto padrão. O autor da biblioteca precisa mover a implementação padrão para um método protected static para que qualquer classe que implemente essa interface possa reutilizar o código em sua implementação. A implementação padrão do membro da interface também chama este método compartilhado:
// Version 3: EXTENDED DEFAULT INTERFACE !!!
public decimal ComputeLoyaltyDiscount() => DefaultLoyaltyDiscount(this);
protected static decimal DefaultLoyaltyDiscount(ICustomer c)
{
DateTime start = DateTime.Now - length;
if ((c.DateJoined < start) && (c.PreviousOrders.Count() > orderCount))
{
return discountPercent;
}
return 0;
}Em uma implementação de uma classe que implementa essa interface, a substituição pode chamar o método auxiliar estático e estender essa lógica para fornecer o desconto de "novo cliente", adicione na classe SampleCustomer:
public decimal ComputeLoyaltyDiscount()
{
if (PreviousOrders.Any() == false)
return 0.50m;
else
return ICustomer.DefaultLoyaltyDiscount(this);
}Esses novos recursos significam que as interfaces podem ser atualizadas com segurança quando há uma implementação padrão razoável para esses novos membros. Projete interfaces cuidadosamente para expressar ideias funcionais únicas que podem ser implementadas por várias classes. Isso torna mais fácil atualizar essas definições de interface quando novos requisitos são descobertos para a mesma ideia funcional.
A correspondência de Pattern fornece ferramentas para fornecer funcionalidade dependente da forma em diferentes tipos de dados relacionados. C# 7.0 introduziu a sintaxe para Pattern de tipo e Pattern constantes usando a expressão “is” e a instrução “switch”. Esses recursos representaram as primeiras etapas provisórias para suportar paradigmas de programação onde dados e funcionalidade vivem separados. À medida que a indústria avança em direção a mais microsserviços e outras arquiteturas baseadas em nuvem, outras ferramentas de linguagem são necessárias.
C# 8.0 expande esse vocabulário para que você possa usar mais expressões de Pattern em mais lugares em seu código. Considere esses recursos quando seus dados e funcionalidade forem separados. Considere a correspondência de Pattern quando seus algoritmos dependerem de um fato diferente do tipo de tempo de execução de um objeto. Essas técnicas fornecem outra maneira de expressar projetos.
Além de novos Pattern em novos lugares, C# 8.0 adiciona Pattern recursivos. O resultado de qualquer expressão de padrão é uma expressão. Um padrão recursivo é simplesmente uma expressão de padrão aplicada à saída de outra expressão de padrão.
Freqüentemente, expressões switch produzem um valor em cada um de seus blocos case. As novas expressões switch permitem que você use uma sintaxe de expressão mais concisa, com menos case-break e menos chaves. Como exemplo, considere o seguinte enum que lista as cores do arco-íris:
public enum Rainbow
{
Red,
Orange,
Yellow
}
public class RGBColor
{
public String ColorHex;
public RGBColor(byte R, byte G, byte B)
{
var color = System.Drawing.Color.FromArgb(R, G, B);
ColorHex = color.Name;
}
}Se seu aplicativo definiu um tipo RGBColor que é construído a partir dos componentes R, Ge B, você poderia converter um valor Rainbow em seus valores RGB usando o seguinte método contendo uma expressão switch:
public static RGBColor FromRainbow(Rainbow colorBand) =>
colorBand switch
{
Rainbow.Red => new RGBColor(0xFF, 0x00, 0x00),
Rainbow.Orange => new RGBColor(0xFF, 0x7F, 0x00),
Rainbow.Yellow => new RGBColor(0xFF, 0xFF, 0x00),
_ => throw new ArgumentException(message: "invalid enum value", paramName: nameof(colorBand)),
};
var cor = FromRainbow(Rainbow.Yellow);
Console.WriteLine("HEX:" + cor.ColorHex);Onde:
- A variável vem antes da palavra - chave switch. A ordem diferente torna visualmente fácil distinguir a expressão switch da instrução switch.
- O elemento “case :” é substituído por “=>”. É mais conciso e intuitivo.
- O caso default é substituído por um “_ “ .
- Os corpos são expressões, não afirmações.
O Pattern de propriedade permite que você combine as propriedades do objeto examinado. Considere um site de comércio eletrônico que deve calcular o imposto sobre vendas com base no endereço do comprador. Esse cálculo não é uma responsabilidade central de uma classe Address. Ele mudará com o tempo, provavelmente com mais frequência do que as alterações de formato de endereço. O valor do imposto sobre vendas depende da propriedade State do endereço. O método a seguir usa o Pattern de propriedade para calcular o imposto sobre vendas a partir do endereço e do preço:
public class Address
{
public string State { get; set; }
}
public static decimal ComputeSalesTax(Address location, decimal salePrice) =>
location switch
{
{ State: "WA" } => salePrice * 0.06M,
{ State: "MN" } => salePrice * 0.075M,
{ State: "MI" } => salePrice * 0.05M,
// other cases removed for brevity...
_ => 0M
};
var preco = ComputeSalesTax(new Address() { State= "MN" }, 3);
Console.WriteLine("Preço:" + preco);A correspondência de padrões cria uma sintaxe concisa para expressar esse algoritmo.
Alguns algoritmos dependem de várias entradas. Os Pattern de tupla permitem que você alterne com base em vários valores expressos como uma tupla. O código a seguir mostra uma expressão de switch para a pedra, papel e tesoura do jogo :
public static RGBColor FromRainbow(Rainbow colorBand) =>
colorBand switch
{
Rainbow.Red => new RGBColor(0xFF, 0x00, 0x00),
Rainbow.Orange => new RGBColor(0xFF, 0x7F, 0x00),
Rainbow.Yellow => new RGBColor(0xFF, 0xFF, 0x00),
Rainbow.Green => new RGBColor(0x00, 0xFF, 0x00),
Rainbow.Blue => new RGBColor(0x00, 0x00, 0xFF),
Rainbow.Indigo => new RGBColor(0x4B, 0x00, 0x82),
Rainbow.Violet => new RGBColor(0x94, 0x00, 0xD3),
_ => throw new ArgumentException(message: "invalid enum value", paramName: nameof(colorBand)),
};
var jankenpo = RockPaperScissors("paper", "scissors");
Console.WriteLine("Resultado:" + jankenpo);As mensagens indicam o vencedor. O caso de descarte representa as três combinações de empates ou outras entradas de texto.
Alguns tipos incluem um método Deconstruct que desconstrói suas propriedades em variáveis discretas. Quando um método Deconstruct está acessível, você pode usar Pattern posicionais para inspecionar propriedades do objeto e usar essas propriedades para um Pattern. Considere a seguinte classe Point que inclui um método Deconstruct para criar variáveis discretas para X e Y:
public class Point
{
public int X { get; }
public int Y { get; }
public Point(int x, int y) => (X, Y) = (x, y);
public void Deconstruct(out int x, out int y) =>
(x, y) = (X, Y);
}Além disso, considere o seguinte enum que representa várias posições de um quadrante:
public enum Quadrant
{
Unknown,
Origin,
One,
Two,
Three,
Four,
OnBorder
}O método a seguir usa o padrão posicional para extrair os valores de X e Y. Em seguida, ele usa uma cláusula when para determinar o Quadrant do ponto:
static Quadrant GetQuadrant(Point point) => point switch
{
(0, 0) => Quadrant.Origin,
var (x, y) when x > 0 && y > 0 => Quadrant.One,
var (x, y) when x < 0 && y > 0 => Quadrant.Two,
var (x, y) when x < 0 && y < 0 => Quadrant.Three,
var (x, y) when x > 0 && y < 0 => Quadrant.Four,
var (_, _) => Quadrant.OnBorder,
_ => Quadrant.Unknown
};
var posicao = GetQuadrant(new Point(10, 2));
Console.WriteLine("Posição:" + posicao);O padrão de descarte na opção anterior corresponde quando X ou Y é 0, mas não ambos. Uma expressão switch deve produzir um valor ou lançar uma exceção. Se nenhum dos casos corresponder, a expressão switch lançará uma exceção. O compilador gera um aviso para você se você não cobrir todos os casos possíveis em sua expressão switch. Você pode explorar técnicas de correspondência de padrões neste tutorial avançado sobre correspondência de padrões.
Uma declaração using é uma declaração de variável precedida pela palavra-chave using. Diz ao compilador que a variável que está sendo declarada deve ser descartada no final do escopo delimitador. Por exemplo, considere o seguinte código que grava um arquivo de texto:
static int WriteLinesToFile(IEnumerable<string> lines)
{
using var file = new System.IO.StreamWriter("WriteLines2.txt");
// Notice how we declare skippedLines after the using statement.
int skippedLines = 0;
foreach (string line in lines)
{
if (!line.Contains("Second"))
{
file.WriteLine(line);
}
else
{
skippedLines++;
}
}
// Notice how skippedLines is in scope here.
return skippedLines;
// file is disposed here
}
IEnumerable<string> m_oEnum = new List<string>() { "1", "2", "3" };
IEnumerable<string> m_oArray = new string[] { "1", "2", "3" };
IEnumerable<string> myStrings = new[] { "first item", "Second item" };
WriteLinesToFile(myStrings);No exemplo anterior, o arquivo é descartado quando a chave de fechamento do método é atingida. Esse é o fim do escopo em que fileé declarado. Na nova sintaxe e na using clássica, o compilador gera a chamada para Dispose(). O compilador gera um erro se a expressão na instrução using não for descartável.
Agora você pode adicionar o modificador static às funções locais para garantir que a função local não capture (faça referência) nenhuma variável do escopo delimitador. Fazer isso gera:
"A static local function can't contain a reference to <variable>."Considere o seguinte código. A função local LocalFunction acessa a variável y, declarada no escopo envolvente (o método M). Portanto, LocalFunction não pode ser declarado com o modificador static:
public int M()
{
int y;
LocalFunction();
return y;
void LocalFunction() => y = 0;
}O código a seguir contém uma função local estática. Pode ser estático porque não acessa nenhuma variável no escopo envolvente:
public int M_Est()
{
int y = 5;
int x = 7;
return Add(x, y);
static int Add(int left, int right) => left + right;
}Os Ref structs foram introduzidos no C# 7.2, e tinham algumas limitações severas, como não ser capaz de implementar interfaces. Os Ref structs não podem implementar interface porque os exporia à possibilidade de boxing. Mas por causa disso, não podemos torná-los implementando IDisposable e, portanto, não podemos usá-los nas instruções using.
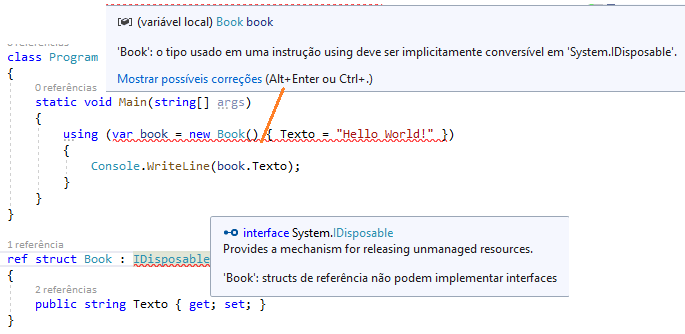
Portanto, ao projetar um tipo que possui algum recurso, gostaríamos de ter alguma possibilidade de limpeza explícita. Em C#, a escolha é óbvia - temos um contrato bem conhecido na forma de interface IDisposable e seu método Dispose. Mas como já foi dito, até C# 8.0 ele não podia ser usado em estruturas Ref. As estruturas Ref agora podem ser descartáveis sem implementar a interface IDisposable. Para permitir que um ref struct seja descartado, ele deve ter um void método público Dispose(). Este recurso também se aplica as declarações readonly ref struct. Além disso, devido às mudanças na própria instrução using, agora podemos usar uma forma mais concisa de usar a instrução using:
class Program
{
static void Main(string[] args)
{
using (var book = new Book() { Texto = "Hello World!" })
Console.WriteLine(book.Texto);
}
}
ref struct Book
{
public string Texto { get; set; }
public void Dispose()
{
}
}Poderíamos ter introduzido o método Dispose para limpá-lo no final do uso, assim:
var book1 = new Book() { Texto = "Hello World!" };
Console.WriteLine(book1.Texto);
book1.Dispose();Isso é obviamente complicado, pois precisamos nos lembrar de como chamar Dispose. E o tratamento de exceções não é tratado adequadamente aqui. É por isso que using statement foi introduzido, para ter certeza de que será chamado por baixo.
Em geral a limpeza explícita (finalização determinística) é preferida em vez de implícita (finalização não determinística). Isso é de alguma forma intuitivo. É melhor fazer uma limpeza explicitamente assim que possível (chamando Close, Dispose ou usando a instrução), em vez de esperar pela limpeza não explícita que ocorrerá “em algum momento” (pelos finalizadores de execução do tempo de execução).
Tipos de referência anuláveis já foram considerados nos estágios iniciais de desenvolvimento do C# 7.0, mas foram adiados para a próxima versão principal. O objetivo deste recurso é ajudar os desenvolvedores a evitar exceções NullReferenceException não tratadas e ajudam a evitar erros de referência nula em tempo de compilação.
Para lidar com isso, a análise estática para segurança nula pode ser habilitada seletivamente com uma chave do compilador no nível do projeto. A opção é mantida como uma propriedade no arquivo de projeto. Ainda não há interface do usuário no Visual Studio 2019 para alterar seu valor. Para habilitá-lo, adicione manualmente ao primeiro elemento PropertyGroup do arquivo de projeto. csproj.
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp3.1</TargetFramework>
<Nullable>enable</Nullable>
</PropertyGroup>
</Project>
Definindo para um projeto usando o Nullable configura como o compilador interpreta a nulidade de tipos e quais avisos são gerados. As configurações válidas são:
| Configuração | Descrição |
|---|---|
| enable | O contexto de anotação anulável está habilitado. O contexto de aviso que permite valor nulo está habilitado. Variáveis de um tipo de referência, string por exemplo, não permitem valor nulo. Todos os avisos de nulidade estão habilitados. |
| warnings | O contexto de anotação anulável está desabilitado. O contexto de aviso que permite valor nulo está habilitado. As variáveis de um tipo de referência são óbvias. Todos os avisos de nulidade estão habilitados. |
| annotations | O contexto de anotação anulável está habilitado. O contexto de aviso que permite valor nulo está desabilitado. Variáveis de um tipo de referência, String, por exemplo, são não anuláveis. Todos os avisos de nulidade estão desabilitados. |
| disable | O contexto de anotação anulável está desabilitado. O contexto de aviso que permite valor nulo está desabilitado. As variáveis de um tipo de referência são alheias, como as versões anteriores do C#. Todos os avisos de nulidade estão desabilitados. |
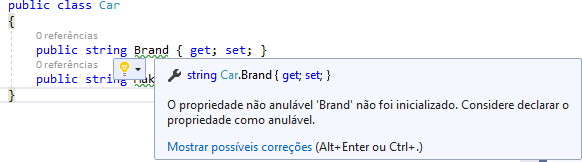
Depois de adicionar essa tag, você verá dois avisos do compilador e efeitos visuais nas propriedades. Como uma alternativa mais rápida ao uso de um campo de apoio anulável, ou se a biblioteca que instancia sua classe não for compatível com essa abordagem, você pode simplesmente inicializar a propriedade como nula diretamente, com a ajuda do operador de tolerância nula (!):
public class Car
{
public string Brand { get; set; } = null!;
public string Make { get; set; } = null!;
}Dentro de um contexto de anotação anulável, qualquer variável de um tipo de referência é considerada um tipo de referência não anulável. Se você deseja indicar que uma variável pode ser nula, você deve anexar o nome do tipo com o ? (Elvis operator) para declarar a variável como um tipo de referência anulável. A ideia central é permitir que as definições de tipo de variável especifiquem se podem ter um valor nulo atribuído a elas ou não:
string nome = null; Warning: Assignment of null to non-nullable reference type
string? nome = null; OKAtribuir um valor nulo ou um valor nulo potencial a uma variável não anulável resulta em um aviso do compilador. Da mesma forma, avisos são gerados desreferenciar a referência de uma variável anulável sem verificar primeiro o valor nulo:
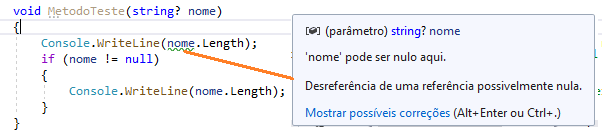
Uma propriedade não pode ser nula, mas o compilador ainda avisa. Então você pode dizer ao compilador que essa propriedade nunca é nula usando o ! operador.
void MetodoTeste(string? nome)
{
Console.WriteLine(nome!.Length);
}Para tipos de referência não anuláveis, o compilador usa análise de fluxo para garantir que as variáveis locais sejam inicializadas com um valor não nulo quando declaradas. Os campos devem ser inicializados durante a construção. O compilador gera um aviso se a variável não for definida por uma chamada a qualquer um dos construtores disponíveis ou por um inicializador. Além disso, os tipos de referência não anuláveis não podem receber um valor que poderia ser nulo. Quando variáveis não devem ser nulas, o compilador impõe regras que garantem que é seguro desreferenciar essas variáveis sem primeiro verificar se ela não é nula:
- A variável deve ser inicializada para um valor não nulo.
- A variável nunca pode receber o valor null.
Os tipos de referência anuláveis não são verificados para garantir que não sejam atribuídos ou inicializados como nulos. No entanto, o compilador usa a análise de fluxo para garantir que qualquer variável de um tipo de referência anulável seja verificada em relação a nulo antes de ser acessada ou atribuída a um tipo de referência não anulável. Quando variáveis puderem ser nulas, o compilador imporá diferentes regras para garantir que você verificou corretamente se há uma referência nula:
- A variável só poderá ser desreferenciada quando o compilador puder garantir que o valor não é nulo.
- Essas variáveis podem ser inicializadas com o valor null padrão e receber o valor null em outro código.
Para obter mais granularidade, as diretivas de aviso #pragma podem ser usadas para desativar e reativar avisos individuais para um bloco de código. Como alternativa, uma nova diretiva #nullable foi adicionada.
| Diretivas | Descrição |
|---|---|
| #nullable enable | Define o contexto de anotação anulável e o contexto de aviso anulável como habilitado. |
| #nullable disable | Define o contexto de anotação anulável e o contexto de aviso anulável como desabilitado. |
| #nullable restore | Restaura o contexto de anotação anulável e o contexto de aviso anulável para as configurações do projeto. |
| #nullable disable warnings | Defina o contexto de aviso anulável como desabilitado. |
| #nullable enable warnings | Defina o contexto de aviso anulável como habilitado. |
| #nullable restore warnings | Restaura o contexto de aviso anulável para as configurações do projeto. |
| #nullable disable annotations | Defina o contexto de anotação anulável como desabilitado. |
| #nullable enable annotations | Defina o contexto de anotação anulável como habilitado. |
| #nullable restore annotations | Restaura o contexto de aviso de anotação para as configurações do projeto. |
Ele pode ser usado para ativar o suporte a tipos de referência anuláveis para um bloco de código, mesmo se estiver desativado no nível do projeto:
#nullable enable
string cantBeNull = null; /* Aviso*/
string? canBeNull = null; /*OK*/
cantBeNull = canBeNull; // Aviso
#nullable restoreÉ uma boa ideia usar #nullable restore em vez de #nullable disable para desativar os tipos de referência anuláveis para o código a seguir. Isso garantirá que as verificações permaneçam habilitadas para o resto do arquivo se você decidir habilitar o recurso para todo o projeto posteriormente. Usar #nullable disable desabilitaria as verificações mesmo nesse caso.
A primeira opção é se os tipos de referência anuláveis devem estar ativados ou desativados por padrão. Você tem duas estratégias:
- Habilite tipos de referência anuláveis para o projeto inteiro e desabilite-o no código que não está pronto.
- Só habilite tipos de referência anuláveis para o código anotado para tipos de referência anuláveis.
A primeira estratégia funciona melhor quando você está adicionando outros recursos à biblioteca ao atualizá-los para tipos de referência anuláveis. Todo o novo desenvolvimento tem reconhecimento anulável. À medida que você atualiza o código existente, você habilita os tipos de referência anuláveis nessas classes.
Seguindo essa primeira estratégia, faça o seguinte:
- Habilite tipos de referência anuláveis para todo o projeto
<Nullable>enable</Nullable>adicionando o elemento aos seus arquivos csproj . - Adicione o #nullable disable pragma a cada arquivo de origem em seu projeto.
- Conforme você trabalha em cada arquivo, remova o pragma e resolva os avisos.
Essa primeira estratégia tem mais trabalho antecipado para adicionar o pragma a cada arquivo. A vantagem é que todos os novos arquivos de código adicionados ao projeto serão habilitados para permitir valor nulo. Qualquer trabalho novo terá reconhecimento de Nullable; somente o código existente deve ser atualizado.
A segunda estratégia funciona melhor se a biblioteca costuma ser estável e o foco principal do desenvolvimento é adotar tipos de referência anuláveis. Você ativa os tipos de referência anuláveis ao anotar APIs. Quando tiver terminado, habilite os tipos de referência anuláveis para o projeto inteiro.
Seguindo essa segunda estratégia, você faz o seguinte:
- Adicione o #nullable enable pragma ao arquivo que você deseja que o reconheça de forma anulável.
- Resolva os avisos.
- Continue essas duas primeiras etapas até que você tenha feito o reconhecimento de toda a biblioteca.
- Habilite tipos anuláveis para todo o projeto adicionando
<Nullable>enable</Nullable>o elemento aos seus arquivos csproj . - Remova os #nullable enable pragmas, pois eles não são mais necessários.
Essa segunda estratégia tem menos trabalho de antecedência. A desvantagem é que a primeira tarefa quando você cria um novo arquivo é adicionar o pragma e torná-lo indesejado de forma anulável. Se algum desenvolvedor da sua equipe esquecer, esse novo código estará no registro posterior do trabalho para tornar todos os incompatíveis com o código anulável.
Qual dessas estratégias você escolhe depende de quanto o desenvolvimento ativo está ocorrendo em seu projeto. Quanto mais maduro e estável for seu projeto, melhor a segunda estratégia. Quanto mais recursos estiverem sendo desenvolvidos, melhor será a primeira estratégia.
O C# 5 já era possível ter suporte para iteradores e recursos assíncronos, como aguardar um resultado com await e async. Portanto, uma armadilha comum para cair pode ser que você queira usar um tipo de retorno de Task<IEnumerable<T>> e torná-lo assíncrono. Algo assim:
public static async void EscreverForeach()
{
foreach (var dataPoint in await FetchIOTData())
{
Console.WriteLine("Foreach: " + dataPoint);
}
}
static async Task<IEnumerable<int>> FetchIOTData()
{
List<int> dataPoints = new List<int>();
for (int i = 1; i <= 10; i++)
{
await Task.Delay(1000);//Simulate waiting for data to come through.
dataPoints.Add(i);
}
return dataPoints;
}Se rodássemos esse aplicativo, nada apareceria por 10 segundos, e então veríamos todos os nossos pontos de dados de uma vez. Não será o bloqueio de thread, ainda é assíncrono, mas não recebemos os dados assim que os recebemos. Observe que estamos percorrendo todos os resultados em um loop while, instanciando todos os objetos de produto, colocando-os em um List<int> e, por fim, retornamos tudo. Isso é bastante ineficiente, especialmente para conjuntos de dados maiores. É menos IEnumerable e mais parecido com um List<T>. O que realmente queremos é ser capaz de usar a palavra-chave yield, para retornar os dados conforme os recebemos para serem processados imediatamente.
Em vez de retornar a Task<IEnumerable<T>>, nosso método agora pode retornar IAsyncEnumerable<T> e usar yield return para emitir dados. No C# 8, em vez de retornar a Task<IEnumerable<T>>, nosso método agora pode retornar IAsyncEnumerable<T> (baseados nas interfaces IEnumerable e IEnumerator) e usar yield return para emitir dados. Os dois combinados em fluxos assíncronos podem ser muito útil se você estiver desenvolvendo um aplicativo IoT e estiver lidando com muitas chamadas assíncronas retornando dados. Com o IOT se tornando cada vez maior, faz sentido para C# adicionar uma maneira de iterar em um IEnumerable de maneira assíncrona enquanto usa a palavra-chave yield para obter dados conforme eles chegam. Por exemplo, recuperar sinais de dados de um de IOT, deseja receber dados e processá-los à medida que são recuperados, mas não de uma forma que bloqueie a CPU enquanto esperamos. Um método que retorna um fluxo assíncrono tem três propriedades:
- É declarado com o modificador async.
- Ele retorna um
IAsyncEnumerable<T>. - O método contém instruções yield return para retornar elementos sucessivos no fluxo assíncrono.
public interface IAsyncEnumerable<out T>
{
IAsyncEnumerator<T> GetAsyncEnumerator();
//OU IAsyncEnumerator<T> GetAsyncEnumerator(CancellationToken cancellationToken = default);
}
public interface IAsyncEnumerator<out T> : IAsyncDisposable
{
T Current { get; }
ValueTask<bool> MoveNextAsync();
}Além disso, uma versão assíncrona da interface IDisposable é necessária para consumir os iteradores assíncronos:
public interface IAsyncDisposable
{
ValueTask DisposeAsync();
}Isso permite que o seguinte código seja usado para iterar os itens:
public static async void EscreverWhile()
{
var asyncEnumerator = GenerateSequence().GetAsyncEnumerator();
try
{
while (await asyncEnumerator.MoveNextAsync())
{
var value = asyncEnumerator.Current;
Console.WriteLine("While: " + value);
}
}
finally
{
await asyncEnumerator.DisposeAsync();
}
}É muito semelhante ao código que usamos para consumir iteradores síncronos regulares. No entanto, não parece familiar porque normalmente usamos apenas a instrução foreach. Uma versão assíncrona da instrução foreach está disponível para iteradores assíncronos:
public static async void EscreverForeach()
{
await foreach (var number in GenerateSequence())
{
Console.WriteLine("Foreach: " + number);
}
}Consumir um fluxo assíncrono requer que você adicione a palavra-chave await antes da palavra-chave foreach ao enumerar os elementos do fluxo. Adicionar a palavra-chave await requer que o método que enumera o fluxo assíncrono seja declarado com o modificador async e retorne um tipo permitido para um método async. Normalmente, isso significa retornar uma Task ou Task<TResult>. Também pode ser ValueTask ou ValueTask<TResult>. Um método pode consumir e produzir um fluxo assíncrono, o que significa que ele retornaria um IAsyncEnumerable<T>. O código a seguir gera uma sequência de 0 a 19, esperando 100 ms entre a geração de cada número:
public static async IAsyncEnumerable<int> GenerateSequence()
{
for (int i = 0; i < 20; i++)
{
await Task.Delay(100);
yield return i;
}
}Você deve ter notado o parâmetro CancelamentoToken do método GetAsyncEnumerator da interface IAsyncEnumerable<T>. Como seria de se esperar, ele pode ser usado para suportar o cancelamento de fluxos assíncronos. Em qualquer ponto durante a enumeração, se o cancelamento for solicitado, uma chamada MoveNextAsync subsequente ou em andamento pode ser interrompida e lançar uma OperationCanceledException (ou algum tipo derivado , como uma TaskCanceledException). Isso levanta duas questões:
- Se o token precisa ser passado para GetAsyncEnumerator, mas é o compilador que está gerando a chamada GetAsyncEnumerator para meu await foreach, como faço para passar um token?
- Se o token for passado para GetAsyncEnumerator e for o compilador que está gerando a implementação GetAsyncEnumerator para meu método iterador assíncrono, de onde obtenho o token passado?
A resposta para a primeira pergunta é que há um método de extensão WithCancellation para IAsyncEnumerable <T>. Ele aceita um CancellationToken como argumento e retorna um tipo de struct personalizado que aguarda foreach se vincula por meio de um padrão em vez de por meio da interface IAsyncEnumerable<T>, permitindo que você escreva código como o seguinte:
await foreach (var number in RangeAsync(1, 10).WithCancellation(token))
{
Console.WriteLine("Foreach: " + number);
}Essa mesma vinculação baseada em padrão também é usada para habilitar um método ConfigureAwait, que também pode ser encadeado em um design fluente com WithCancellation:
await foreach (var number in RangeAsync(1, 10).WithCancellation(token).ConfigureAwait(false))
{
Console.WriteLine("Foreach: " + number);
}A resposta à segunda pergunta é um novo atributo [EnumeratorCancellation]. Você pode adicionar um parâmetro CancellationToken ao método iterador assíncrono e anotá-lo com este atributo. Ao fazer isso, o compilador gerará um código que fará com que o token passado para GetAsyncEnumerator fique visível para o corpo do iterador assíncrono como esse argumento:
static async IAsyncEnumerable<int> RangeAsync(int start, int count,
[EnumeratorCancellation] CancellationToken cancellationToken = default)
{
for (int i = 0; i < count; i++)
{
await Task.Delay(i, cancellationToken);
yield return start + i;
}
}Isso significa que se você escrever este código:
var cts = new CancellationTokenSource(TimeSpan.FromSeconds(0.2));
await foreach (var number in RangeAsync(1, 10).WithCancellation(cts.Token).ConfigureAwait(false))
{
Console.WriteLine("Foreach: " + number);
}O código dentro de RangeAsync verá seu parâmetro cancellationToken igual a cts.Token. Claro, porque o token é um parâmetro normal para o método iterador, também é possível passar o token diretamente como um argumento:
await foreach (var number in RangeAsync(1, 10, cts.Token).ConfigureAwait(false))
{
Console.WriteLine("Foreach: " + number);
}Nesse caso, o corpo do iterador assíncrono verá cts.Token como seu cancellationToken. Passar o token diretamente para o método é mais fácil, mas não funciona quando você recebe um IAsyncEnumerable arbitrário de alguma outra fonte, mas ainda deseja poder solicitar o cancelamento de tudo o que o compõe. Em casos extremos, também pode ser vantajoso passar o token para GetAsyncEnumerator, pois isso evita "queimar" o token no caso em que o único enumerável será enumerado várias vezes: ao passá-lo para GetAsyncEnumerator, um token diferente pode ser passado cada vez. Claro, também é possível que dois tokens diferentes acabem sendo passados para o mesmo iterador, um como um argumento para o iterador e outro via GetAsyncEnumerator. Nesse caso, o código gerado pelo compilador lida com isso criando um novo token vinculado que terá o cancelamento solicitado quando um dos dois tokens tiver o cancelamento solicitado, e esse novo token “combinado” será aquele que o corpo do iterador vê.
Todo desenvolvedor .NET irá, mais cedo ou mais tarde, usar o método Dispose() (indiretamente com uma instrução using) e implementar o IDisposable. O padrão para descartar um objeto está disponível como um conceito no .NET há muito tempo, desde o .NET Framework 1.1. Considere estes dois métodos DoWorkAsync:
public static Task DoWorkAsync()
{
var arg1 = ComputeArg();
var arg2 = ComputeArg();
return AwaitableMethodAsync(arg1, arg2);
}
public static async Task DoWork2Async()
{
var arg1 = ComputeArg();
var arg2 = ComputeArg();
await AwaitableMethodAsync(arg1, arg2);
}
static public Task ComputeArg()
{
return Task.Run(() =>
{
Console.WriteLine($"{nameof(ComputeArg)} starting...");
Task.Delay(1000).Wait();
Console.WriteLine($"{nameof(ComputeArg)} ending...");
});
}
public static async Task<string> AwaitableMethodAsync(Task arg1, Task arg)
{
using (System.Net.Http.HttpClient client = new System.Net.Http.HttpClient())
{
string result = await client.GetStringAsync("http://www.microsoft.com");
return result;
}
}O primeiro é um método síncrono que retorna uma Tarefa. A tarefa pode ou não ter sido concluída quando o método retornar. O segundo como um método assíncrono que retorna o resultado da espera de outro trabalho. Esses dois métodos parecem quase iguais, mas o código gerado pelo compilador para eles é muito diferente. Na maioria dos casos, você deve preferir escrever a primeira versão, quando possível. O método é muito mais simples e muito mais fácil de raciocinar. É um método síncrono que retorna um objeto que representa um trabalho que pode estar em andamento.
O segundo constrói uma máquina de estado. Ele gerencia a reentrada para o código que deve ser executado quando a tarefa esperada terminar. Quando finaliza a tarefa, ele retorna e retoma a execução. Você pode escrever a primeira versão para qualquer método de retorno de tarefa que poderia ser um método síncrono. É o caso quando:
- O método não faz nenhum trabalho depois que o único método de retorno de tarefa é chamado.
- O retorno do único método de retorno de tarefa corresponde à assinatura deste método.
A introdução de uma variável local que se refere a um objeto que o IDisposable implementa ficaria assim:
public class DisposableFoo : IDisposable
{
private bool disposed = false;
private HttpClient client;
public DisposableFoo()
{
client = = new System.Net.Http.HttpClient();
}
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool disposing)
{
if (disposed)
return;
if (disposing)
{
client.Dispose();
// Free any other managed objects here.
}
disposed = true;
}
public async Task<string> AwaitableMethodAsync(Task arg1, Task arg)
{
string result = await client.GetStringAsync("http://www.microsoft.com");
return result;
}
}Você poderia fazer o seguinte para descartar um objeto de forma assíncrona em um contexto async/await (não recomendado):
var disposableObj = new DisposableFoo();
var arg1 = ComputeArg();
var arg2 = ComputeArg();
await disposableObj.AwaitableMethodAsync(arg1, arg2);
await Task.Run(() => disposableObj.Dispose());O uso incorreto de Task.Run() pode causar " thread pool starvation" - threads do pool de threads são um recurso compartilhado globalmente. Além disso, você poderia usar disposableObj em uma instrução using:
public static Task DoWorkFooAsync()
{
using (var service = new DisposableFoo())
{
var arg1 = ComputeArg();
var arg2 = ComputeArg();
return service.AwaitableMethodAsync(arg1, arg2);
}
}
public static async Task DoWorkFoo2Async()
{
using (var service = new DisposableFoo())
{
var arg1 = ComputeArg();
var arg2 = ComputeArg();
await service.AwaitableMethodAsync(arg1, arg2);
}
}Nesta implementação significa que você deve usar a segunda versão, onde o compilador gera a máquina de estado e uma continuação. O primeiro método é síncrono, o que significa que não há continuações. O objeto de serviço será Disposed() assim que retornar de AwaitableMethodAsync(). O objeto é descartado se o trabalho assíncrono for concluído, antes que o método retorne a tarefa (possivelmente ainda em execução). Há uma alta probabilidade de que resulte em um ObjectDisposedException em alguns casos.
O método assíncrono gera o código para que o Dispose gerada pelo compilador seja executada somente após a conclusão da tarefa retornada de AwaitableMethodAsync(). O serviço será descartado apenas quando terminar de fazer todo o seu trabalho. Não é facilmente visível em seu código-fonte e difícil de detectar em testes de unidade automatizados. Freqüentemente, escrevemos testes de unidade para métodos assíncronos que sempre retornam de forma síncrona, usando Task.FromResult (). Esses testes são bons e verificam se o atalho funciona corretamente.
Você também deve escrever testes que verificam o caminho lento, em que uma tarefa não foi concluída de forma síncrona. Não precisa ser mensuravelmente lento. Basta polvilhar uma instrução ‘await Task.Yield()’ em sua implementação simulada e você forçará o caminho lento.
Desde então, muito evoluiu - novas coisas como async/await foram adicionadas e os sistemas multi-threaded não são mais indispensáveis e mais importantes hoje em dia com a nuvem. Assim, há a necessidade de fazer o descarte também de forma assíncrona. O DisposeAsync() cumpre exatamente a mesma finalidade que o método Dispose() de IDisposable e deve seguir as mesmas regras de implementação:
- DisposeAsync/Dispose pode ser chamado várias vezes, chamadas subsequentes devem ser ignoradas
- DisposeAsync/Dispose não deve lançar exceção
- DisposeAsync/Dispose deve ser implementado quando contém outro objeto descartável ou/e recursos não gerenciados
A partir do C# 8.0, a linguagem oferece suporte a tipos descartáveis assíncronos que implementam a interface System.IAsyncDisposable. Você usa a instrução await using para trabalhar com um objeto descartável de forma assíncrona. Abaixo você pode encontrar um exemplo muito simples de uso assíncrono descartável em C# 8.0.
static async Task Main(string[] args)
{
await using (var disposableObject = new Foo())
{
Console.WriteLine("Hello World!");
}
Console.WriteLine("Done!");
}
class Foo : IAsyncDisposable
{
public async ValueTask DisposeAsync()
{
Console.WriteLine("Delaying!");
await Task.Delay(1000);
Console.WriteLine("Disposed!");
}
}É claro que há um atraso visível entre Delaying! e Disposed! desde que colocamos em um Task.Delay lá para mostrar o aspecto assíncrono do descarte. A proposta de valor é a capacidade de fazer o trabalho de limpeza assíncrona em nossos recursos (em vez de ter que bloquear no tradicional IDisposable), bem como a sintaxe concisa agradável de C# 8.0 - await using. Semelhante ao comando non await using, ele se expande para (internamente):
Foo disposableObject = null;
try
{
disposableObject = new Foo();
//...
}
finally
{
if (disposableObject != null)
await disposableObject.DisposeAsync();
}Vamos ver como você poderia implementar IAsyncDisposable em uma classe que já implementa IDisposable em sua própria biblioteca:
public class DisposableFoo : IAsyncDisposable, IDisposable
{
private bool disposed = false;
private Utf8JsonWriter _jsonWriter = new Utf8JsonWriter(new MemoryStream()); //IAsyncDisposable
private HttpClient client = new System.Net.Http.HttpClient(); //IDisposable
public void Dispose()
{
Dispose(disposing: true);
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool disposing)
{
if (disposed)
return;
if (disposing)
{
client?.Dispose();
(_jsonWriter as IDisposable)?.Dispose();
}
_jsonWriter = null;
client = null;
disposed = true;
}
public async ValueTask DisposeAsync()
{
await DisposeAsyncCore();
Dispose(disposing: false);
GC.SuppressFinalize(this);
}
protected virtual async ValueTask DisposeAsyncCore()
{
if (_jsonWriter != null)
{
await _jsonWriter.DisposeAsync().ConfigureAwait(false);
}
if (client is IAsyncDisposable disposable)
{
await disposable.DisposeAsync().ConfigureAwait(false);
}
else
{
client.Dispose();
}
_jsonWriter = null;
client = null;
}
public async Task<string> AwaitableMethodAsync(Task arg1, Task arg)
{
string result = await client.GetStringAsync("http://www.microsoft.com");
return result;
}
}Normalmente, você pode chamar o método dispose existente, mas isso nem sempre é possível - depende da estrutura/propósito de sua classe. O DisposeAsync retorna um ValueTask e não uma Tarefa por causa do desempenho. ValueTask é uma estrutura que não adiciona pressão ao GC alocando no heap. Isso pode ser importante quando muitos objetos são dispostos em um loop apertado. O try/catch só é necessário quando a classe não está selada ou/e você não tem certeza de que em nenhuma circunstância uma exceção é lançada. Além disso, não há suporte para CancelamentoToken para DisposeAsync porque não existe um cenário conhecido para cancelar o processo de limpeza e deixar o objeto em um estado inconsistente.
IAsyncDisposable não é herdado de IDisposable por intensão, permitindo que os desenvolvedores escolham entre implementar um ou ambos. Dependendo do uso / propósito de sua classe, é mais apropriado oferecer apenas DisposeAsync quando provavelmente for usado de forma assíncrona. Outro benefício de ter IAsyncDisposable é realizar uma operação de descarte com uso intensivo de recursos sem bloquear o thread principal de um aplicativo GUI por um longo tempo.
Se uma implementação de IAsyncDisposable for selada, o método DisposeAsyncCore() não será necessário e a limpeza assíncrona poderá ser realizada diretamente no método IAsyncDisposable.DisposeAsync().
Uma diferença principal no padrão de descarte assíncrono em comparação com o padrão de descarte é que a chamada de DisposeAsync() para o método de sobrecarga Dispose(bool) recebe false como argumento. Ao implementar o método IDisposable.Dispose (), entretanto, true é passado. Isso ajuda a garantir a equivalência funcional com o padrão de descarte síncrono e ainda garante que os caminhos do código do finalizador ainda sejam chamados. Em outras palavras, o método DisposeAsyncCore() descartará recursos gerenciados de forma assíncrona, portanto, você não deseja descartá-los de forma síncrona também. Portanto, chame Dispose(false) em vez de Dispose(true).
Trabalhar com matrizes torna-se mais expressivo com os novos tipos e operadores introduzidos para índices e intervalos. Anteriormente, quando tínhamos que endereçar itens com base em sua posição no final de uma matriz, o código resultante parecia um tanto bagunçado:
var numbers = Enumerable.Range(1, 10).ToArray();
var lastItem = numbers[numbers.Length - 1];Além disso, quando tivemos que dividir uma matriz com base na posição inicial e final, houve uma certa cerimônia envolvida, por exemplo, para calcular o comprimento, pré-inicializar uma matriz ou retornar para:
var (start, end) = (1, 7);
var length = end - start;
// Using LINQ
var subset1 = numbers.Skip(start).Take(length);
subset1.ToList().ForEach(w => Console.Write(w)); //234567
// Or using Array.Copy
var subset2 = new int[length];
Array.Copy(numbers, start, subset2, 0, length);
subset2.ToList().ForEach(w => Console.Write(w)); //234567O último método usando Array.Copy é aproximadamente o que o compilador emitirá nos bastidores ao usar os novos tipos Index e Range. Índices e intervalos fornecem uma sintaxe sucinta para acessar elementos ou intervalos únicos em uma sequência. Este suporte de idioma depende de dois novos tipos e dois novos operadores:
| Suporte | Descrição |
|---|---|
| System.Index | representa um índice em uma sequência |
| System.Range | representa um subfaixa de uma sequência. |
| operador ^ | especifica que um índice é relativo ao final da sequência |
| operador .. | especifica o início e o fim de um intervalo como seus operandos |
Considere a seguinte matriz, anotada com seu índice do início e do final:
var words = new string[]
{
// index from start index from end
"The", // 0 ^9
"quick", // 1 ^8
"brown", // 2 ^7
"fox", // 3 ^6
"jumped", // 4 ^5
"over", // 5 ^4
"the", // 6 ^3
"lazy", // 7 ^2
"dog" // 8 ^1
}; // 9 (or words.Length) ^0Vamos começar com as regras para índices. O índice 0 é o mesmo que words[0]. O índice ^0 é o mesmo que words[words.Length]. Observe que words[^0] lança uma exceção, assim como words[words.Length]. Para qualquer número n, o índice ^n é o mesmo que words.Length - n.
Um intervalo especifica o início e o fim de um intervalo. O início do intervalo é inclusivo, mas o final do intervalo é exclusivo, o que significa que o início está incluído no intervalo, mas o final não está incluído no intervalo. O intervalo [0..^0] representa todo o intervalo, assim como [0.. words.Length] representa todo o intervalo.
Você pode recuperar a última palavra com o índice ^1:
Console.WriteLine($"The last word is {words[^1]}"); //The last word is dogO código a seguir cria um subintervalo com as palavras "quick", "brown" e "fox".
Console.WriteLine(string.Join(" ", words[1..4])); //quick brown foxO código a seguir cria um subintervalo com "lazy" e "dog".
Console.WriteLine(string.Join(" ", words[^2..^0])); //lazy dogOs exemplos a seguir criam intervalos que são abertos para o início, o fim ou ambos:
//The quick brown fox jumped over the lazy dog
Console.WriteLine(string.Join(" ", words[..]));
Console.WriteLine(string.Join(" ", words[..4])); //The quick brown fox
Console.WriteLine(string.Join(" ", words[6..])); //the lazy dogVocê também pode declarar intervalos como variáveis, e ser usado dentro dos caracteres [e]:
Range range = 1..4;
Console.WriteLine(string.Join(" ", words[range])); //quick brown foxNão apenas as matrizes oferecem suporte a índices e intervalos. Você também pode usar índices e intervalos com string, Span ou ReadOnlySpan.
var array = new[] { 0, 1, 2, 3, 4, 5 };
var span = array.AsSpan(1, 4); // = { 1, 2, 3, 4 }
var subSpan = span[1..^1]; // = { 2, 3 }
var substring = "Thequickbrownfoxjumpedoverthelazydog"[1..4];
Console.WriteLine(substring); //"heq"Os tipos de dados em C# são divididos em duas categorias principais: Tipo de valor e Tipo de referência . Uma variável de tipo de valor não pode ser nula, mas podemos atribuir um valor nulo na variável de tipo de referência. Vamos verificar o que acontecerá quando atribuirmos null a um tipo de valor.

Esse é um tipo de erro comum que geralmente enfrentamos durante a codificação. Existem duas maneiras de resolver este problema.
- Nullable x = null;
- int ? x = null;
Os exemplos acima mostram duas maneiras de converter um tipo de valor não anulável em tipo de valor anulável. A partir disso, concluímos que: Um tipo é considerado anulável se pode receber um valor ou pode ser nulo, o que significa que o tipo não tem valor algum. Por padrão, todos os tipos de referência, como strings, são anuláveis, mas todos os tipos de valor, como Int32, não.
Existem dois membros de um tipo anulável.
- HasValue: é do tipo valor booleano. É definido como verdadeiro quando a variável contém um valor não nulo.
- Value: é do tipo booleano. Ele contém os dados armazenados no tipo anulável.
int? x = 5;
if (x.HasValue)
{
Console.WriteLine("contain not nullable value: " + x.Value.ToString());
}
else
{
Console.WriteLine("contain Null value.");
}Isso é a saber sobre tipos anuláveis em C#. Agora vamos entender um pouco sobrer o operador Null Coalescing em C#.
O operador de coalescência nulo foi introduzido no C# 7.0. Este operador retorna o valor do operando à esquerda se ele for "não nulo", caso contrário, o valor do operando à direita é avaliado. Se o operando à esquerda for "não nulo", ele nem mesmo avalia o operando da direita. Vamos considerar um exemplo do programa a seguir, que cobre os dois cenários.
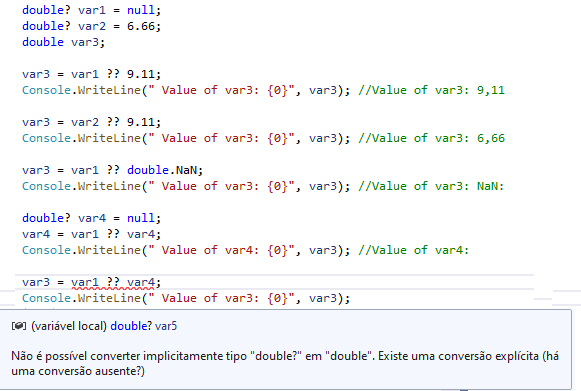
Note:
- operando var1 à esquerda é nulo, portanto, o valor de 9.11 é avaliado e atribuído à variável de saída.
- operando var2 à esquerda não é nulo, portanto, o valor de var2 é avaliado e atribuído à variável de saída.
- operando var1 à esquerda e operando var4 são nulos, o valor nulo é atribuído à variável anulável.
- operando var1 à esquerda e operando var4 são nulos, o valor não é atribuído à variável não anulável.
Os operadores de coalescência nula são associativos à direita. Ou seja, as expressões do formulário são avaliadas como
| Expressão | Avaliação |
|---|---|
| a ?? b ?? c | a ?? (b ?? c) |
| d ??= e ??= f | d ??= (e ??= f) |
Os operador de coalescência nulo operadores e podem ser úteis nos seguintes cenários:
- Fornecer uma expressão alternativa a ser avaliada, caso o resultado da expressão com operações condicionais nulas seja null:
private static double SumNumbers(List<double[]> setsOfNumbers, int indexOfSetToSum)
{
return setsOfNumbers?[indexOfSetToSum]?.Sum() ?? double.NaN;
}
var sum = SumNumbers(null, 0);
Console.WriteLine(sum); // output: NaN- Fornecer um valor de um tipo de valor subjacente, caso um valor de tipo anulável seja null :
int? a = null;
int b = a ?? -1;
Console.WriteLine(b); // output: -1- Usar uma expressão throw como o operando à direita do ?? operador para tornar o código de verificação de argumento mais conciso.
public string Name
{
get => name;
set => name = value ?? throw new ArgumentNullException(nameof(value), "Name cannot be null");
}No C# 7.3 e anteriores, o tipo de operando esquerdo do operador ?? deve ser um tipo de referência ou um tipo de valor anulável. A partir do C# 8.0, esse requisito foi substituído pelo seguinte:
O tipo de operando esquerdo dos operadores ?? e ?? = tem que ser do tipo de valor anulável

Isso amplia a utilização do operador que pode ser uma variável, uma propriedade ou um elemento indexador. Você pode usar o operador ??= para atribuir o valor de seu operando à direita a seu operando à esquerda somente se o operando à esquerda for avaliado como null.
List<int> numbers = null;
int? i = null;
numbers ??= new List<int>();
numbers.Add(i ??= 17);
Console.WriteLine(i); // output: 17
numbers.Add(i ??= 20);
Console.WriteLine(string.Join(" ", numbers)); // output: 17 17Em particular, a partir do C# 8,0, você pode usar os operadores de coalescência nulo com parâmetros de tipo irrestrito, pois o parâmetro de tipo irrestrito T existe, é um tipo anulável e não é um tipo de referência. Um parâmetro de tipo genérico irrestrito não pode usar os operadores == e != para comparar duas instâncias do parâmetro de tipo, no caso de o tipo não ser compatível com esses operadores. Essas verificações são necessárias para genéricos, mas não para modelos porque os genéricos podem ser especializados em runtime com qualquer classe que atenda às restrições, quando for tarde demais para verificar o uso de membros inválidos.
private static void Display<T>(T a, T backup)
{
Console.WriteLine(a ?? backup);
}A partir do C# 8,0, você pode usar o ??= operador para comparar e atribuir valor as variáveis:
List<int> numbers = null;
int? variable = null;
int expression = 5;
if (variable is null)
{
variable = expression;
}
(numbers = numbers ?? new List<int>()).Add(5);
numbers.Add((variable = variable ?? 0).Value);pelo código a seguir:
variable ??= expression;
(numbers ??= new List<int>()).Add(5);
numbers.Add(variable ??= 0);Pontos importantes :
- O operando à esquerda do operador ??= deve ser uma variável, uma propriedade ou um elemento indexador.
- É associativo à direita.
- Você não pode sobrecarregar o operador ??=.
- Você tem permissão para usar o operador ??= com tipos de referência e tipos de valor.
As definições de tipos não gerenciados e construídos citados pelas especificações de linguagem:
- Tipo construído: se for genérico e o parâmetro de tipo já estiver definido. Por exemplo, List é um tipo construído, enquanto List não é.
-
Tipo não gerenciado: especificação C# 6 não é um tipo de referência ou tipo construído e não contém tipo de referência ou campos de tipo construído em qualquer nível de aninhamento. É quando pode ser usado em um contexto não seguro. Isso é verdadeiro para muitos tipos básicos integrados. A documentação oficial inclui a lista destes tipos:
- sbyte, byte, short, ushort, int, uint, long, ulong, char, float, double, decimal ou bool
- Qualquer tipo de Enumeração
- Qualquer tipo de ponteiro (int*, char*, int*[], void*, etc). O tipo especificado antes do * em um tipo de ponteiro é chamado de tipo referent. Somente um tipo não gerenciado pode ser um tipo referent. Os tipos de ponteiro não são herdados de object e não há nenhuma conversão entre tipos de ponteiro e object.
- Qualquer tipo de struct definido pelo usuário que contém campos de tipos não gerenciados somente e, em C# 7,3 e anterior, não é um tipo construído (um tipo que inclui pelo menos um argumento de tipo)
A partir do C# 7,3, você pode usar a restrição unmanaged para especificar que um parâmetro de tipo é um tipo não gerenciado, não-ponteiro e não anulável. Mas no C# 7,3, um tipo construído (um tipo que inclui pelo menos um argumento de tipo) não pode ser um tipo não gerenciado. Nesta versão, os usuários podem declarar structs e obter o endereço dele (em um contexto não seguro), desde que não seja considerado um tipo "gerenciado".
O compilador atualmente relata structs genéricos como tipos "gerenciados", embora não sejam rastreados por GC. No entanto, não há nada no tempo de execução que impeça um usuário de obter o endereço de uma estrutura genérica e, em certos cenários, pode ser desejável permitir isso. Um exemplo é o tipo System.Runtime.Intrinsics.Vector128 , que não contém objetos rastreados por GC. O tipo é projetado para ser usado em cenários de alto desempenho e geralmente inseguros, mas existem certas operações (como stackalloc, pinning, etc) que não podiam ser feitas em C#.
A partir do C# 8,0, foi removida a restrição de que um tipo não gerenciado não pode ser um tipo construído. Em vez disso, os tipos construídos não seriam gerenciados se atendessem aos requisitos de tipos de estrutura gerais definidos pelo usuário. Por exemplo, um tipo struct construído que contém campos de tipos não gerenciados também é não gerenciado, como mostra o exemplo a seguir:
public struct Coords<T>
{
public T X;
public T Y;
}
class Program
{
static void Main(string[] args)
{
DisplaySize<Coords<int>>();
DisplaySize<Coords<double>>();
Console.WriteLine("Hello World!");
}
private unsafe static void DisplaySize<T>() where T : unmanaged
{
Console.WriteLine($"{typeof(T)} is unmanaged and its size is {sizeof(T)} bytes");
}
}No exemplo, um tipo struct genérica pode ser a fonte de tipos construídos não gerenciados e gerenciados. O exemplo anterior define uma struct genérica Coords e apresenta os exemplos de tipos construídos não gerenciados. O exemplo de um tipo gerenciado seria Coords, porque tem os campos do tipo gerenciados object. Se você quiser que todos os tipos construídos sejam tipos não gerenciados, use a unmanaged restrição na definição de uma estrutura genérica:
public struct Coords<T> where T : unmanaged
{
public T X;
public T Y;
}Como para qualquer tipo não gerenciado, agora você pode criar um ponteiro para uma variável desse tipo:
unsafe
{
int length = 3;
Coords<int>* numbers = stackalloc Coords<int>[length];
for (var i = 0; i < length; i++)
{
numbers[i] = new Coords<int> { X = 0, Y = i };
}
}Ou alocar um bloco de memória na pilha para instâncias desse tipo:
Span<Coords<int>> coordinates = stackalloc[]
{
new Coords<int> { X = 0, Y = 0 },
new Coords<int> { X = 0, Y = 3 },
new Coords<int> { X = 4, Y = 0 }
};O compilador pode precisar fazer uma validação adicional para validar se uma estrutura genérica definida pelo usuário está "ok" para usar.

Uma expressão stackalloc aloca um bloco de memória na pilha, que é criado durante a execução do método e é descartado automaticamente quando esse método é retornado. Não é possível liberar explicitamente a memória alocada com stackalloc. Um bloco de memória alocado de pilha não está sujeito à coleta de lixo e não precisa ser fixado com uma instrução fixed.
A principal razão para usar stackalloc é o desempenho (para cálculos ou interoperabilidade). Usando stackalloc em vez de um array de heap alocado nativo(como malloc ou o equivalente .Net):
- Cria menos pressão GC (roda menos), você não precisa fixar os arrays
- Automaticamente liberado na saída do método. As matrizes alocadas no heap são desalocadas apenas quando o GC é executado
- Ganha velocidade pois a chance de acertos do cache na CPU devido à localidade dos dados é maior
- Habilita automaticamente os recursos de detecção de estouro de buffer no CLR (Common Language Runtime). Se for detectada um estouro de buffer, o processo será encerrado assim que possível para minimizar a chance de o código mal-intencionado ser executado.
Você pode atribuir o resultado de uma expressão stackalloc a uma variável de um dos seguintes tipos:
- Por System.Span ou System.ReadOnlySpan
- Por um tipo ponteiro,
A partir do C# 7,2, é a forma recomendável para trabalhar com memória alocada na pilha, pois não precisa usar um contexto unsafe como mostra o exemplo a seguir:
//Antes do C# 7,2
unsafe
{
int* Array1 = stackalloc int[3] { 5, 6, 7 };
}
int length = 3;
Span<int> numbers7_2 = stackalloc int[length];
for (var i = 0; i < length; i++)
{
numbers7_2[i] = i;
}Ao trabalhar com esses tipos, você pode usar uma expressão stackalloc em condicional ou expressões de atribuição, como mostra o seguinte exemplo:
length = 1000;
const int MaxStackLimit = 1024;
Span<byte> buffer = length <= MaxStackLimit ? stackalloc byte[length] : new byte[length];A partir do C# 8.0, se o resultado de uma expressão stackalloc for do tipo System.Span ou System.ReadOnlySpan , você poderá usar a expressão stackalloc em outras expressões:
Span<int> numbers = stackalloc[] { 1, 2, 3, 4, 5, 6 };
var ind = numbers.IndexOfAny(stackalloc[] { 2, 4, 6, 8 });
Console.WriteLine(ind); // output: 1No exemplo acima, usamos stackalloc como coleção de dados int e passamos stackalloc como expressão para o método IndexOfAny, que retornará o resultado da posição encontrada.
Por um tipo ponteiro
Precisa usar um contexto unsafe ao trabalhar com tipos de ponteiro. Nestes casos, você pode usar uma expressão stackalloc somente em uma declaração de variável local para inicializar a variável.
unsafe
{
int lengthpont = 3;
int* numberspont = stackalloc int[lengthpont];
for (var i = 0; i < lengthpont; i++)
{
numberspont[i] = i;
}
}Como a quantidade de memória disponível na pilha é limitada, para evitar que um StackOverflowException seja lançado:
- Limite a quantidade de memória que você aloca com stackallo. A quantidade de memória depende do ambiente no qual o código é executado, seja conservador quando você define o valor de limite real. No exemplo acima, foi limitado com a constante MaxStackLimit.
- Evite usar stackalloc loops internos. Aloque o bloco de memória fora de um loop e reutilize-o dentro do loop.
O conteúdo da memória recém-alocada é indefinido. Você deve inicializá-lo antes do uso. Por exemplo, você pode usar o Span.Clear método que define todos os itens com o valor padrão do tipo T .
A partir do C# 7,3, você pode usar a sintaxe do inicializador de matriz para definir o conteúdo da memória alocada recentemente. O seguinte exemplo demonstra várias maneiras de fazer isso:
Span<int> first = stackalloc int[3] { 1, 2, 3 };
Span<int> second = stackalloc int[] { 1, 2, 3 };
ReadOnlySpan<int> third = stackalloc[] { 1, 2, 3 };Uma string que começa com $, era a forma de identificar a string como uma string interpolada, esta string contém a expressão de interpolação e outras que são substituídas pelo resultado real. Veja o exemplo abaixo:
string szName = "ABC";
int iCount = 15;
//Olá, ABC! Você tem 15 maçãs
Console.WriteLine($"Olá, {szName}! Você tem {iCount} maçãs");
Console.WriteLine($@"Olá, {szName}! Você tem {iCount} maçãs");
Console.WriteLine(@$"Olá, {szName}! Você tem {iCount} maçãs");Agora em C# 8,