Scoring Model Development - shmercer/writeAlizer GitHub Wiki
Scoring Model Development
The general process used to generate all scoring models is presented below.
Predictive Algorithms and R Packages Used
The caret and caretEnsemble packages were used as wrappers for the following predictive algorithms:
- Random forest regression (package randomForest)
- Cubist regression (package Cubist)
- Support vector machines with a radial kernel (package kernlab)
- Bagged multivariate adaptive regression splines (package earth)
- Stochastic gradient boosted trees (package gbm)
- Partial least squares regression (package pls)
- Elasticnet regression (package elasticnet)
These algorithms are described in detail in the following references (among others):
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction (2nd ed.). Springer. https://doi.org/10.1007/b94608
- Kuhn, M., & Johnson, K. (2013). Applied predictive modeling. Springer. https://doi.org/10.1007/978-1-4614-6849-3
Steps
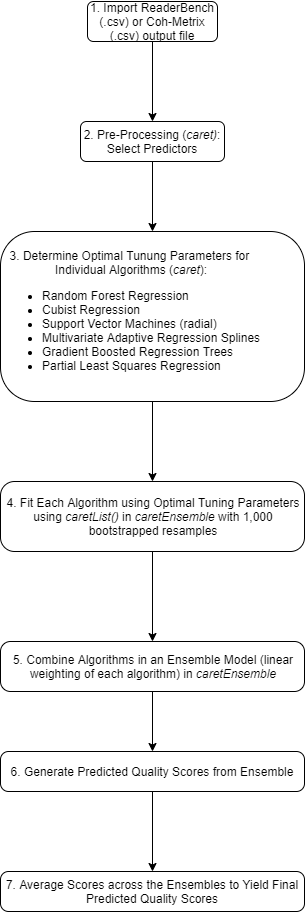
The following flowchart provides an overview of the scoring model development workflow, with more details on some steps provided below.
{kind=link}
1. Import Data
Depending on the specific scoring model, ReaderBench, Coh-Metrix, and/or GAMET output files were imported into R using functions similar to the import_XXXX.R functions in writeAlizer (see https://github.com/shmercer/writeAlizer/blob/master/R/file_utilities.R)
2. Pre-Process Data
Automated data pre-processing were done using the preProcess() function in caret:
- Select Predictors
- Predictors from the output file with near zero variance (defined based on defaults in the nearZeroVar() function) were removed, and the remaining predictors were standardized.
- Highly correlated | r > .90 | predictors were identified, with the predictor that had the highest mean correlation with all of the other predictors removed.
- The reduced set of predictors was submitted to the next step of the analysis.
3. Determine Optimal Tuning Parameters
The following tuning hyperparameters were optimized based on resampling (repeated 10 fold) in caret. Each algorithm was tuned separately. Full descriptions of the tuning parameters are available in each package's documentation.
- Random forest regression: mtry
- Cubist regression: committees, neighbors
- Support vector machines: sigma, C
- Bagged multivariate adaptive regression splines: nprune, degree
- Stochastic gradient boosted trees: n.trees, interaction.depth, shrinkage, n.minobsinnode
- Partial least squares regression: ncomp
- Elastic net regression: fraction, lambda
4. Final/Optimal Model for each Algorithm
A model for each algorithm was fit with the hyperparameters set to the optimal values found in Step 3, with bootstrapped (1000 samples) resampling-based cross-validation so that an ensemble model (weighting each algorithm) could be built based on the resamples. This step was done with the caretList() function of the caretEnsemble package. This process is illustrated in more detail in the caretEnsemble vignette: https://cran.r-project.org/web/packages/caretEnsemble/vignettes/caretEnsemble-intro.html
5. Estimate an Ensemble Model to Combine the Algorithms
The caretEnsemble() function was used to determine the optimal linear weighting of the algorithms that minimized RMSE (i.e., discrepancy between actual writing quality scores and predicted quality scores) in the resamples from Step 4. Algorithms with near zero or negative weights were removed from the ensemble models. The varImp() function of caretEnsemble was used to generate estimates of relative predictor importance for the overall ensemble model and for each individual algorithm.
6. Generate Predicted Quality Scores from each Ensemble
The predict() function of caretEnsemble was used to generate/store predicted quality scores for the ensemble models.
7. Average Scores to get Final Predicted Quality Scores
The predicted scores from each ensemble were averaged to produce the final predictions.