Overfitting - sagr4019/ResearchProject GitHub Wiki
What is overfitting?
We call it overfitting if the model works great with the training data, but poor with test data. The algorithm is probably bad at generalization, because noise and other fluctuations in the training data has been learned as concepts and these concepts are good for the training data, but on the other hand not suitable for test data, because the features are missing.
Simple example
If we put training data containing images of white cats into our system to make the model learning based on those images, the model will probably fail to detect black cats in the test data due to the limitation on white cats.
How to avoid overfitting?
There exist methods to protect the system from overfitting. This wiki provides an overview without any claim of completeness.
Cross-Validation
Offers information how well the generalization on independent data works (effectiveness of the model). Cross-Validation methods:
-
Holdout Method: A part from the training data is removed and used later to get the error estimation → maybe underfitting is given, because the training data has been reduced
-
K-Fold Cross Validation: data is divided into k subsets (sections/folds), repeats the holdout method k times. Each time a subset is used as test data or validation data, the other k-1 subsets are used as training data, error estimation is computed over all k trials, k=5 or k=10 is preferred, but not fixed.
-
Stratified K-Fold Cross Validation: Divides the data such that the distribution of classes are held constant for each k folds, reduces the variance of the performance estimate
-
Leave-One-Out Cross Validation: K-Fold cross validation with k equal to n (where n = number of elements)
Early Stopping
Training is stopped before overfitting starts (once the performance has stopped improving on a validation set)
Regularization
Regularization is a (mathematical) technique to avoid overfitting within our model. It adds a penalty to the model to handle with high complexity and increases the generalization of the model.
Regularization Methods:
The mean-squared error cost function is used along the examples:
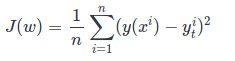
-
Ridge Regression (also known as L2 regularization): As the regularization (bordered red) the beta coefficients are squared and summed.
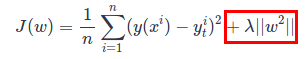
-
Lasso Regression (also known as L1 regularization):As the regularization (bordered red) the beta coefficients are summed (absolute value).
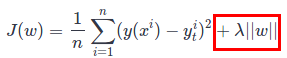
Both L1 and L2 are using Lambda as hyper-parameter (in short: chooses the regularization strength). Difference between L1 and L2 regularization: L1 penalizes smaller weights equally as larger weights. L2 penalizes larger weights a lot more.
-
Elastic Net Regression (Ridge + Lasso): Includes squared and absolute values in the cost function.
-
Dropout Neurons selected randomly are ignored during training (dropped-out). Other neurons need to step in and handle the missing but required neurons to make predictions. At the end our network has the ability to better generalize and less overfitting. So dropout removed width from the network.
-
DropConnect Instead of randomly ignore neurons during training (dropout), DropConnect randomly ignores (set to zero) subsets of weights within the network.
-
Stochastic Depth Randomly skips entire layers during training. So stochastic depth removes depth from the network.
-
Data augmentation Increase the number of training data by changing the data (e. g. rotate/resize images) and adding it to the training data.
-
Ensemble Methods Train multiple models for same task, merges them to get a better predictive performance