ALEXNET - rugbyprof/5443-Data-Mining GitHub Wiki
Imagenet
ImageNet project was started in 2007. This project downloaded billion images from internet and labeled by human using Amazon’s Mechanical Turk crowd-sourcing tool. This dataset has over 15 million labeled high-resolution images belonging to roughly 22,000 categories. ImageNet is an ongoing research effort to provide researchers around the world an easily accessible image database.
Top-1 error
This makes the top one guess about the image label.
Top-5 error
This makes the top five guesses about the image label.
Normalization
As the dataset contains variable resolution images but system requires a constant input dimensionality. So normalization is done by down-sampling the images to a fixed resolution of 256 × 256.
Alexnet
AlexNet is the first deep architecture which was introduced by one of the pioneers in deep learning – Geoffrey Hinton and his colleagues. This is the name of a convolutional neural network, which was originally written in CUDA to run with GPU support. Alexnet won the difficult ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012 by a large margin which was a significant breakthrough.
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
Stride
Stride is the number of pixels by which we slide our filter matrix over the input matrix. When the stride is 1 then we move the filters one pixel at a time. When the stride is 2, then the filters jump 2 pixels at a time as we slide them around. Having a larger stride will produce smaller feature maps.
Padding
The padding defines how the border of a sample is handled. A padded convolution will keep the output dimensions equal to the input, whereas unpadded convolutions will crop away some of the borders if the kernel is larger than 1. If the input matrix is padded with zeros around the border, we can apply the filter to bordering elements of our input image matrix which allows us to control the size of the feature maps.
Output Size
The size of output by running a filter over the input image is calculated by, output size = (N – F)/S + 1, where N=size of original image, F= size of filter, S=stride.
Example
Given, image Size: 227 x 227 x 3 and 96 filters of size 11x11 with stride of 4 and padding 0. output size = (227-11)/4 + 1 = 55 is the size of the outcome.
Difference between a convolution layer and a fully-connected layer
Convolutional layers just "slide" the same filters across the input, so it can basically deal with input of an arbitrary spatial size. While Fully connected layers can only deal with input of a fixed size, because it requires a certain amount of parameters to "fully connect" the input and output.
Architecture Explanation
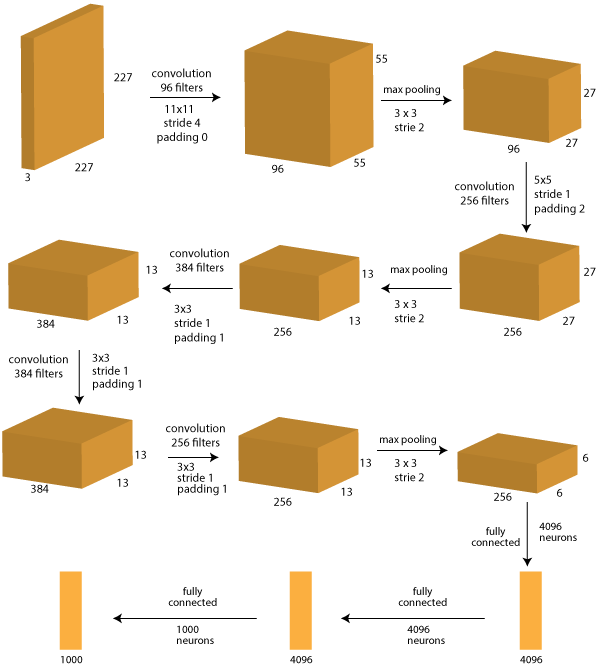
GPU
In 1980s, CPU was used for training a neural network. To speed up the training GPU's are used in Alexnet. A single GTX 580 GPU has only 3GB of memory, which limits the maximum size of the networks.We spread the net across two GPUs. Current GPUs are particularly well-suited because the work can be done parallely.
Local Response Normalization
This encourage different convolution kernels to learn different features. A kernel is a “matrix” applied on a square area of pixels. Each entry in the matrix multiplies the pixel under it, then the neuron sums up everything, applies the offset, and passes it through the non-linearity. When two kernels have very similar matrices, it will detect similar features and this reduces the expressiveness of the network.
Equation: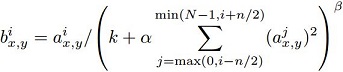 This first imposes an order to the kernels and looks at n adjacent kernels.
For each kernel, the equation inhibits an entry in the matrix if the adjacent kernels have a high value in that same entry. This scheme aids generalization.
This first imposes an order to the kernels and looks at n adjacent kernels.
For each kernel, the equation inhibits an entry in the matrix if the adjacent kernels have a high value in that same entry. This scheme aids generalization.
Overlapping Pooling
Overlap pooling downsize the image by gathering together a small window of pixels. Traditionally, a given pixel was used only in one of the pooling neuron. This paper proposed to overlap the pooling windows so that the same pixel can be used by two different pooling neurons.
Overfitting
Alexnet architecture has 60 million parameters which turns out to be insufficient to learn so many parameters which causes danger of overfitting.
Reducing Overfitting
To reduce overfitting we use two ways
Data Augmentation
A good way to make the most out of a dataset is often to augment it by distorting each sample in a way that ensures the label stays valid. In this method they artificially enlarged the dataset using label-preserving transformations.
Applying translations and horizontal reflections
First form is by applying translations and horizontal reflections, this is done by extracting random 224 × 224 patches from the 256×256 images and training our network on these extracted patches and increasing the number of training images by a factor of 2048 in the process.
Altering the intensities of the RGB channels
The second form of data augmentation consists of altering the intensities of the RGB channels in training images. They performed PCA on the set of RGB pixel values throughout the ImageNet training set.
Dropout
Dropout consists of setting to zero the output of each hidden neuron with probability 0.5. The neurons which are “dropped out” in this way do not contribute to the forward pass and do not participate in back propagation. Dropout is used in the first two fully-connected layers. Without dropout, our network exhibits substantial overfitting.
https://medium.com/academic-origami/imagenet-classification-with-deep-convolutional-neural-networks-da7cea972cb7
Result Classification
