MongoDB i noSQL - rlip/java GitHub Wiki
- Find
- Create
- Update, Replace
- Delete
- Typy
- Typy numeryczne
- Agregacje
- Indexy
- Wykonywanie js
- Tranzakcje
- Schema Validation
Mongo
wady: problemy z tranzakcjami + shardning ograniczenie joiny duże powtarzanie danych duże zapotrzebowanie na ram (podbiera ram, dopóki jest dostępne), na poziome infrastruktury trzeba ograniczyć maksymalny rozmiar 16 MB
https://docs.mongodb.com/manual/reference/operator/query-comparison/
mongo // włączmay
show dbs // lista baz
use snacktime // przełączenie na baz snacktime
show collections // lista kolekcji
db.companies.drop() // usuwa baze companies
db.stats() // statystki
mongosh --port 27017 // połaczenie z konsola
sudo systemctl stop mongodb// w ubuntu
mongod --help //można m.in. zmienić path do danych i loga, za pomocą eval można wykonać jakis js lub coś zwrócić
Impoer i export
mongorestore --uri="mongodb://localhost:27017/collection" collectionExportDirecotry
Find
db.passengers.find() // znajduje wszystko (zwraca kursor)
db.passengers.find().pretty() // j.w. z formatowaniem
db.passengers.find().count() // liczba
db.passengers.find().toArray() // wszystko jako array
db.passengers.find().forEach(data => {printjson(data.age)})
db.passengers.findOne({"name" : "Scott Tolib"}).hobbies //pierwszy losowy znaleziony, spełniający warunek
db.flightData.find({"status.description": "on-time"})
//sortowanie 1 - asc, -1 - desc
db.movies.find().sort({"rating.average": -1})
db.movies.find().sort({"rating.average": 1, runtime: -1}) //więcej kolumn
//skip & limit
najpierw sortuje, potem skip, potem limit, niezależnie od kolejności napisania
db.movies.find().sort({"rating.average": 1, runtime: -1}).skip(100).limit(10)
// pola
db.passengers.find({},{name: 1}).pretty() //zwraca id i name
db.passengers.find({},{name: 1, _id: 0}).pretty() //zwraca tylko name
//szuka z genres: Drama, a wyświetla puste lub genre: Horror
db.movies.find({genres: "Drama"}, {genres: {$elemMatch: {$eq: "Horror}}})
//slice wyswietla tylko 2 elementy z array, można też dać [1, 2], wtedy są 2 pomijając 1
db.movies.find({genres: "Drama"}, {genres: {$slice: 2}, name: 1}})
db.FavouriteSnack.find({"snack": "cupcake"}, {preptime: {$nin:["10m"]}})
db.FavouriteSnack.find({preptime: {$nin:["10m"]}}) // not in preptime 10min
db.flightData.find({distance: {$gt: 100}})
db.flightData.findOne({distance: {$gt: 100}})
// logiczne
db.movies.find({$or:[{"rating.average": {$lt: 5 }}, {"rating.average": {$gt: 9.3 }}]}).count()
//and można analogicznie jak wyżej lub tak, tylko trzeba uważać żeby
// nie dawać niżej tej sammej nazwy bo się pierwsza nadpisze
db.movies.find({"rating.average": {$gt: 9}, genres: "Drama"}).count()
db.movies.find({"runtime": {$not: {$eq: 60 }}}).count() //można też $neq
//exists & type & regex
db.users.find({age: {$exists: true}}) //mające pole age (false nie ma)
db.users.find({age: {$exists: true, $ne: null}}) //bez nuli
db.users.find({age: {$type: "number"}})
db.movies.find({summary: {$regex: /musical/}}).count() // index wydajniejszy, wydajniej jest użyć znaku początku frazy ^
db.foo.find({$expr: {$gt: [{$sum: ["$field1", "$field2"]}, 50)}})
db.products2.find({$expr: {$gt: [{$multiply: ["$price", "$qty"]}, 500] }}) // produkty których price*qty > 500
db.sales.find({$expr: {$gt:["$voulume", "$target"]}}) // related query, pole voulume > target
// where (mało wydajna)
db.foo.find({$where: function(){return this.field1 + this.field2 > 50}})
//pokaż takie, które mają (if volume jest większe od 190 to odejmniej
// od volume 20, else volume) większe od target
db.sales.find({$expr: {$gt: [{$cond: {if: {$gte: ["volume", 190]}, then: {$subtract: ["volume", 20]}, else: "$voulume"}}, "target"]}})
//size & all
db.users.find({"hobbies": {$size: 2}}) //co ma 2 hobbies
db.movies.find({genres: ["Drama", "Horror"]}) //dokładnie co ma tylko "Drama", "Horror" w tej kolejności
db.movies.find({genres: {$all: ["Drama", "Horror"]}}) //co ma w sobie, bez względu na order
//elemMatch
//to znajdzie userów którzy mają min. 1 hobby.title sports, i w min. jednym
//hobby frequency > 3, ale nie koniecznie tym samym hobby
// and trzeba użyć, gdy mamy te same parametry, dla różnych nie trzeba używać and
db.users.find({$and:[{"hobbies.title": "Sports"}, {"hobbies.frequency": {$gt: 3 }}]}).pretty()
//tak znajdzie osoby, które mają hobby z tytle Sports i frequency > 3
db.users.find({hobbies: {$elemMatch: {title: "Sports", frequency: {$gte: 3}}}}).pretty()
db.products.find({}, {warehouses : {$elemMatch: {qty : {$lt : 10}}}})
Create
db.FavouriteSnack.insertOne({snack: "popcorn"}) //dodaje jeden
db.FavouriteSnack.insertMany([{snack: "popcorn"}, {snack: "chocolate"}])
db.FavouriteSnack.insert() // tak też można ale nie polecane
//domyśnie jest oredered insert - dodaje tak długo, przerwie dodawanie jak będzie błąd. Żeby pominiął błędy trzeba wyłączyć ordered:
db.FavouriteSnack.insertMany([{snack: "popcorn"}, {snack: "chocolate"}], {ordered: false})
// w:1 - domyślne, w: 0 - bez czekania na potwierdzenie i id
// j: false - domyślne, j: true - z dziennikiem - zwiększa bezpieczeństwo
// wtimeout: 200 - po ilu m.sek. ma odrzucić zapis jeśli się od tego czasu nie zapisze
db.FavouriteSnack.insertOne({snack: "popcorn"}, {writeConcern: {w: 1, j: false, wtimeout:200}})
Update, Replace, Unset, Rename, dodanie do tablicy
db.FavouriteSnack.updateOne({snack: "chocolate"},{$set: {snack: "cupcake"}}) // podnieni wymienione, resztę zostawi
db.FavouriteSnack.updateMany({preptime: "45m"},{$set: {preptime: "50m"}}) // jw
db.flightData.update({_id: ObjectId("6040dac6cb6f9b25d3d1c66e")}, {delayed: false}); //to zamienia całość!
db.flightData.replace({_id: ObjectId("6040dac6cb6f9b25d3d1c66e")}, {delayed: false}) // też zamienia
db.flightData.replaceFirst({_id: ObjectId("6040dac6cb6f9b25d3d1c66e")}, {delayed: false}) // zamienia pierwszy
//inclementuje age o 2 (minus deklementuje), do tego ustawia isSporty
db.users.updateOne({_id: ObjectId("604225a2f1fe58168f5ff260")}, {$inc: {age: 2}, $set: {isSporty: true}}})
//min zmienia wartość, jeśli nowa wartość będzie mniejsza niż obecna, max odwrtonie
db.users.updateOne({_id: ObjectId("604225a2f1fe58168f5ff260")}, {$min: {age: 28}})
//mul mnoży
db.users.updateOne({_id: ObjectId("604225a2f1fe58168f5ff260")}, {$mul: {age: 2}})
//usuwa pole isSporty - wartość w polu dowolna
db.users.updateMany({}, {$unset:{ isSporty: ""} })
//zmiana nazwę (nie wartość) pola
db.users.updateMany({}, {$rename:{ age: "totalAge"} })
//insert (jeśli nie istniueje) or update - trzeba ustawić upsert:true
db.users.updateOne({name: "Maria"}, {$set: {age: "29", hobbies: [{title: "Good food"}]} }, {upsert:true})
//do pozycji które mają element w którym zarówno hobbies.title = "Sports" i hobbies.frequency >= 3,
//dodajmey nowe pole hobbies.highFrequency = true, pozostawiając poprzednie
db.users.updateMany({hobbies: {$elemMatch: {title: "Sports", frequency: {$gte: 3}}}}, {$set: {"hobbies.$.highFrequency": true}})
//zminiejsza frequency dla każdego elementu w array dla totalAge >= 30
db.users.updateMany({totalAge: {$gte: 30}}, {$inc: {"hobbies.$[].frequency": -1}})
//dodanie arrayFilter, żeby dodać warunek, który będzie dodawać goodFrequency do
//pozycji w tablicy, które go spełniają
db.users.updateMany({"hobbies.frequency": {$gt: 2}}, {$set: {"hobbies.$[el].goodFrequency": true}}, {arrayFilters: [{"el.frequency": {$gt:2}}]})
//do tabicy obiektów addresses dodaje pole country=PL, obiekt ten musi spełniać spełnia warunek że jego city = Warszawa,
db.users.update({}, {$set: {"addresses.$[elm].country": "PL"}}, {arrayFilters: [{"elm.city": "Warszawa"}]})
//dodanie do tablicy nowych elementów, dodatkowo je stortuje po frequency malejąco - push
//można zamist $push dać $addToSet, to nie pozwoli na duplikaty, wielkość liter ma znaczenie, $each - dodaje więcej wartości na raz
db.users.updateMany({name: "Anna"}, {$push: {hobbies: {$each: [{title: "Good Wine2", frequency: 5}, {title: "Hiking3", frequency:4}], $sort: {frequency: -1}}}})
//usuwa określony element z array - pull - podaje warunek, może użyć pullAll - wtedy podaje się w tablicy Wartości do usunięcia
db.users.updateMany({name: "Anna"}, {$pull: {hobbies: {title: "Hiking3"}}})
//usuwa pierwszy element z array (z 1 - uwuwa pierwszy) - pop
db.users.updateMany({name: "Anna"}, {$pop: {hobbies: -1}})
Delete
db.FavouriteSnack.deleteOne({snack: "popcorn"}) //usuwa 1 losowo spełniający warunek
db.FavouriteSnack.deleteMany({})
db.users.drop() // usuwa kolekcję i wszystkie dane
db.dropDatabase()
findAndModify
znajduje i modyfikuje - dzieki temu nie zieni się wartość pamiędzy odczytem a zapisem
db.counters.findAndModify({query: {counterName: "userIdCounter"}, update: {$inc: {"value": 1}}, new: true})
//większa pole value o 1, których counterName = userIdCounter. Flaga new oznacza czy ma zostać zwrócona poprzenia wartość, czy nowa
//import //drop - kasuje, bez tego dodaje mongoimport tv-shows.json -d movieData -c movies --jsonArray --drop
Typy
string(utf-8) timestamp, object array null (inne)
db.numbers.insertOne({a: NumberInt(1)})
typeof db.numbers.findOne().a
Typy numeryczne
db.persons.stats()
do.persons.insertOne({age: NumberInt("29")}) //int32, zależy od języka, w js domyślnie double
//NumberLong - 64bit int
//NumberDecimal - 128bit decimal - bez błędów zaokrąglania
Agregacje
$match = WHERE
$group = GROUP BY
$match = HAVING
$project = SELECT
$addFields = porzuca jakieś pola
$sort = ORDER BY np. {$sort : {liczbFilmow : -1}}
$limit = LIMIT
$sum = SUM
$count = COUNT
$unwind - rozbijanie tablic
$facet - podagregacje
$sample - próbka losowych danych
$lookup - left outer join
{ $unwind: "hobbies" }, // wypłaszcza tablicę - daje każdy element - kopiując resztę
// $push - dodaje elementy do array, addToSet - dodaje tylko unikalne
{ $group: { _id: { age: "$age" }, allHobbies: { $push: "$hobbies" } } }
//średni czas dla każdego z języków
db.movies.aggregate(
[
{$group :
{
_id : "$original_language",
średniaDługośćFilmu : {$avg : "$runtime"}
//liczbaFilmów: {$count: 1} //albo $sum: 1 w starszej wersji
}
}
])
// $slice - wycina z array,
{ $project: { _id: 0, examScore: { $slice: ["$examScores", 2, 1] } } }
//filter - ogranicza
scores: { $filter: { input: '$examScores', as: 'sc', cond: { $gt: ["$$sc.score", 60] } } }
// bucket - grupuje w podanych zakresach
// jest też sort, skip i limit
// $out - mozna zapisac od razu w nowej kolekcji
//filtrowanie, grupowanie i sortowanie
db.persons.aggregate([
{ $match: { gender: 'female' } }, //filtruje - przepuszcz tylko takie
{ $group: { _id: { state: "$location.state" }, totalPersons: { $sum: 1 } } },
{ $sort: { totalPersons: -1 } }
]).pretty();
//wyświetla tytuł i pierwszy element z tablicy genres
db.movies.aggregate([
{ $match: {directed_by: "George Lucas"}},
{ $project: {title: "$title", main : {$arrayElemAt : ["$genres", 0]}}}
]
, {explain: true} // z tą linijką plan zapytania
)
//sredni zysk per reżyser plus sortowanie i limit
db.movies.aggregate(
[
{$project : {directed_by : 1, zysk : {$subtract : ["$revenue.Amount","$budget.Amount"]}, revenue : 1, budget : 1}},
//tym rozbijemy tablicę reżyserów i będzie osobna kopia całości dla każdej pozycji w tabeli
{$unwind: "$directed_by"},
{$group :
{
_id : "$directed_by",
średniZysk : {$avg : "$zysk"}
}
},
{$sort : {średniZysk : -1}},
{$limit: 5}
])
// dwie agregacje w 1 zapytaniu
db.movies.aggregate(
[
{$facet :
{
unikalneJęzyki : [{$group : {_id : "$original_language"}}],
unikalneGatunki : [{$unwind : "$genres"},{$group : {_id : "$genres"}}]
}
}
])
// konwersje - działają od wersji 4
db.persons.aggregate([
{
$project: {
_id: 0,
gender: 1,
birthdate: { $convert: { input: '$dob.date', to 'date'} }, //konwercja daty, można też date: {$toDate: "$dob.date"}
age: "$dob.age",
fullName: {
$concat: [
{ $toUpper: { $substrCP: ['$name.first', 0, 1] } }, //pierwsza litera imienia będzie duża
{
$substrCP: [
'$name.first',
1,
{ $subtract: [{ $strLenCP: '$name.first' }, 1] } //reszta nazwy
]
},
' ',
{ $toUpper: { $substrCP: ['$name.last', 0, 1] } }, //analogicznie z nazwiskiem
{
$substrCP: [
'$name.last',
1,
{ $subtract: [{ $strLenCP: '$name.last' }, 1] }
]
}
]
}
}
}
]).pretty();
//Lista unikalnych gatunków posortowanych malejąco po ilości filmów w każdym gatunku
db.movies.aggregate(
[
{$unwind : "$genres"},
{$group : {
_id : "$genres",
liczbaFilmow : {$sum : 1}
}},
{$sort : {liczbaFilmow : -1}}
])
// Lista występów aktorów per gatunek filmowy posortowana malejąco
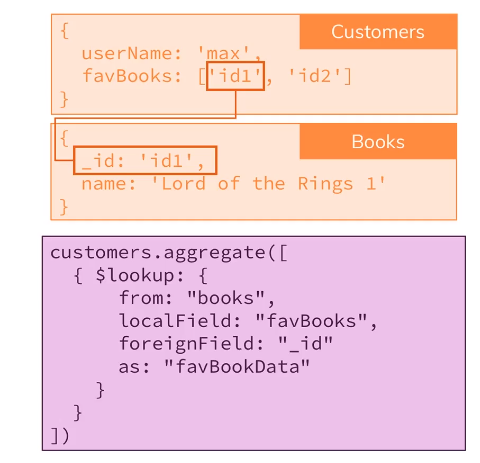
widoki
db.getCollectionInfos({type : "view"}) tak można je znaleźć. W pipeline można podejrzewć jak został stworzony.
db.createView(
"unikalneGatunki",
"movies",
[
{$unwind : "$genres"},
{$group : {_id : "$genres"}}
]
)
mapReduce
depricated, raczej zaleca się agregacje, choć można użyć do dużych agregacji
var map = function(){
emit(this.original_language, 1)
}
//en : [1,1,1,1,1,1,1,1,1..........]
//fr : [1,1,1,1,1,1,1,1,1..........]
var reduce = function(key, values){
var multi = 1
if(key = 'fr'){
multi = 4
}
return Array.sum(values) * multi
}
db.movies.mapReduce(
map,
reduce,
{
out : {inline : 1}
})
//--------------------
// Policzyć sumę przychodu per gatunek filmowy
var map = function(){
var me = this;
this.genres.forEach(function(genre){
emit(genre, me.revenue.Amount)
})
}
var reduce = function(key, values){
return Array.sum(values)
}
db.movies.mapReduce(
map,
reduce,
{
out : {inline : 1}
})
można też użyć finalize
var map = function(){
var self = this;
this.genres.forEach(function(genre){
emit(genre, { przychod: self.revenue.Amount, count : 1})
})
}
var reduce = function(key, values){
var sumaPrzychodu = 0;
var sumaCount = 0
values.forEach( x=> {
sumaPrzychodu = sumaPrzychodu + x.przychod,
sumaCount = sumaCount + x.count
})
return { przychod: sumaPrzychodu, count : sumaCount}
}
var finalizer = function(key,reducedValue){
return reducedValue.przychod / reducedValue.count
}
db.movies.mapReduce(
map,
reduce,
{
finalize : finalizer,
out : {inline : 1}
})
Indexy
zapytanie, które zwraca większość wyników kolekcji, jest z indexem wolniejsze niż bez, index na parę przyspiesza też wyszukiwanie na 1 element, na 2 już nie index przyspiesza i zmiejsza zużycie pamięciu przy sotrowaniu jak mamy index na name, i zwracamy bez id, to pobranie samego name jest bardzo szybkie możemy też dodawać indexy na array, można tworzyć je w tle Można dać hinta, ale nie zawsze pomaga .hint(nazwa_indexu_lub_cały_index)
db.indexTest.stats()
db.contacts.getIndexes()
db.contacts.explain("executionStats").find({"dob.age": {$gt:60}}) //spraw. wydajności
// .totalDocsExaminated - liczba przeszukiwanych elementów
//executionsStages.saveState - licczba wstrzymań
//executionsStages.restoreState - liczba wznowień
db.contacts.createIndex({"dob.age": 1}) // tworzy index, 1 - rosnąco, -1 - malejąco
db.contacts.createIndex({"dob.age": 1, gender: 1}) // index na parę
db.contacts.createIndex({"email": 1}, {unique: true}) // unikalny
db.indexTest.createIndex({"job.$**" : 1}) // indeksuje z wildcardem - tworzy osobne indeksy dla każdego z pól wewnątrz job
db.indexTest.createIndex({"$**" : 1}) // pojedyńcze indexy na wszystko, można dodać wyjątki - czyli oprócz jakich pól
db.contacts.explain().find({"dob.age": 35}).sort({gender: 1}
db.contacts.explain("allPlanExecution").. // szczegóły dla wszystkich planów
db.rating.createIndex({age: 1), backgroud: true}) // bez blokowania cokelkcji
db.contaxts.dropIndex("nazwa_bądz_warunek")
//partial index - jak nie potrzebujemy całej wartości indexu
db.contacts.createIndex({"dob.age": 1}, {partialFilterExpression: {gender: "male"}})
//pratial unique - tylko na elementy, które mają email
db.users.createIndex({email: 1}, {unique: true, partialFilterExpression: {email: {$exist: true}}})
//ttl index - usuwa elementy po czasie
db.sessions.createIndex({jakaesPole: 1}, {expireAfterSeconds: 10})
//text index - przydatny do szukania - rozdziela słowa, usuwa mało znaczne i przyspiesza szukanie
// może być tylko jeden na kolekcję, ale może być na więcej niż 1 polu
db.products.createIndex({description: "text"})
db.movies.createIndex("$**" : "text"} // wildcard na wszystkiepola
db.products.find({$text: {$search: "book"}})
db.products.find({$text: {$search: "book -t-shirt"}}) //book, ale bez t-sirt
db.products.find({$text: {$search: "\"awesome book\""}}, score: {$meta: "textScore"}).sort({ score: { $meta: "textScore" }})
db.products.find({$text: {$search: "awesome book"}, {score: {$meta: "textScore"}}})
.sort({score: {$meta: "textScore"}) //wyszukuje i daje punkty, jak bardzo się zgadza
//można ustawić język, który ma związek z tym jakie słowa będą nieuwzgędniane
//można też ustawić wagę, dzięki czemu np. description będzie 10 razy ważniejszcze
//przy liczeniu score
db.products.createIndex({title: "test", description: "text"},
{default_language: "german", weights: {title: 1, description: 10}})
//statysyki indexów - od ostatniego restartu
db.indexTest.aggregate( [ { $indexStats: { } } ] )
// zwraca indexy które nie były użyte - od ostatniego restartu
db.indexTest.aggregate([{$indexStats: {}}, {$match : {"accesses.ops" : 0}}])
Cache
mongo dodaje do cache jaki index ma być użyty, możemy dadać tam swoje ustawienie, ale skasuje się to po restarcie bazy
db.indexTest.aggregate([{$planCacheStats : {}}])
db.indexTest.getPlanCache().clear()
db.runCommand(
{
planCacheSetFilter: "indexTest",
query: {a:10},
indexes: [{a:1}]
}
)
Wykonywanie js
mongo creditrating.js
conn = new Mongo();
db = conn.getDB("credit");
for (let i = 0; i < 1000000; i++) {
db.ratings.insertOne({
"person_id": i + 1,
"score": Math.random() * 100,
"age": Math.floor(Math.random() * 70) + 18
})
}
Tranzakcje
const session = db.getMongo().startSession()
session.startTransaction()
const usersColl - session.getDatabase("blog").users
usersColl.deleteMany()
session.commitTransaction();
Schema Validation
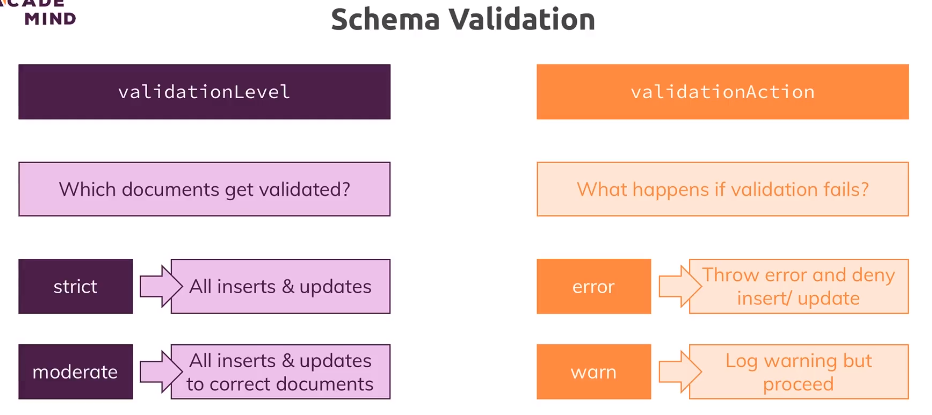
Mamy 3 poziomy walidacji: off - wyłączona, strict - domyślnia - każdy insert i update, moderate - stare - mogą nie spełniać warunku, a nowe, lub te dlaa których było poprawnie już nie Mamy 2 akcje dla dokumentów niespełniających: error - dokument nie zostanie zapisany, warn - zostanie zapisany, ale jest ostrzerzenie. W starej konsoli jest wyjaśnienie czego dotyczy błąd, a w nowej jest tylko info, że jest błędne
//zmina walidacji istniejącej kolekcji
db.runCommand({
collMod: 'posts',
validator: { (jak niżej) },
validationAction: 'warn' // będzie ostrzerzenie a nie błąd przy dodawaniu
})
// Dodanie walidacji do kolekcji
db.createCollection("products3", {
validator: {
$and: [
{ name: { $type: "string"}},
{ price: { $gt: 10 }},
{ price: { $type: "numeric" }},
]
}
});
//albo
db.createCollection("posts", {
validator: {
$jsonSchema: {
bsonType: "object",
required: ["title", "comments"],
properties: {
title: {
bsonType: "string",
description: "must be a string and required"
},
comments: {
bsonType: "array",
description: "must be an array and required",
items: {
bsonType: "object",
required: ["text", "author"],
properties: {
text: {
bsonType: "string",
description: "must be a string and required"
},
author: {
bsonType: "objectId",
description: "must be a objectId and required"
}
}
}
},
}
}
}
})
Replica set
Proces posiadania tych samych danych na kilku serwerach i synchronizacji. Mamy serwer primary i serwery secondary. rs.
- ustawiamy priorytet - w jakiej kolejności ma być wybierany primary server
- jest arbiter - taki będzeł, który nie ma danych - więc może być słaby, mniejsze bezpieczeństwo
- można ustawić, które serwery są liczone do kworum (większości) czyli mają vote, a które nie. Może być max 7 serwerów co mają vote. A 50 w całym replika secie.
- węzeł hidden - można jak np., chcemy wydzielić jeden do jakiiś raportów, a żeby aplikacja tam n ie uderzała
// Wyłączyć działające mongod
// Przygotować katalogi na dane:
- db
- db2
- db3
//Uruchimić 3 instancje mongod
mongod --port 27017 --dbpath db --replSet rs1 --oplogSize 3
mongod --port 27018 --dbpath db2 --replSet rs1 --oplogSize 3
mongod --port 27019 --dbpath db3 --replSet rs1 --oplogSize 3
mongosh --port 27017
rs.initiate()
rs.status()
rs.config()
rs.printReplicationInfo()
rs.printSecondaryReplicationInfo()
rs.add("localhost:27018")
rs.add("localhost:27019")
/// zmiana priority
var cfg = rs.config()
4. Zmienić priorytet na 10 dla serwer od indeksie 0
cfg.members[0].priority = 10
5. Wczytać konfiguracje ze zmiennej
rs.reconfig(cfg)
Sharding
Rozdzielenie danych na kilka serwerów (shard). Jest Query router - wie gdzie są dane. Można zrobić ręcznie, albo automatycznie. sh.
Uruchomić z flagą shardsvr
mongod --port 27017 --dbpath db --replSet rs1 --oplogSize 3 --shardsvr
mongod --port 27018 --dbpath db2 --replSet rs1 --oplogSize 3 --shardsvr
mongod --port 27019 --dbpath db3 --replSet rs1 --oplogSize 3 --shardsvr
------------------------------
rs2:
1. Stworzyć katalog na dane "rs2db"
2. Uruchimić instancje rs2
mongod --port 27027 --dbpath rs2db --replSet rs2 --oplogSize 3 --shardsvr
3. Zainicjalizować repl set
rs.initiate()
------------------------------
cfg:
1. Stworzyć katalog na dane "cfgdb"
2. Uruchimić instancje cfgrs
mongod --port 27037 --dbpath cfgdb --replSet cfgrs --oplogSize 3 --configsvr
3. Zainicjalizować repl set
rs.initiate()
------------------------------
mongos
mongos --port 27050 --configdb "cfgrs/localhost:27037"
------------------------------
Połączyć się z mongosem (QR):
mongosh --port 27050
sh.status()
//dodajemy shardy
sh.addShard("rs1/localhost:27017,localhost:27018,localhost:27019")
sh.addShard("rs2/localhost:27027")
sh.shardCollection("test.indexTest",{a:1}) //shardowanie po polu a
sh.status() /// tu można zobaczyć wynik, trzeba poczekań aż balancing porozrzuca dane
-----
sh.splitAt("test.indexTest", {a : 66}) // tak można ręczenie rodzielić dane
GridFS
Służy do przechowywania plików w mongoDB, raczej dla małych rozwiązań. Są one dzielone na 256kB.
ściągnąć mongodb-database-tools-ubuntu2004-x86_64-100.6
mongofiles put <nazwa_pliku> //dodanie pliku
db.fs.files.find() // tu jest plik, dodają się 2 kolekcje fs.files i fs.chunks do aktualnej bazy danych
mongofiles get <nazwa_pliku> --local <nowa_nazwa_pliku> // tak można pobrać
mongofiles find
Monitoring
można użyć mongostats z mongodb-database-tools
db.aggregate([ //na bazie admin
{$currentOp : {}},
{$sort : {microsecs_running : -1}}
])
db.oplog.rs.find({op : {$ne : "n"}}) // oplog bez pustej komendy do mognor robi co 10 sekund
Profilowanie
db.system.profile ma domyślnie 1 mb, ale można to sobie zwiększyć
db.setProfilingLevel(2)
db.system.profile.find()
db.setProfilingLevel(0) // wyłaczenie
NoSQL
bazy kolumnowe np. cassandra
Tabla jest odwrócona o 90 stopni - dzięki temu zrobienie jakieś avg na tabeli co ma dużo rekordów wymaga tylko 1 przeszukiwania dysku i 1 odczytu. Minus jest przy zapisie i odczycie - wtedy jest więcej przeszukań i odczytów/zapisów