Dev docs - richardlehane/siegfried GitHub Wiki
Git
I've been loosely following this git branch approach. But with all my development straight on the "develop" branch.
Once you start, suggest creating feature branches off that develop branch, then merging them there, prior to merging with master for releases.
Checkout develop to see the latest code (it's about 50 commits ahead at the moment).
An overview of how sf works
There are four main interfaces at play when sf and roy run. All of these are defined in the core package. These interfaces are:
- the Identifier interface. This represents a unit of signatures that can produce a format identification (e.g. a PRONOM release is an Identifier). A single signature file can encode one or more Identifiers.
- the Matcher interface. This represents a different method of identification (e.g. file name, text characterisation, byte pattern matching). Depending on the Identifiers used, a signature file will have one or more Matchers.
- the Recorder interface. Recorders are spawned by Identifiers when
sfruns against a file (1:1). They are mutable structures that record hits from the Matchers and then report the Identification when the scan ends. They apply the priority or other rules by which an Identifier determines the correct Identification(s) based on hits from the Matchers. - the Identification interface. This is the output that a Recorder produces having received signals from the Matchers. E.g. a PUID (fmt/1).
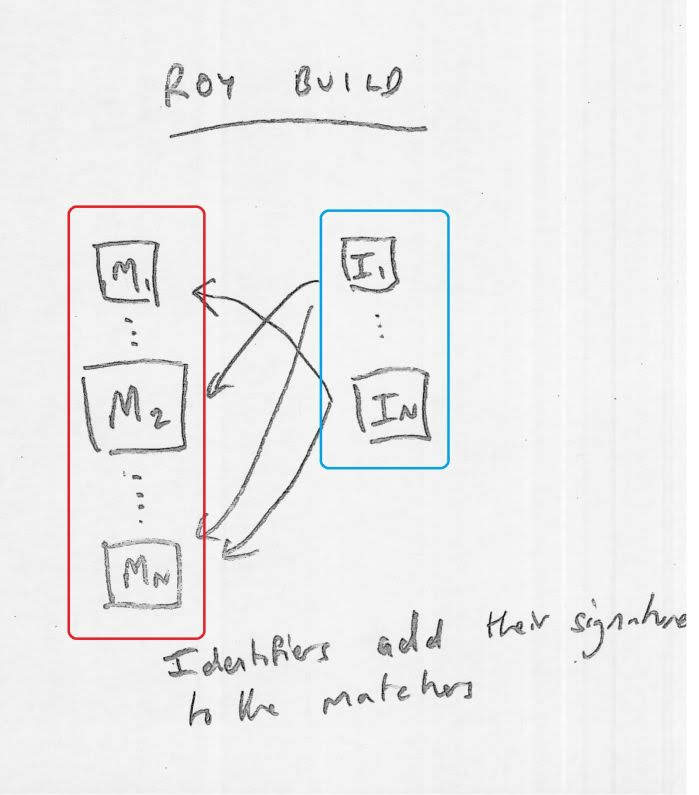
roy build
When you run roy build you are creating Identifiers and then adding signatures from those Identifiers to siegfried's Matchers. Those Identifiers and Matchers then get saved into your *.sig file.
sf scan
When you run sf, the Matchers and Identifiers from your *.sig file are loaded. For each file scanned, the Identifiers each generate their own Recorder. The file's signals (name, MIME - if known from scanning a WARC file, and bytes) are introduced to each of the Matchers. Those Matchers report their results to the Recorders.
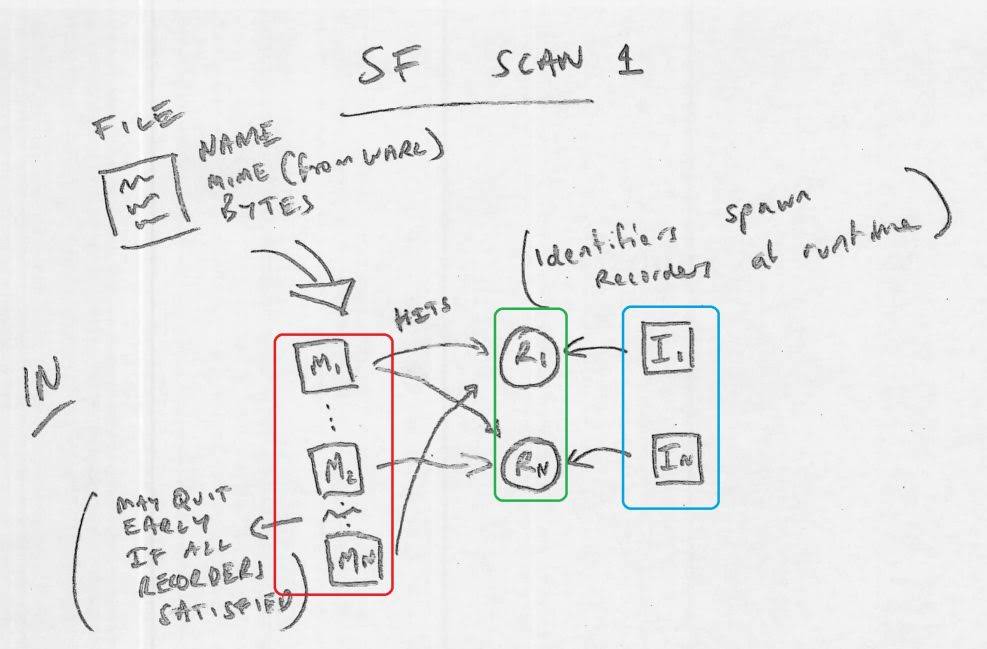
Note 1: Between running each of the Matchers, siegfried may check in with the Recorders to ask whether they are already satisfied. If all are satisfied, scanning ends early. E.g. this may mean a successful container match prevents the byte matcher running.
Note 2: Recorders may also provide "hints" to Matchers. This allows results of previous Matchers to influence successive ones. E.g. knowing that the file name has a "*.pdf" match may cause the byte matcher to continue scanning even after it has had a positive match for the TIFF format.
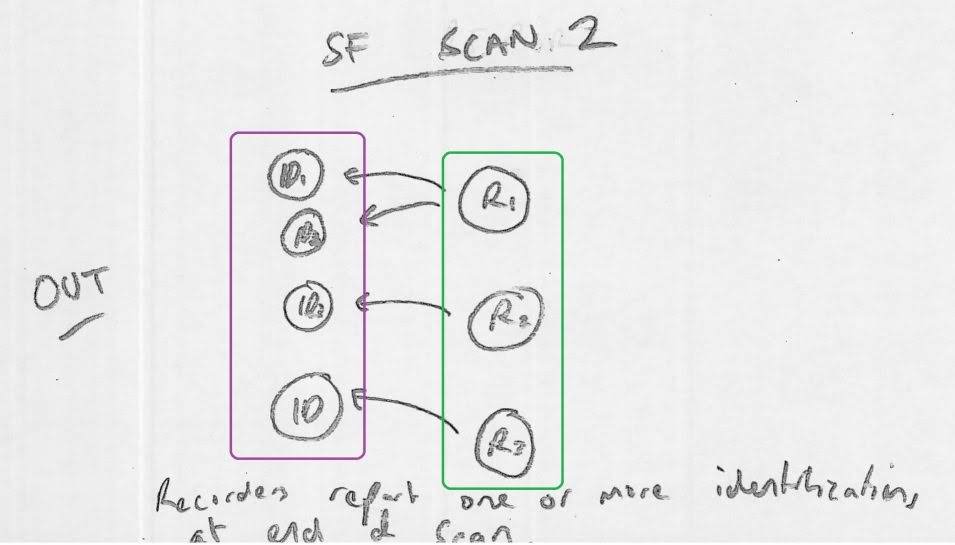
Finally, after a file has been scanned, each of the Recorders report one or more Identifications that are then printed as the output.
Creating a new identifier
-
Start by reading this code, that defines the Identifier interface:
-
Then look at some examples where I've implemented this interface, e.g. Library of Congress:
-
Now, before you freak out, thinking I have to implement all these crazy methods for a new Identifier, chill and take a look at:
This is a "base" implementation of an Identifier that does a lot of the heavy lifting and which you can just embed in your own Identifier. This is a pattern I used in all the Identifiers I made (PRONOM, LOC, MIMEInfo).