Database - ribeiry/AWS-Professional-Study GitHub Wiki
ElastiCache for Redis é um datastore na memória com performance excepcional que oferece latência inferior a um milissegundo a aplicativos em tempo real na escala da Internet.
-
Operações disponíveis :
- Sorted Sets
- In-Memory Data-Store
- Pub/Subnet
- Armazenamento de Sessão Suporta replicação de dados, e portanto entrega uma alta disponibilidade Obs.:
- Elasticache é baseado em armazenamento apenas de chave-valor e não de Relacional.
- O mecanismo Redis não oferece suporte a vários núcleos ou threads(multi-thread) de CPU.
-
Quando utilizar : Building real-time apps across versatile use cases like gaming, geospatial service, caching, session stores, or queuing, with advanced data structures, replication, and point-in-time snapshot support.
Serviço de armazenamento chave e valor em memória, que pode ser usado como cache ou data store
- Armazenamento de Sessão
- Não suporta replicação de dados e entrega menor disponibilidade
- Quando utilizar : Building a simple, scalable caching layer for your data-intensive apps.
- Lazy Loading: Todos os dado lidos são em cache, o dado podem ficar obsoletos
- Write Through: Adicionar ou atualizar dados em cache quando escrever no DataBase
- Session Store: Armazene Temporariamente os dados de sessão em cache usando a feature de TTL
Para RDS SQL Server e Oracle, a licença pode ser incluída na compra do serviço. Para Oracle ainda, tem a opção de trazer sua licença existente (BYOL).
-
Hardware Antes que a manutenção seja agendada, você recebe uma notificação por e-mail sobre as janelas de manutenção de hardware agendada que inclui o tempo da manutenção e as zonas de disponibilidade afetadas. Durante a manutenção de hardware, as implantações Single-AZ ficam indisponíveis por alguns minutos. As implantações Multi-AZ ficam indisponíveis pelo tempo que leva para o failover da instância (geralmente cerca de 60 segundos) se a zona de disponibilidade for afetada pela manutenção. Se apenas a Zona de disponibilidade secundária for afetada, não haverá failover ou tempo de inatividade.
-
Sistema Operacional Depois que a manutenção do sistema operacional for agendada para a próxima janela de manutenção, a manutenção pode ser adiada ajustando sua janela de manutenção preferida. Para minimizar o tempo de inatividade, modifique a instância do banco de dados Amazon RDS para uma implantação Multi-AZ. Para implantações Multi-AZ, a manutenção do sistema operacional é aplicada primeiro à instância secundária, em seguida, ocorre failover da instância e, em seguida, a instância primária é atualizada. O tempo de inatividade ocorre durante o failover. Para obter mais informações, consulte Manutenção para implantações multi-AZ.
-
Engine de banco de dados As atualizações no nível do mecanismo de banco de dados requerem tempo de inatividade. Mesmo se sua instância de banco de dados RDS usar uma implantação Multi-AZ, as instâncias de banco de dados principal e de reserva são atualizadas ao mesmo tempo. Isso causa tempo de inatividade até que a atualização seja concluída, e a duração do tempo de inatividade varia de acordo com o tamanho de sua instância de banco de dados.
OBS.: O RDS MySql não oferece suporte a scaling de leituras
O AWSAuthenticationPlugin é um plugin fornecido pela AWS, do qual ele se conecta com o seu IAM para poder autenticar os seus usuarios do IAM em seu RDS. Ao criar o usuario na em seu RDS é necessário indentifica-lo a forma de autenticação, Como por exemplo:
CREATE USER jane_doe IDENTIFIED WITH AWSAuthenticationPlugin AS 'RDS'. No qual a instrução IDENTIFIED WITH permite que o MySQL user o plugin para o usuario jane_doe.
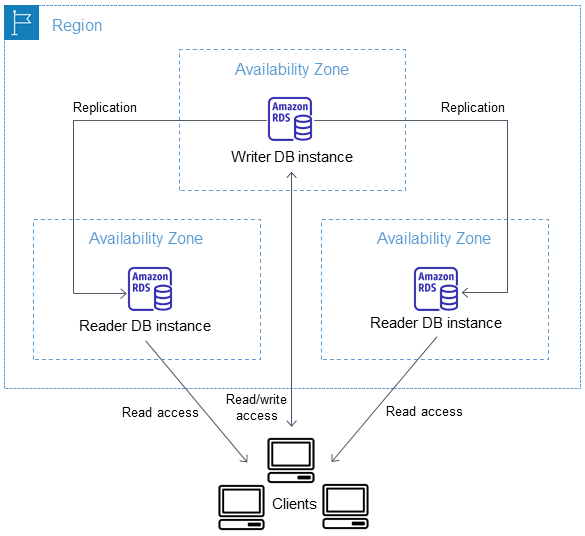
Multi-AZ RDS creates a replica in another AZ and synchronously replicates to it (DR only).
- Multi-AZ deployments for the MySQL, MariaDB, Oracle and PostgreSQL engines utilize synchronous physical replication.
- Multi-AZ deployments for the SQL Server engine use synchronous logical replication (SQL Server-native Mirroring technology).
Para sair de um modelo Single-AZ para Multi-AZ apenas click em modify, não ha necessidade de para a instancia, o que acontece é :
- É tirado um snapshot
- A nova DB é restaurada do snapshot na nova AZ
- A sincronização é estabelecida entre as duas instancias
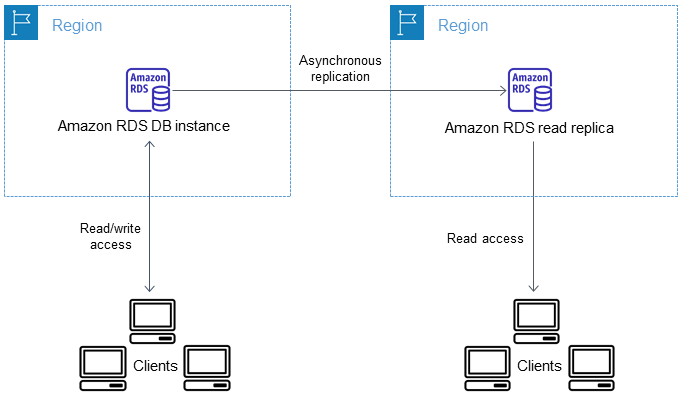
É possivel criar uma read replica aonde voce pode criar instancias de leitura em outras regiões e master fica em uma unica area. Como criar um read replica cross region
- Melhore seus recursos de recuperação de desastres.
- Replicação Asynchronous
- Dimensione as operações de leitura para uma região da AWS mais próxima de seus usuários.
- Facilite a migração de um datacenter em uma região da AWS para um datacenter em outra região da AWS.
- Não suportado para SQL Server.
- Read Replicas can be manually promoted to a standalone database instance for RDS MySQL
Aurora é um banco de dados relacional construido pela AWS em cima da engine do MySql, que tem performace melhor do que o MySQL devido ao seu desing.
O Amazon Aurora Serverless é uma configuração com escalabilidade automática sob demanda para Amazon Aurora. Ele inicia, encerra e expande a capacidade automaticamente de acordo com as necessidades do seu aplicativo. O Amazon Aurora Serverless permite que você execute um banco de dados na nuvem sem gerenciar qualquer capacidade de banco de dados.
O Amazon Aurora Global Database fornece acesso apenas de leitura a um banco de dados em várias regiões - ele não fornece configuração ativo-ativo com sincronização bidirecional (embora você possa fazer failover para seus bancos de dados somente leitura e promovê-los para graváveis caso o cluster principal ou a região onde está localizado o cluster principal caia).
Em caso de indisponibilidade da instancia Master o cluster Aurora toma as seguintes ações:
- Promove uma réplica saudável para a instancia master de acordo com a prioridade setada para a réplica ou de acordo com o tamanho, réplica ou de maneira aleatória.
- Se nenhuma Read Réplica saudável está disponível uma nova Instancia Master é criada, levando o aumento de down time.
É possível transformar um cluster existente do Aurora em um cluster Multi-AZ adicionando uma nova instância de leitor e especificando uma zona de disponibilidade diferente.
O Aurora armazena cópias dos dados em um cluster de banco de dados em várias zonas de disponibilidade em uma única região da AWS. O Aurora armazena essas cópias independentemente de as instâncias no cluster de banco de dados abrangerem várias zonas de disponibilidade. Para obter mais informações sobre o Aurora, consulte Gerenciar um cluster de banco de dados do Amazon Aurora.
Quando os dados são gravados na instância de banco de dados primária, o Aurora replica de forma síncrona os dados nas zonas de disponibilidade para seis nós de armazenamento associados ao volume do cluster. Isso fornece redundância de dados, elimina congelamentos de E/S e minimiza picos de latência durante os backups do sistema. A execução de uma instância de banco de dados com alta disponibilidade pode aumentar a disponibilidade durante a manutenção planejada do sistema e ajudar a proteger seus bancos de dados contra falhas e interrupção da zona de disponibilidade. Para obter mais informações sobre zonas de disponibilidade,
- Tipos de EndPoint
-
Built-in Cluster Built-in Cluster é o endpoint de escrita que se conecta a instancia primária do cluster
-
Built-in Reader Built-in Reader é o endpoint de leitura que balanceia a carga de leitura entre as Read Réplicas do cluster aurora, caso não haja Read Replicas definidas esse endpoint passa a consumir os dados da Instancia primária.
-
- Aurora Replicas trabalha bem para scaling para leitura por que eles são totalmente dedicados para operações de leitura em seu cluster. Operações de escrita são gerenciada pela instancia primaria. Por que o volume do cluster é compartilhado através de todas DB instancias, minimo e adicionais trabalham quando é requerida para replicação a uma copia de dados para cada Aurora Replica.
- Read Replicas for Aurora MySQL can be promoted to the primary instance

Você pode acompanhar logs do Banco de dados Aurora MySql através do Console, API, CLI ou SDK. Voce pode acessar o nivel de Logs diretamente para a database direcionando para uma tabela principal do banco de dados e consultando essa tabela.Você pode usar o utilitário mysqlbinlog para baixar o log binário
DynamoDb é um banco de dados NoSQL do tipo chave valor, algumas curiosidades sobre o DynamoDb:
- O consumo de throughput units e gargalos de IO é medido em termo de carga em cada partição
- Multi AZ por default
- Schema flexível
- Por default a criptografia do DynamoDB é feita usando o CMK da AWS
- A essência de uma instalação stateless é que os componentes escaláveis são descartáveis e a configuração é armazenada longe dos componentes descartáveis
- O Auto Scaling é habilitado por default para criação de tabelas via console management, quando criado via CLI essa opção deve ser habilitada manualmente
- Não há integração direta entre o CloudFront e o DynamoDB.
- O DynamoDB permite usar TTL (time to Live) pré definido na tabela é posivel setar via cli e via console
- Headers Atributtes DynamoDB :
- POST / HTTP/1.1
- Host: dynamodb..;
- Accept-Encoding: identity
- Content-Length:
- User-Agent:
- Content-Type: application/x-amz-json-1.0
- Authorization: AWS4-HMAC-SHA256 Credential=, SignedHeaders=, Signature=
- X-Amz-Date:
- X-Amz-Target: DynamoDB_20120810.GetItem
- Leitura consitente: O DynamoDB é por default deployado em multiplas AZs, quando uma escrita em uma tabela tem o status code 200, significa que o dado está eventualmente consistente através de todas as storage location, usualmente dentro de um minuto ou menos.
- Leitura eventualmente consistente : Leitura que pode não obter o dado mais atualizado.
- Leitura fortemente consistente : Requisição de leitura com consistencia forte trará o dado mais atualizado entre as AZs, embora isso pode trazer alguns efetios colaterais como :
- Maior latencia;
- Maior throughput;
- Pode eventualmente tomar um time out de rede etc.
- DynamoDb Captura eventos temporais de uma tabela, e armazena essas informações em Log, que fica disponivel por 24 horas
- DAX O Amazon DynamoDB Accelerator (DAX) é um cache de memória totalmente gerenciado e altamente disponível para o Amazon DynamoDB que oferece um ganho de performance de 10 vezes (de milissegundos para microssegundos).
As tabelas globais do Amazon DynamoDB fornecem uma solução totalmente gerenciada para a implantação de um banco de dados multi-regional e multimaster. Esta é a única solução apresentada que fornece uma configuração ativo-ativo em que leituras e gravações podem ocorrer em várias regiões com sincronização bidirecional completa.
Obs : Necessário habilitar DynamoDB Streams para pegar a alteração e usar para replicação do dado across regions
O Amazon DynamoDB tem dois modos de capacidade de leitura/gravação para processar leituras e gravações em suas tabelas:
- Sob demanda
- Provisionada (padrão, qualificada para o nível gratuito)
O modo de capacidade de leitura/gravação controla como você é cobrado por taxa de rendimento de leitura e gravação e como você gerencia a capacidade. Você pode definir o modo de capacidade de leitura/gravação ao criar uma tabela ou pode mudá-lo posteriormente.
Cada partição na mesa pode atender a até 3.000 unidades de solicitação de leitura ou 1.000 unidades de solicitação de gravação ou uma combinação linear de ambas. Se o tráfego para uma partição exceder esse limite, a partição poderá ser limitada. Para resolver esse problema:
- Se o CloudWatch Contributor Insights para DynamoDB para identificar as chaves acessadas e limitadas com mais frequência em sua tabela.
- Randomize as solicitações para a tabela de modo que as solicitações para as chaves de partição ativa sejam distribuídas ao longo do tempo. Para obter mais informações, consulte Usando a fragmentação de gravação para distribuir cargas de trabalho uniformemente.
- Keep item sizes small.
- If you are storing serial data in DynamoDB that will require actions based on data/time use separate tables for days, weeks, months.
- Store more frequently and less frequently accessed data in separate tables.
- If possible compress larger attribute values.
- Store objects larger than 400KB in S3 and use pointers (S3 Object ID) in DynamoDB.
Por padrão, o DynamoDb escreve operações (PutItem, UpdateItem, DeleteItem) são incondicionais: Cada operação sobreescreve uma operação existente item que ja tem uma chave primaria especifica.
O DynamoDb opcionalmente suporta escritas condicionais para estas operações. A escrita condicional escreve com sucesso apenas se um item atribuido encontra um ou mais condições esperada, isso ira retornar um erro. Escrita condicional ajuda em muitas situações. Por exemplo, voce pode querer uma operação de PutItem com sucesso apenas se não tiver lido um item com a mesma chave primaria. Ou voce pode prever uma operação de UpdateItem para modificar um item se um dos atributos tiver um certo valor.
Escrita condicional ajuda em casos aonde tem multiplos usuarios para modificar o mesmo item.
Referencia: Link
O Amazon EMR (Elastic Map Reduce) fornece uma estrutura Hadoop gerenciada que torna mais fácil, rápido e econômico processar grandes quantidades de dados em instâncias do Amazon EC2 dinamicamente escalonáveis. Ele lida de forma segura e confiável com um amplo conjunto de casos de uso de big data, incluindo análise de log, indexação da web, transformações de dados (ETL), aprendizado de máquina, análise financeira, simulação científica e bioinformática. Você também pode executar outras estruturas distribuídas populares, como Apache Spark, HBase, Presto e Flink no Amazon EMR, e interagir com dados em outros armazenamentos de dados AWS, como Amazon S3 e Amazon DynamoDB.
- Permite controle administrativo ao cluster EC2, pode ser acessado via SSH
- EMR é usado para processamento de Big Data
- Consiste de um Master Node, um Core Node e opicionalmente um Task Node
- Por default o log é armazenado no Master Node
- Você pode configurar a replicação de todo o log do Master Node para o S3 em intervalos de 5 minutos, porém isso pode ser feito apenas na primeira vez que é criado o cluster.
- Também suporta Apache Spark, HBase, Presto e Flink
- EMR Configuração de instancias
- Grupo de Instancia uniforme
- Seleciona um unico tipo de instancia e comprando a opção para cada nó(tem auto scaling)
- Fronta de Instancia (Instance Fleets): seleciona o alvo como capacidade, mistura de instancias e compare as opções (não tem auto scaling)
O Amazon Neptune é um serviço de banco de dados de grafos rápido, confiável e totalmente gerenciado que facilita a criação e a execução de aplicações que trabalham com conjuntos de dados altamente conectados. O núcleo do Neptune é um mecanismo de banco de dados gráfico com projeto específico e de alto desempenho. Esse mecanismo é otimizado para armazenar bilhões de relacionamentos e consultar gráficos com latência de milissegundos. O Neptune oferece suporte a linguagens comuns de consulta a gráficos, como Apache TinkerPop Gremlin e SPARQL do W3C. Isso permite que você crie consultas que navegam com eficiência em conjuntos de dados altamente conectados. O Neptune habilita casos de uso de gráficos, como mecanismos de recomendação, detecção de fraudes, gráficos de conhecimento, descoberta de medicamentos e segurança de rede. O Neptune é altamente disponível, com réplicas de leitura, recuperação point-in-time, backup contínuo para o Amazon S3 e replicação entre zonas de disponibilidade. O Neptune oferece recursos de segurança de dados, com suporte à criptografia em repouso e em trânsito. O Neptune é totalmente gerenciado, portanto, você não precisa mais se preocupar com tarefas de gerenciamento de banco de dados, como provisionamento de hardware, aplicação de patches no software, instalação, configuração ou backups.
Parque é um formato de arquivo open-source para Hadoop, que armazena aninhado a estrutura do dado em um formato colunar. Comparado a uma abordagem tradicional aonde o dado é armazenado em um orientado por linha, Parquet é um formato de arquivo mais efeciente em termos de armazenamento e performance. Isso é especial para queries que ler colunas específicas de um "wide"(com muitas colunas) tabelas que somente precisa de colunas para ler e IO é minimizado.
A Optimized Row Columnar (ORC) é um formato de arquivo que prove uma alta eficiencia para um armazenamento de dados. Isso é designado para superar as limitações de outro formato de arquivo. ORC é um formato de arquivo ideal para armazenar um dado compacto e habilita pulando partes irrelevantes sem a necessidade de ampla, complexa ou manual de manutenção de indicies. O formato de arquivo ORC endereça todas essas questões.
Vantagens do arquivo de formato ORC são:
- Um Unico arquivo de saida para cada tarefa, que reduz a carga do NameNode's;
- Cinco tipos suportados incluindo DateTime, decimal e tipos complexos (struct, list, map e união);
- Leitura concorrentes do mesmo arquivo usando separador de Leitura (RecordReaders);
- Formato de arquivo ORC habilita a divisão de arquivos sem escanear para marcadores;
- Estime um limite superior em alocação de memory Heap por Leitura/Escrita baseada em uma informação do rodapé do arquivo;
- Metada armazenado usando Protocolo Buffer, que permite adicionar e remover campos.
- PARQUET é mais capaz de armazenar dados aninhados;
- ORC é mais capaz de Empilhamento de Predicado;
- ORC suporta propriedades ACID;
- ORC é mais efeciente para compressão de arquivos