EMR 002 Large Scale Sorting on EMR - qyjohn/AWS_Tutorials GitHub Wiki
1. Problem Statement
Sorting is any process of arranging items systematically. Sorting has two common, yet distinct meanings: (1) ordering - arranging items in a sequence ordered by some criterion; and (2) categorizing - grouping items with similar properties. In this tutorial, we are going to sort a very large amount of test data so that the items in the test results are arranged in a particular order.
The sorting problem becomes a big data problem when the combined size of the input / intermediate / output data exceeds the storage space available on a single machine.
2. Theories
We encourage you to read the following Wikipedia articles on sorting to understand what sorting is, as well as the commonly used sorting algorithms. In particular, you need to understand that External Sorting is required when the data being sorted do not fit into the main memory of a computing device (usually RAM) and instead they must reside in the slower external memory, usually a hard disk drive.
The above-mention theories deal with the sorting of data on a single machine. When the combined size of the input / intermediate / output data is beyond the storage capacity of a single machine, parallel and distributed sorting is then required. In general, this is done on a cluster with multiple nodes. Initially, each node has a portion of the input data to be sorted. In general, parallel and distributed sorting involves the following steps:
-
Pre-Processing - Optional pre-processing on each node, for example, sorting the input data locally.
-
Partitioning - Each node represents a partition in the sorting network, receiving only a certain range of the data to be sorted. Assuming that we have 10 nodes and the range of the input data is from 1 to 9,999,999, then the 1st node / partition receives only the data from 1 to 1,000,000, while the 10th node / partition receives only the data from 9,000,000 to 9,999,999.
-
Mapping - Each node sends the input data to their destination nodes, based on the value of each individual item. Each node stores the data received as intermediate data on local storage.
-
Sorting - Each node sorts the intermediate data to produce the test result.
During the mapping process, input data is read from disk on the source node, sent over the network, and written to disk on the destination node. During the sorting phase, intermediate data is read from disk, sorted, and written to disk on each node. Therefore, parallel and distributed sorting usually requires 2X disk I/O (both reads and writes) and 1X network I/O. 3X disk space is usually required to store the input, intermediate, and output data, unless part of the input and intermediate data are deleted from disk during the sorting process.
In the industry, the Sort Benchmark compares external sorting algorithms implemented using finely tuned hardware and software. Each winning system provides detailed test reports describing both the hardware and software. If you are interested in the parallel and distributed sorting problem, you should read these test reports.
3. Demo/Test Introduction
In this demo, we will use Hadoop MapReduce to sort 2 TB of test data on an EMR cluster. Because the size of the input and output data (4 TB total) is beyond the storage capacity of a regular computer, sorting at this scale is usually done in a parallel and distributed manner.
The system to perform the above-mentioned sorting is an EMR cluster with 3 x i2.4xlarge nodes. The HDFS replication factor is set to 1 to avoid over-utilization of storage space. We used the teragen, terasort, and teravalidate application in the Hadoop MapReduce examples to generate the input, sort the data, and validate the output.
4. Demo/Test Procedure
(1) Launch an EMR cluster with 1 master node (m3.xlarge) and 2 core nodes (i2.4xlarge). The release version is emr-5.8.0. It should be noted that in an EMR cluster the master node does not participate in the computation and is not an HDFS data node. Each i2.4xlarge node has 16 vCPU, 122 GB memory, and 4 x 800 GB SSD storage. When there are less than 4 nodes in the EMR cluster, EMR automatically sets dfs.replication=1 for the EMR cluster.
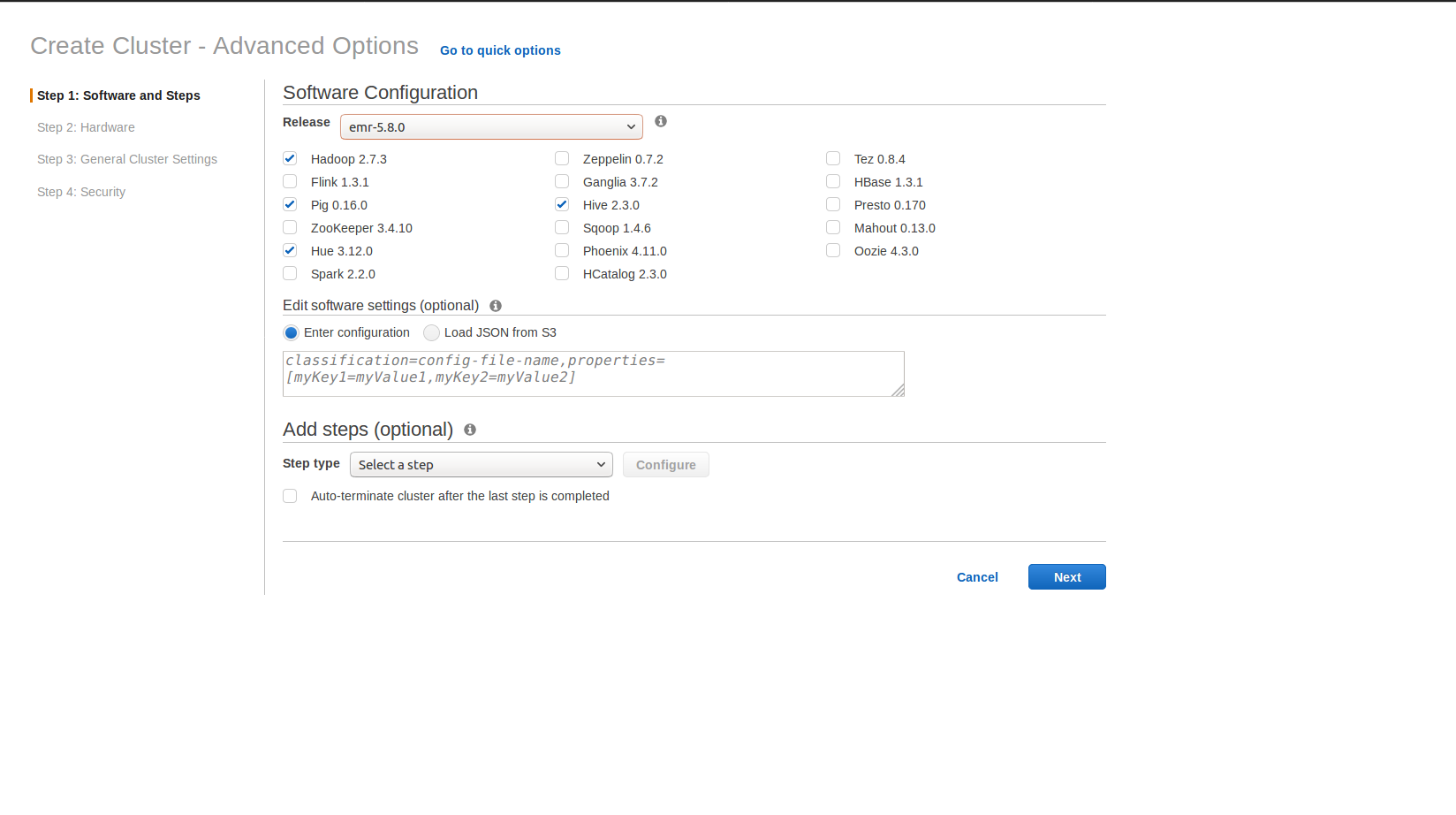
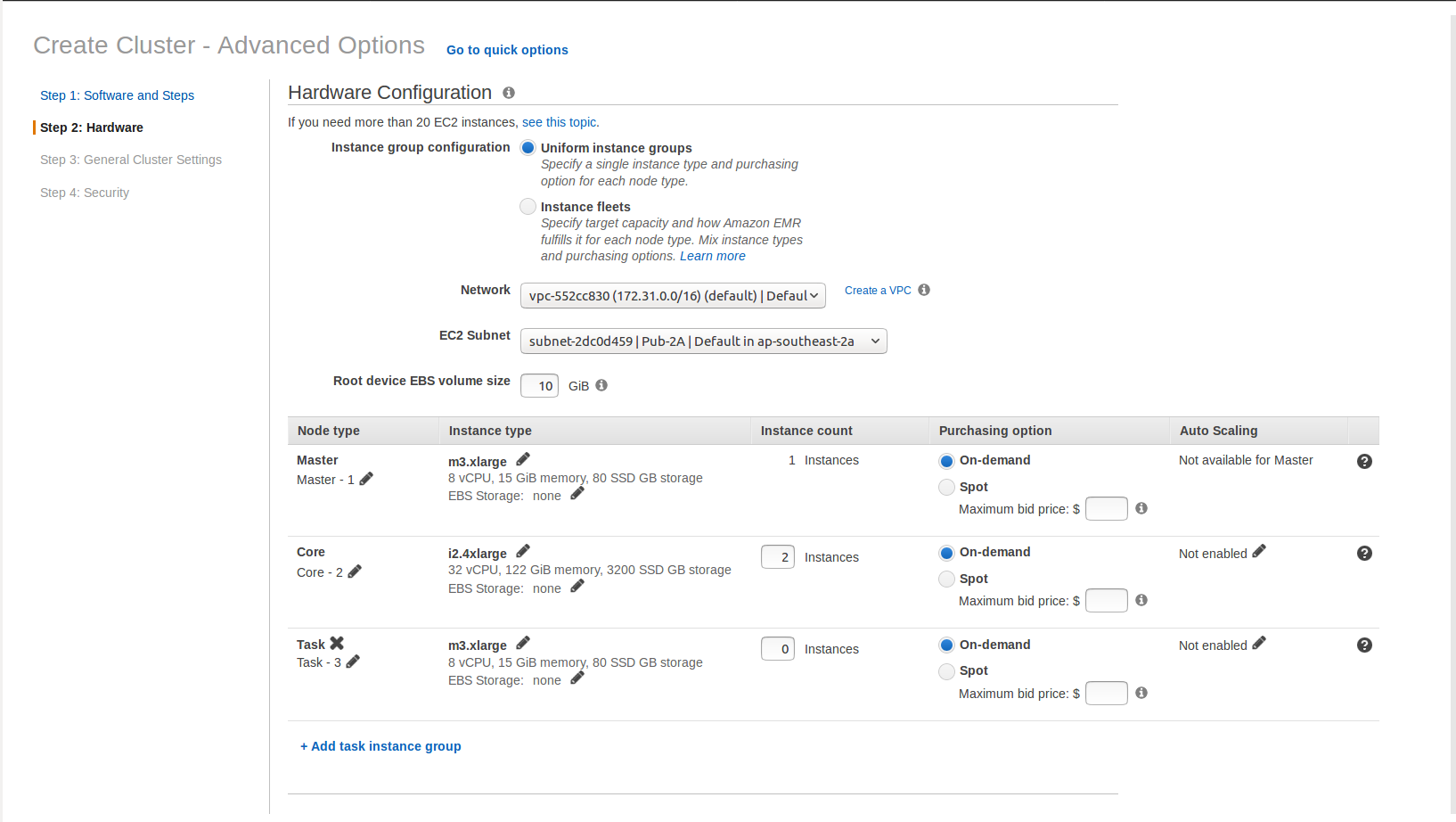
(2) SSH into the master node of the EMR cluster with "hadoop" as the username.
(3) Use the following command to view HDFS capacity. As shown in the command output, HDFS contains two data nodes, with 2.90 TB storage on each node.
[hadoop@ip-172-31-21-222 ~]$ hdfs dfsadmin -report
Configured Capacity: 6383165308928 (5.81 TB)
Present Capacity: 6382674655506 (5.81 TB)
DFS Remaining: 6381873709056 (5.80 TB)
DFS Used: 800946450 (763.84 MB)
DFS Used%: 0.01%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (2):
Name: 172.31.21.165:50010 (ip-172-31-21-165.ap-southeast-2.compute.internal)
Hostname: ip-172-31-21-165.ap-southeast-2.compute.internal
Decommission Status : Normal
Configured Capacity: 3191582654464 (2.90 TB)
DFS Used: 451154026 (430.25 MB)
Non DFS Used: 245215126 (233.86 MB)
DFS Remaining: 3190886285312 (2.90 TB)
DFS Used%: 0.01%
DFS Remaining%: 99.98%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Sep 08 00:55:59 UTC 2017
Name: 172.31.27.186:50010 (ip-172-31-27-186.ap-southeast-2.compute.internal)
Hostname: ip-172-31-27-186.ap-southeast-2.compute.internal
Decommission Status : Normal
Configured Capacity: 3191582654464 (2.90 TB)
DFS Used: 349792424 (333.59 MB)
Non DFS Used: 245438296 (234.07 MB)
DFS Remaining: 3190987423744 (2.90 TB)
DFS Used%: 0.01%
DFS Remaining%: 99.98%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Sep 08 00:56:00 UTC 2017
(4) Use the following command to generate the input data.
[hadoop@ip-172-31-21-222 ~]$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teragen 20000000000 /teraInput
17/09/08 01:15:40 INFO impl.TimelineClientImpl: Timeline service address: http://ip-172-31-21-222.ap-southeast-2.compute.internal:8188/ws/v1/timeline/
17/09/08 01:15:40 INFO client.RMProxy: Connecting to ResourceManager at ip-172-31-21-222.ap-southeast-2.compute.internal/172.31.21.222:8032
17/09/08 01:15:41 INFO terasort.TeraSort: Generating 20000000000 using 64
17/09/08 01:15:41 INFO mapreduce.JobSubmitter: number of splits:64
17/09/08 01:15:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1504831629578_0001
17/09/08 01:15:41 INFO impl.YarnClientImpl: Submitted application application_1504831629578_0001
17/09/08 01:15:42 INFO mapreduce.Job: The url to track the job: http://ip-172-31-21-222.ap-southeast-2.compute.internal:20888/proxy/application_1504831629578_0001/
17/09/08 01:15:42 INFO mapreduce.Job: Running job: job_1504831629578_0001
17/09/08 01:15:49 INFO mapreduce.Job: Job job_1504831629578_0001 running in uber mode : false
17/09/08 01:15:49 INFO mapreduce.Job: map 0% reduce 0%
17/09/08 01:16:12 INFO mapreduce.Job: map 1% reduce 0%
17/09/08 01:16:38 INFO mapreduce.Job: map 2% reduce 0%
17/09/08 01:16:55 INFO mapreduce.Job: map 3% reduce 0%
17/09/08 01:17:09 INFO mapreduce.Job: map 4% reduce 0%
......
17/09/08 01:38:56 INFO mapreduce.Job: map 96% reduce 0%
17/09/08 01:39:18 INFO mapreduce.Job: map 97% reduce 0%
17/09/08 01:39:39 INFO mapreduce.Job: map 98% reduce 0%
17/09/08 01:40:41 INFO mapreduce.Job: map 99% reduce 0%
17/09/08 01:42:12 INFO mapreduce.Job: map 100% reduce 0%
17/09/08 01:42:59 INFO mapreduce.Job: Job job_1504831629578_0001 completed successfully
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=8154998
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=5614
HDFS: Number of bytes written=2000000000000
HDFS: Number of read operations=256
HDFS: Number of large read operations=0
HDFS: Number of write operations=128
Job Counters
Killed map tasks=2
Launched map tasks=66
Other local map tasks=66
Total time spent by all maps in occupied slots (ms)=9785465766
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=85837419
Total vcore-milliseconds taken by all map tasks=85837419
Total megabyte-milliseconds taken by all map tasks=313134904512
Map-Reduce Framework
Map input records=20000000000
Map output records=20000000000
Input split bytes=5614
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=136647
CPU time spent (ms)=36582810
Physical memory (bytes) snapshot=63729070080
Virtual memory (bytes) snapshot=330655215616
Total committed heap usage (bytes)=64965050368
org.apache.hadoop.examples.terasort.TeraGen$Counters
CHECKSUM=6056631481885948571
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=2000000000000
The data generation phase took approximately 30 minutes to complete. You can view the various metrics on the EMR cluster using the "Monitoring" tab in the EMR console. In the data generation phase, it is useful to look into the "HDFS Utilization" and "HDFS Bytes Written" graphs.
On the node level, we can also use the CloudWatch console to view the CPU utilization, network I/O, and disk I/O on each node. In terms of CPU utilization, both core nodes reached 100% CPU utilization, while the CPU utilization on the master node was very low. In terms of disk I/O, both core nodes had a large amount of data written to disk, while there was no data written to disk on the master node. In terms of network I/O, there was very little network I/O on all nodes, as compared to the level of disk I/O observed on the core nodes.
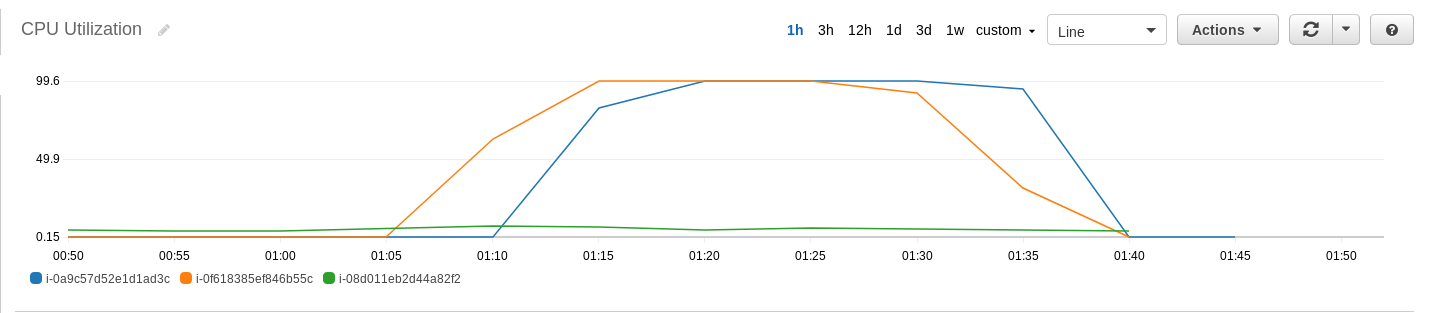
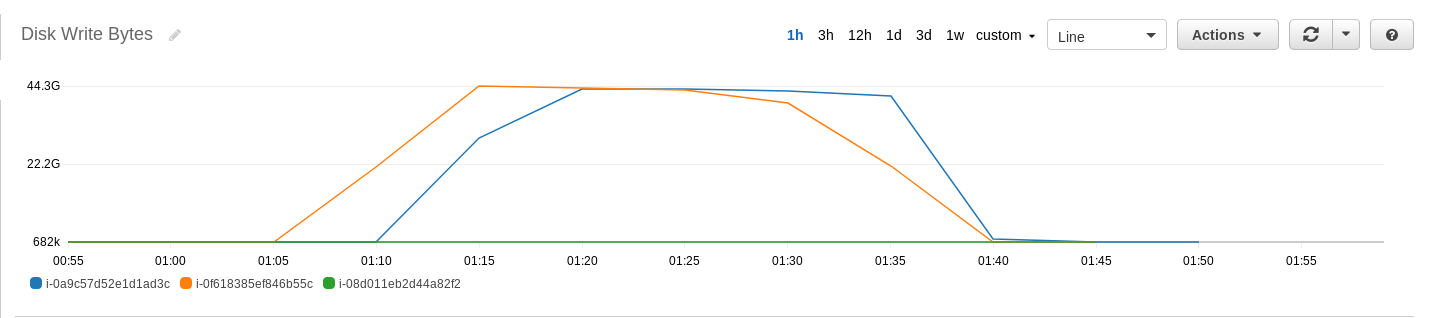
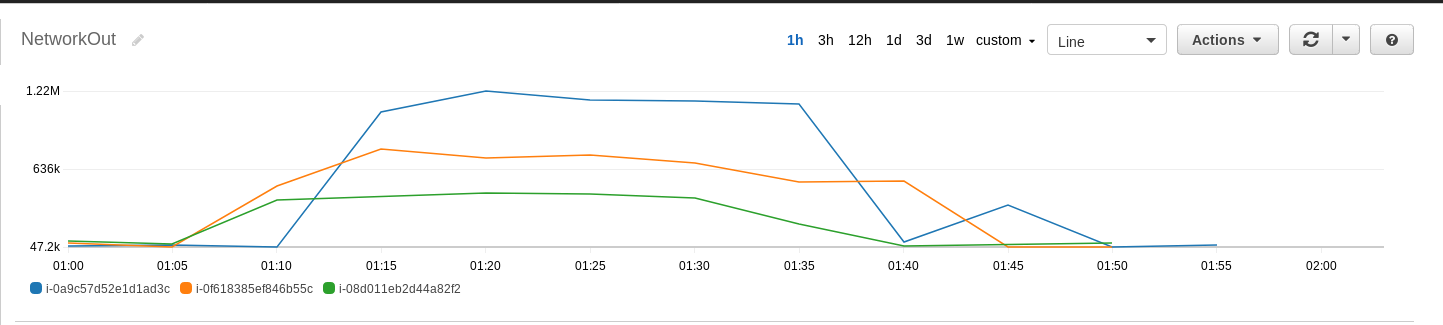
(5) Use the following command to sort the input data
[hadoop@ip-172-31-21-222 ~]$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar terasort /teraInput /teraOutput
17/09/08 02:01:12 INFO terasort.TeraSort: starting
17/09/08 02:01:14 INFO input.FileInputFormat: Total input paths to process : 64
Spent 753ms computing base-splits.
Spent 89ms computing TeraScheduler splits.
Computing input splits took 843ms
Sampling 10 splits of 14912
Making 31 from 100000 sampled records
Computing parititions took 676ms
Spent 1520ms computing partitions.
17/09/08 02:01:15 INFO impl.TimelineClientImpl: Timeline service address: http://ip-172-31-21-222.ap-southeast-2.compute.internal:8188/ws/v1/timeline/
17/09/08 02:01:15 INFO client.RMProxy: Connecting to ResourceManager at ip-172-31-21-222.ap-southeast-2.compute.internal/172.31.21.222:8032
17/09/08 02:01:16 INFO mapreduce.JobSubmitter: number of splits:14912
17/09/08 02:01:16 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1504831629578_0002
17/09/08 02:01:16 INFO impl.YarnClientImpl: Submitted application application_1504831629578_0002
17/09/08 02:01:16 INFO mapreduce.Job: The url to track the job: http://ip-172-31-21-222.ap-southeast-2.compute.internal:20888/proxy/application_1504831629578_0002/
17/09/08 02:01:16 INFO mapreduce.Job: Running job: job_1504831629578_0002
17/09/08 02:01:31 INFO mapreduce.Job: Job job_1504831629578_0002 running in uber mode : false
17/09/08 02:01:31 INFO mapreduce.Job: map 0% reduce 0%
17/09/08 02:02:36 INFO mapreduce.Job: map 1% reduce 0%
17/09/08 02:04:05 INFO mapreduce.Job: map 2% reduce 0%
17/09/08 02:05:50 INFO mapreduce.Job: map 3% reduce 0%
17/09/08 02:07:25 INFO mapreduce.Job: map 4% reduce 0%
......
17/09/08 05:35:28 INFO mapreduce.Job: map 100% reduce 96%
17/09/08 05:36:22 INFO mapreduce.Job: map 100% reduce 97%
17/09/08 05:37:19 INFO mapreduce.Job: map 100% reduce 98%
17/09/08 05:38:48 INFO mapreduce.Job: map 100% reduce 99%
17/09/08 05:40:36 INFO mapreduce.Job: map 100% reduce 100%
17/09/08 05:42:05 INFO mapreduce.Job: Job job_1504831629578_0002 completed successfully
17/09/08 05:42:05 INFO mapreduce.Job: Counters: 51
File System Counters
FILE: Number of bytes read=909878072144
FILE: Number of bytes written=1792802087913
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2000002206976
HDFS: Number of bytes written=2000000000000
HDFS: Number of read operations=44829
HDFS: Number of large read operations=0
HDFS: Number of write operations=62
Job Counters
Killed map tasks=1
Launched map tasks=14912
Launched reduce tasks=31
Data-local map tasks=14875
Rack-local map tasks=37
Total time spent by all maps in occupied slots (ms)=45190274994
Total time spent by all reduces in occupied slots (ms)=42127669668
Total time spent by all map tasks (ms)=396405921
Total time spent by all reduce tasks (ms)=184770481
Total vcore-milliseconds taken by all map tasks=396405921
Total vcore-milliseconds taken by all reduce tasks=184770481
Total megabyte-milliseconds taken by all map tasks=1446088799808
Total megabyte-milliseconds taken by all reduce tasks=1348085429376
Map-Reduce Framework
Map input records=20000000000
Map output records=20000000000
Map output bytes=2040000000000
Map output materialized bytes=880993050187
Input split bytes=2206976
Combine input records=0
Combine output records=0
Reduce input groups=20000000000
Reduce shuffle bytes=880993050187
Reduce input records=20000000000
Reduce output records=20000000000
Spilled Records=40000000000
Shuffled Maps =462272
Failed Shuffles=0
Merged Map outputs=462272
GC time elapsed (ms)=18623264
CPU time spent (ms)=275541400
Physical memory (bytes) snapshot=16447003381760
Virtual memory (bytes) snapshot=77316479946752
Total committed heap usage (bytes)=37070665940992
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2000000000000
File Output Format Counters
Bytes Written=2000000000000
17/09/08 05:42:05 INFO terasort.TeraSort: done
The sort phase took 3 hours and 42 minutes to complete. The following CloudWatch metrics shows the CPU utilization, disk I/O and network I/O on the various nodes on the EMR cluster.
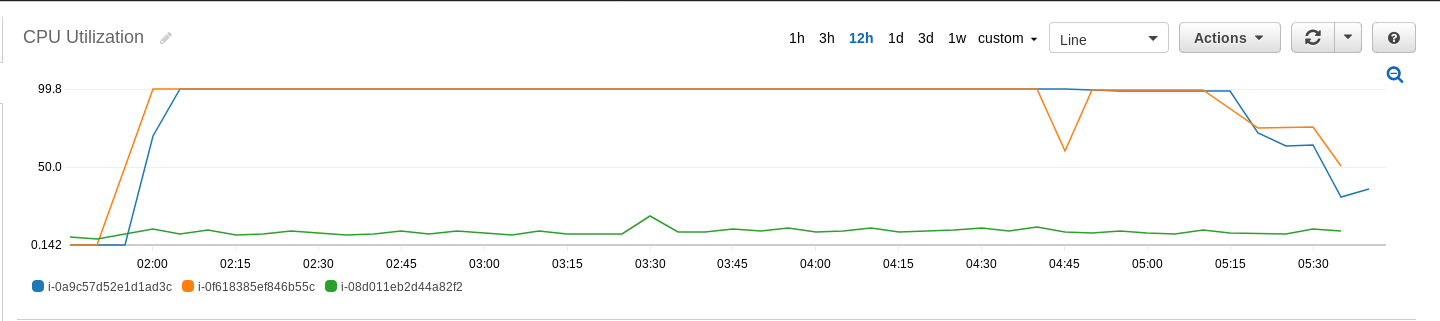
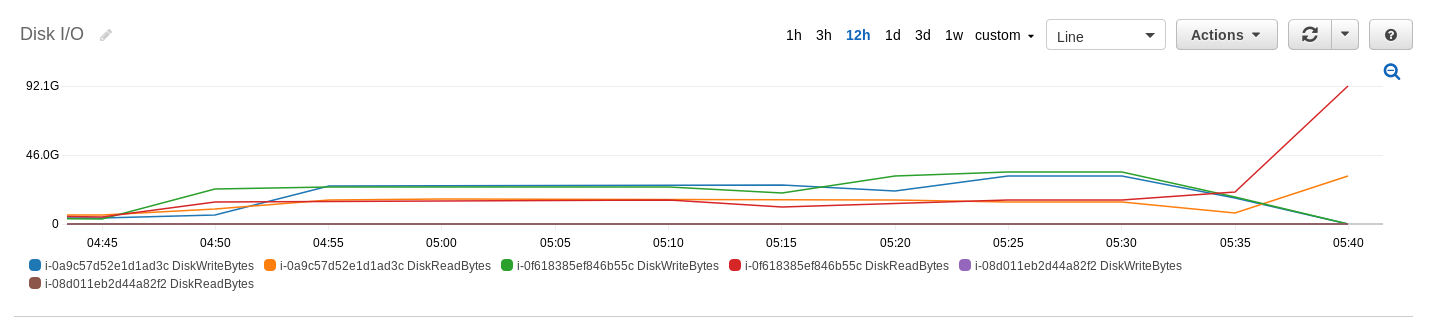
(6) Use the following command to validate the sorted results
[hadoop@ip-172-31-21-222 ~]$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teravalidate /teraOutput /teraValidate
17/09/08 05:42:52 INFO impl.TimelineClientImpl: Timeline service address: http://ip-172-31-21-222.ap-southeast-2.compute.internal:8188/ws/v1/timeline/
17/09/08 05:42:52 INFO client.RMProxy: Connecting to ResourceManager at ip-172-31-21-222.ap-southeast-2.compute.internal/172.31.21.222:8032
17/09/08 05:42:54 INFO input.FileInputFormat: Total input paths to process : 31
Spent 585ms computing base-splits.
Spent 4ms computing TeraScheduler splits.
17/09/08 05:42:54 INFO mapreduce.JobSubmitter: number of splits:31
17/09/08 05:42:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1504831629578_0003
17/09/08 05:42:54 INFO impl.YarnClientImpl: Submitted application application_1504831629578_0003
17/09/08 05:42:54 INFO mapreduce.Job: The url to track the job: http://ip-172-31-21-222.ap-southeast-2.compute.internal:20888/proxy/application_1504831629578_0003/
17/09/08 05:42:54 INFO mapreduce.Job: Running job: job_1504831629578_0003
17/09/08 05:43:02 INFO mapreduce.Job: Job job_1504831629578_0003 running in uber mode : false
17/09/08 05:43:02 INFO mapreduce.Job: map 0% reduce 0%
17/09/08 05:43:23 INFO mapreduce.Job: map 1% reduce 0%
17/09/08 05:43:33 INFO mapreduce.Job: map 2% reduce 0%
17/09/08 05:43:43 INFO mapreduce.Job: map 3% reduce 0%
17/09/08 05:43:53 INFO mapreduce.Job: map 4% reduce 0%
......
17/09/08 05:54:49 INFO mapreduce.Job: map 98% reduce 29%
17/09/08 05:54:50 INFO mapreduce.Job: map 98% reduce 31%
17/09/08 05:54:51 INFO mapreduce.Job: map 99% reduce 31%
17/09/08 05:54:53 INFO mapreduce.Job: map 99% reduce 32%
17/09/08 05:54:56 INFO mapreduce.Job: map 100% reduce 100%
17/09/08 05:54:57 INFO mapreduce.Job: Job job_1504831629578_0003 completed successfully
17/09/08 05:54:57 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1613
FILE: Number of bytes written=4095530
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2000000004619
HDFS: Number of bytes written=27
HDFS: Number of read operations=96
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=31
Launched reduce tasks=1
Data-local map tasks=31
Total time spent by all maps in occupied slots (ms)=2387093196
Total time spent by all reduces in occupied slots (ms)=16527720
Total time spent by all map tasks (ms)=20939414
Total time spent by all reduce tasks (ms)=72490
Total vcore-milliseconds taken by all map tasks=20939414
Total vcore-milliseconds taken by all reduce tasks=72490
Total megabyte-milliseconds taken by all map tasks=76386982272
Total megabyte-milliseconds taken by all reduce tasks=528887040
Map-Reduce Framework
Map input records=20000000000
Map output records=93
Map output bytes=2604
Map output materialized bytes=3039
Input split bytes=4619
Combine input records=0
Combine output records=0
Reduce input groups=63
Reduce shuffle bytes=3039
Reduce input records=93
Reduce output records=1
Spilled Records=186
Shuffled Maps =31
Failed Shuffles=0
Merged Map outputs=31
GC time elapsed (ms)=76486
CPU time spent (ms)=16490120
Physical memory (bytes) snapshot=49538342912
Virtual memory (bytes) snapshot=168361086976
Total committed heap usage (bytes)=62638784512
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2000000000000
File Output Format Counters
Bytes Written=27
[hadoop@ip-172-31-21-222 ~]$ hadoop fs -ls hdfs:///teraValidate
Found 2 items
-rw-r--r-- 1 hadoop hadoop 0 2017-09-08 05:54 hdfs:///teraValidate/_SUCCESS
-rw-r--r-- 1 hadoop hadoop 27 2017-09-08 05:54 hdfs:///teraValidate/part-r-00000
[hadoop@ip-172-31-21-222 ~]$ hadoop fs -cat hdfs:///teraValidate/part-r-00000
checksum 2540d7a3e4d427a9b