Spark Simple Query - pykello/pykello.github.com GitHub Wiki
[1] val df = spark.read.parquet("/home/hadi/tpcds-parquet/1g/date_dim").filter("d_year == 2001")
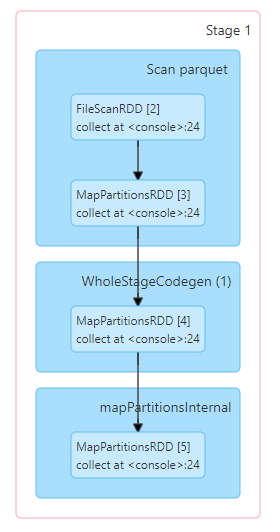
[2] df.collectLine 1 will run a job to get the schema:
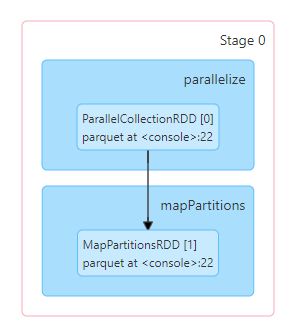
Line 2 does the execution.

import org.apache.spark.sql.execution.debug._
df.debugCodegenGenerated Code: https://gist.github.com/pykello/0b7c3517f33569c0f4ec53dc82ceb2bf
scala> df.rdd
res2: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[11] at rdd at <console>:27
scala> df.rdd.toDebugString
res3: String =
(1) MapPartitionsRDD[11] at rdd at <console>:27 []
| SQLExecutionRDD[10] at rdd at <console>:27 []
| MapPartitionsRDD[9] at rdd at <console>:27 []
| MapPartitionsRDD[8] at rdd at <console>:27 []
| MapPartitionsRDD[7] at rdd at <console>:27 []
| FileScanRDD[6] at rdd at <console>:27 []abstract class RDD[T: ClassTag] {
def compute(split: Partition, context: TaskContext): Iterator[T]
protected def getPartitions: Array[Partition]
protected def getDependencies: Seq[Dependency[_]] = deps
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
@transient val partitioner: Option[Partitioner] = None
}scala> ```scala
scala> df.rdd.partitions(0)
res7: org.apache.spark.Partition = FilePartition(0,[Lorg.apache.spark.sql.execution.datasources.PartitionedFile;@17589cd9)
df.rdd.partitions(0)
res7: org.apache.spark.Partition = FilePartition(0,[Lorg.apache.spark.sql.execution.datasources.PartitionedFile;@17589cd9)
scala> df.rdd.preferredLocations(df.rdd.partitions(0))
res8: Seq[String] = List()
scala> df.rdd.dependencies
res9: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@479693cc)
scala> df.rdd.dependencies(0).rdd
res11: org.apache.spark.rdd.RDD[_] = SQLExecutionRDD[10] at rdd at <console>:27
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd
res13: org.apache.spark.rdd.RDD[_] = MapPartitionsRDD[9] at rdd at <console>:27
scala> df.rdd.take(1)
res15: Array[org.apache.spark.sql.Row] = Array([2451911,AAAAAAAAHMJGFCAA,2001-01-01,1212,5270,405,2001,1,1,1,1,2001,405,5270,Monday,2001Q1,Y,N,Y,2451911,2451910,2451545,2451819,N,N,N,N,N])
scala> df.rdd.dependencies(0).rdd.take(1)
res25: Array[_] = Array([[2451911,AAAAAAAAHMJGFCAA,2001-01-01,1212,5270,405,2001,1,1,1,1,2001,405,5270,Monday,2001Q1,Y,N,Y,2451911,2451910,2451545,2451819,N,N,N,N,N]])
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.take(1)
res24: Array[_] = Array([0,2569c7,e800000010,2c3b,4bc,1496,195,7d1,1,1,1,1,7d1,195,1496,f800000006,10000000006,10800000001,11000000001,11800000001,2569c7,2569c6,256859,25696b,12000000001,12800000001,13000000001,13800000001,14000000001,4141414141414141,41414346474a4d48,7961646e6f4d,315131303032,59,4e,59,4e,4e,4e,4e,4e])
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.count
res34: Long = 365
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.take(1)
22/11/17 22:26:50 ERROR TaskSetManager: task 0.0 in stage 11.0 (TID 11) had a not serializable result: org.apache.spark.sql.vectorized.ColumnarBatch
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.count
res35: Long = 18
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.count
res37: Long = 18
scala> df.schema.length
res42: Int = 28scala> spark.conf.set("spark.sql.codegen.wholeStage", false)
scala> val df = spark.read.parquet("/home/hadi/tpcds-parquet/1g/date_dim").filter("d_year == 2001")
df: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [d_date_sk: int, d_date_id: string ... 26 more fields]
scala> df.collect
collect collectAsList
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.take(1)
res7: Array[_] = Array([0,2569c7,e800000010,2c3b,4bc,1496,195,7d1,1,1,1,1,7d1,195,1496,f800000006,10000000006,10800000001,11000000001,11800000001,2569c7,2569c6,256859,25696b,12000000001,12800000001,13000000001,13800000001,14000000001,4141414141414141,41414346474a4d48,7961646e6f4d,315131303032,59,4e,59,4e,4e,4e,4e,4e])
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.count
res8: Long = 73049
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.take(1)
res9: Array[_] = Array([0,24d9ae,e800000010,ffff9c22,0,1,1,76c,1,1,2,1,76c,1,1,f800000006,10000000006,10800000001,11000000001,11800000001,24d9ad,24d9ac,24d841,24d952,12000000001,12800000001,13000000001,13800000001,14000000001,4141414141414141,414143454e4a4b4f,7961646e6f4d,315130303931,4e,4e,59,4e,4e,4e,4e,4e])
scala> df.rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.dependencies(0).rdd.take(1)
22/11/17 22:54:03 ERROR TaskSetManager: task 0.0 in stage 9.0 (TID 9) had a not serializable result: org.apache.spark.sql.execution.vectorized.OnHeapColumnVector
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
child.execute().mapPartitions { iter =>
val predicate = Predicate.create(condition, child.output)
predicate.initialize(0)
iter.filter { row =>
val r = predicate.eval(row)
if (r) numOutputRows += 1
r
}
}
} override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
inputRDD.map { r =>
numOutputRows += 1
r
}
}
override def doExecuteColumnar(): RDD[ColumnarBatch] = {
val numOutputRows = longMetric("numOutputRows")
inputRDD.asInstanceOf[RDD[ColumnarBatch]].map { b =>
numOutputRows += b.numRows()
b
}
}class QueryExecution ... {
...
lazy val toRdd: RDD[InternalRow] = new SQLExecutionRDD(
executedPlan.execute(), sparkSession.sessionState.conf)
}
...
class DataSet[] {
...
lazy val rdd: RDD[T] = {
val objectType = exprEnc.deserializer.dataType
rddQueryExecution.toRdd.mapPartitions { rows =>
rows.map(_.get(0, objectType).asInstanceOf[T])
}
}
...
}