Part 7: Natural Language Processing - oooookk7/machine-learning-a-to-z GitHub Wiki
What is Natural Language Processing (NLP)?

(Source: Malcom Ridgers et., 2020)
Natural Language Processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence with a specific goal of making a computer capable of "understanding" (processing and analyzing) large amounts of natural language data (e.g. documents) and their contextual nuances of language in it, so that information and insights can be accurately extracted which can be categorized and organized. For example, it can learn and understand the insights or information in a human speech or text.
Some of the common tasks in NLP are,
- Optical Character Recognition: Converts printed/handwritten text from images or documents into machine-encoded text.
- Speech Recognition: Determines the textual representation of the speech.
- Speech Synthesis: Converts text to speech (which is a reverse of Speech Recognition).
- Word Segmentation (Tokenization): Separate a chunk of continuous text into separate words.
- Named Entity Recognition: Determine from the sentence to tag items/attributes in the text map to proper names such as people or places.
- Sentiment Analysis: Extracts subjective information from set of documents or text to determine "polarity" about specific objects (e.g. online reviews in social media for marketing).

(Source: Mitul Makadia, 2021)
In general, anything involving parsing or intepreting using linguistics and ML is part of NLP. It can start from Natural Language Understanding (NLU) to interpret features from the text, it also extents to Natural Language Generation (NLG) to generate a source data into text.
Technique where machine reads the given text, comprehends it and interprets a meaning (or information) out of it, like text-processing tasks such as text categorization, analyzing textual content, aggregating new information.
For example (of NER), a given sentence is,
the pomeranian dog, that has walked from its 1.5m owner Jason in the city of New York, is brown
The output becomes categorized as,
pet = {animal: dog, brown: color, pomeranian: breed, action: walking}
owner = {height: 1.5m, name: Jason}
location = {city: New York, country: United States}
The applications are Machine translation, Automated reasoning, Text categorization, Question answering, News gathering, Large-scale content analysis, Voice-activation.
Converts information from databases or semantic (language/logic) intents (e.g. generated tree to translate languge) into a natural (or readable) language, where it generates content in the form of text and speech based on whatever content is fed into it.
One example is the The Pollen Forecase for Scotland system that reports predicted pollen levels in different parts of Scotland based on given data,
For July 1, 2005, the software produces:
Grass pollen levels for Friday have increased from the moderate to high levels of yesterday with values of around 6 to 7 across most parts of the country. However, in Northern areas, pollen levels will be moderate with values of 4.
In constrant where the actual forecast (written by a human meteorologist) was:
Pollen counts are expected to remain high at level 6 over most of Scotland, and even level 7 in the south east. The only relief is in the Northern Isles and far northeast of mainland Scotland with medium levels of pollen count.
One of the application is a Data-to-Text systems.
For the rest of this notes/study, it only covers the NLU aspect where features are extracted and analysis are applied.
The documents provided needs to be cleaned and reduced (Text Preprocessing), then features are extracted from the corpus (Feature Extraction), before analysis comes in.
Some of the key applications in NLP includes,
- Named Entity Extraction (NER)
- Syntactical Analysis (Parsing)
- Semantic Analysis
- Sentiment Analysis
- Pragmatic Analysis


(Source: Harshith, 2019) (Source: @pramodAIML, 2020)
Text-processing steps are widely used for dimensionality reduction. In the vector space model, each word/term is an axis/dimension, and the text/document/sentence is represented as a vector in the multi-dimensional space, where the number of unique words signifies the number of dimensions.
Step 1: Normalization
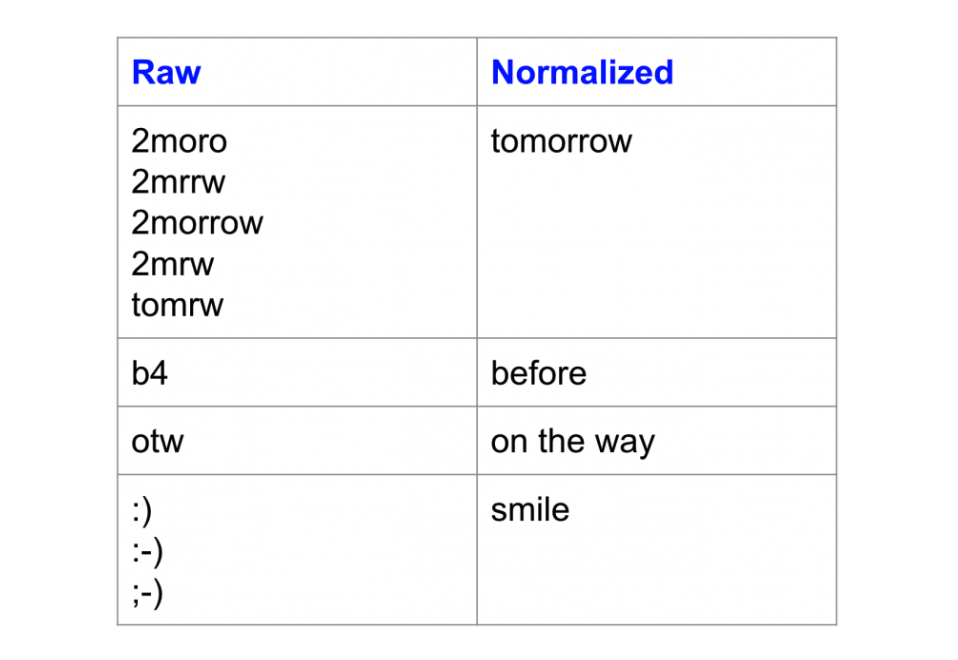
(Source: Kavita Ganesan, 2019)
Normalization transforms text into a canonical (standard) form. For example, the words "gooood", "goo-d" and "gud" can be transformed to "good" (or "stopwords", "stop words" to just "stop-words").
This is an important step for noisy texts such as social media comments, text messages, comments or blog posts where abbreviations, misspellings and out-of-vocabulary words (oov) are prevalent (e.g. normalization for Tweet were able to improve sentiment classifcation accuracy by ~4%).
Step 2: Tokenization

(Source: floydhub.com, 2020)
Before processing a natural language, the algorithm needs to identify the words that constitute a string of characters, hence that's why tokenization is a needed step to proceed with NLP, as the meaning of the text could be easily interpreted by analyzing the words present in the text. It would need to split the input into smaller chunks since the model doesn't know anything about the structure of the language before feeding it into the model, and Represent the input as a vector to learn the relationship between the words in a sentence or sequence of text.

(Source: floydhub.com, 2020)
This is the most simpliest and straightforward approach, where sentences are split into words or terms using spaces or punctuations.
However using this as a standard approach would run into problems, as you would need a big vocabulary when dealing with word tokens you can only learn which are in your training vocabulary, and unknown words are unidentified (the "<UNK>" token). You would also run into combined words which may cause confusion (e.g. "sunflower" and "flower"). There's also a need to handle abbreviated words or new lingos (e.g. "LOL", "TLDR") that may not be identified with a dictionary, and depending on your type of language, some doesn't work with spaces (e.g. Chinese).

(Source: floydhub.com, 2020)
Another approach is to split the words character-by-character, and this avoids running into unknown words (and may fit into other types of languages. That however, has it's own major drawbacks.
Characters lack meaning unlike words, so there is no guarantee that the learnt result would have any meaning. This also increases the input computation, where a 7-word sentence becomes 7-input tokens (e.g. if there are 5 characters in each words, this grows up to 35 tokens), which increases the complexity of the scale of inputs you need to process. This also limits network choices as increasing the size of your input sequences at character level also limits the type of network models (e.g. neural networks) you can choose, and may make things more difficult tow work with (e.g. Parts of Speech (POS) tagger/classifier).

(Source: thoughtvector.io, 2019)
To resolve the problems raised earlier, we can reuse words and create larger words from smaller ones. For example, words like "any" and "place" which make "anyplace" or compound words like "anyhow" or "anybody". This can also be expanded to split words up like "unfortunately" to "un" + "for" + "tun" + "ate" + "ly" for example. All that is needed is to remember a few words and put them together to create the other words, which requires much less memory and effort.
Depending on the size of the allowed vocabulary set, the larger the vocabulary, the more common words can be tokenize, and the smaller the vocabulary size, the more subword tokens that needs to avoid having to use the "<UNK>" token (unidentifable).
The algorithms to achieve them are, Byte Pair Encoding (BPE), WordPiece and Unigram.
Step 3: Removing Stop Words
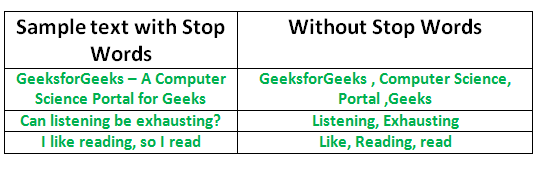
(Source: geeksforgeeks.org, 2021)
Stopwords are words that does not add much meaning to a sentence and can be safely ignored without sacrificing the meaning of the sentence. Some of the most common words are "is", "at", "which", "on" etc. In cases of text classification or sentiment analysis, removing stop words is useful as they do not provide any information to the model.
Some of the pros of removing stop words are that stop words occur in abundance, hence it provides little to no unique information for classification/clustering, and hence decreases the dataset and the time to train the model, which potentially improves the performance. The cons of such is when such removal can change the meaning of the text (e.g. "This movie is not good" to "movie is good" - if "not" is removed in the pre-processing step), and cause wrong intepretations.
Types of stopwords are,
- Determiners: Tend to mark nouns where a determiner usually will be followed by a noun (e.g. "the", "a", "an", "another").
- Coordinating conjunctions: Connect words, phrases and clauses (e.g. "for", "nor", "but", "or", "yet", "so").
- Prepositions: Express temporal or spatial relations (e.g. "in", "under", "towards", "before", "after").
The act of removing common phrases that adds not value are called stop phrases, which can be excluded too (e.g. if the phrase "adding to basket" appears frequently in the text with low discriminating power, removing such would be useful).
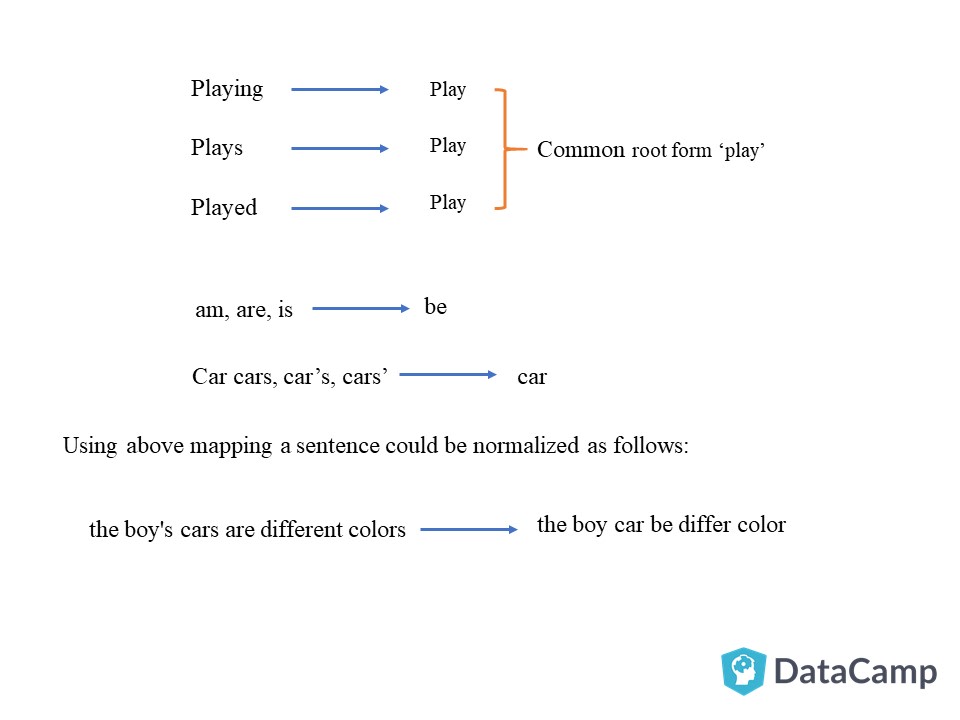
(Source: Hafsa Jabeen,2018)
"In grammar, inflection is the modification of a word to express different grammatical categories such as tense, case, voice, aspect, person, number, gender, and mood. An inflection expresses one or more grammatical categories with a prefix, suffix or infix, or another internal modification such as a vowel change" - Wikipedia
Stemming (which meaning is "to remove the stems") is the process that reduces the inflectional forms in words to their root forms such as mapping a group of words to the same stem even if the stem is not a valid word in the language (e.g. chopping off the ends of words).
(Source: exploreai.org, n.d.)
The three major stemming algorithms that are used are,
- Porter: Least aggressive stemming algorithm and one of the commonly used algorithms.
- Snowball: An improvement over Porter and has slightly faster computation time than Porter.
- Lancaster: Most aggressive stemming algorithm, and unlike Porter and Snowball, it is least intuitive to a reader as the words are hugely reduced, but this is the fastest algorithm amongst the three and helps to reduce the working set of words hugely.
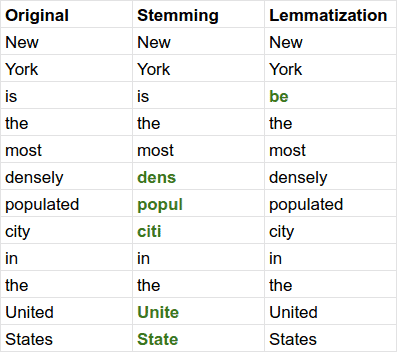

(Source: Francesco Elia, 2020) (Source: Kavita Ganesan, 2019)
Lemmatization (which Lemma means the canonical form or dictionary form), unlike Stemming, reduces the inflected words properly to ensure that the root word belongs to the language. Think of a more sophisticated version of stemming where it reduces each word to its base word which can be found in the dictionary.
To do so, it uses the part-of-speech (POS) tagging to achieve it, which below is an example of POS tagging from Dutch to English sentence,
(Source: Klaassen et., 2019)
- Stemming follows an algorithm with steps to perform on the words which makes it faster, whereas in Lemmatization, it requires to do tagging which (e.g. using WordNet corpus) which may make it slower than Stemming.
- Although both generate the root form of the inflected words, the word stem might not be an actual word whereas lemma is an actual word. The difference is that stem might not be an actual word whereas, lemma is an actual language word, which produces a more accurate result.

(Source: Susan Li, 2019)
After pre-processing the text data, the corpus can be converted to useful features, which serves as inputs for algorithms (e.g. classification of words or prediction of next words).
Depending on the max features requested, the features can be selected based on highest weight/count from the extracted corpus, and can be classified or run into models for further use of the data.
Decodes the syntax structure of the given sentence to understand the grammar and relationship between each words. It involves the analysis of words in the sentence for grammar and their arrangement in a manner that shows the relationships among the words.
For example is the Phrase structure rules,
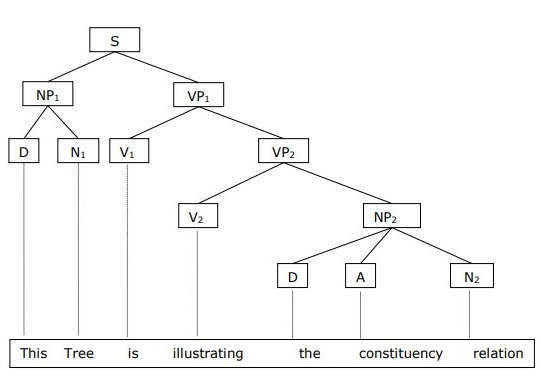
(Source: tutorialspoint.com, n.d.)
For interpretation,
- S: Sentence
- D: Demonstrative
- NP: Noun phrase
- VP: Verb phrase
- AP (optional): Adjective
- PP (optional): Preposition
They can be broken down into 2 parts, one being the Dependency Trees and the other the Part-of-Speech (POS) tagging.
Relationship among the words in a sentence is determined by basic dependency grammar, where it is a class of syntactic text analysis that deals with asymmetrical binary relations between the two lexical words.
For example, for the following sentence,
Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas.
This results in the following,

(Source: SHIVAM BANSAL, 2017)
Each relation is represented in a form of a triplet:
- Relation: The connection or relationship between the dependent (leaf node) and governor (parent node).
- Governor: The parent node of the leaf (dependent).
- Dependent: The leaf node of the parent (governor).
Every word in a sentence is associated with a part of speech tag (nouns, verbs, adjectives, adverbs).
For example,
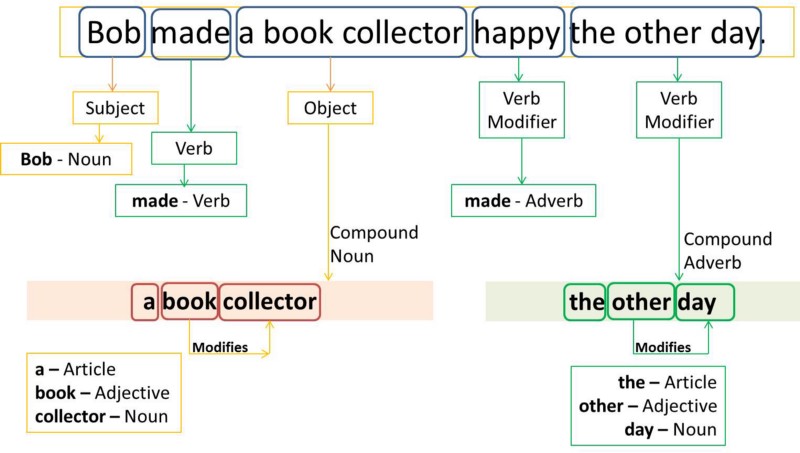
(Source: Divya Godayal et., 2018)
These are their advantages,
-
Word sense disambiguation: Some languages have multiple meanings according to their usage.
For example, in sentence 1,
Please book my flight
And in sentence 2,
I am going to read a book in the flight
In sentence 2, "book" is used with a different context, but in POS, sentence 1 is a verb but in sentence 2 it is a noun.
-
Improving word-based features: Preseves context using POS which makes stronger features.
For example, in this sentence,
book my flight, I will read this book
Tokens (without POS):
(“book”, 2), (“my”, 1), (“flight”, 1), (“I”, 1), (“will”, 1), (“read”, 1), (“this”, 1)Tokens (with POS):
(“book_VB”, 1), (“my_PRP$”, 1), (“flight_NN”, 1), (“I_PRP”, 1), (“will_MD”, 1), (“read_VB”, 1), (“this_DT”, 1), (“book_NN”, 1) -
Normalization and Lemmatization: Tags are basis of lemmatization process for converting to a word to base form (Lemma).
-
Efficient Stop word removal: For example, there are tags that always define the less important words of a language, like,
(IN – “within”, “upon”, “except”), (CD – “one”,”two”, “hundred”), (MD – “may”, “mu st”)
In the case of NLTK library, it uses the tags identified from Penn tree banking.

(Source: Yuzhuo Ren et., 2016)
Applying the CFG rules, it produces the above CFG tree based on a sentence like (e.g. "the dog saw a man in the park") where,
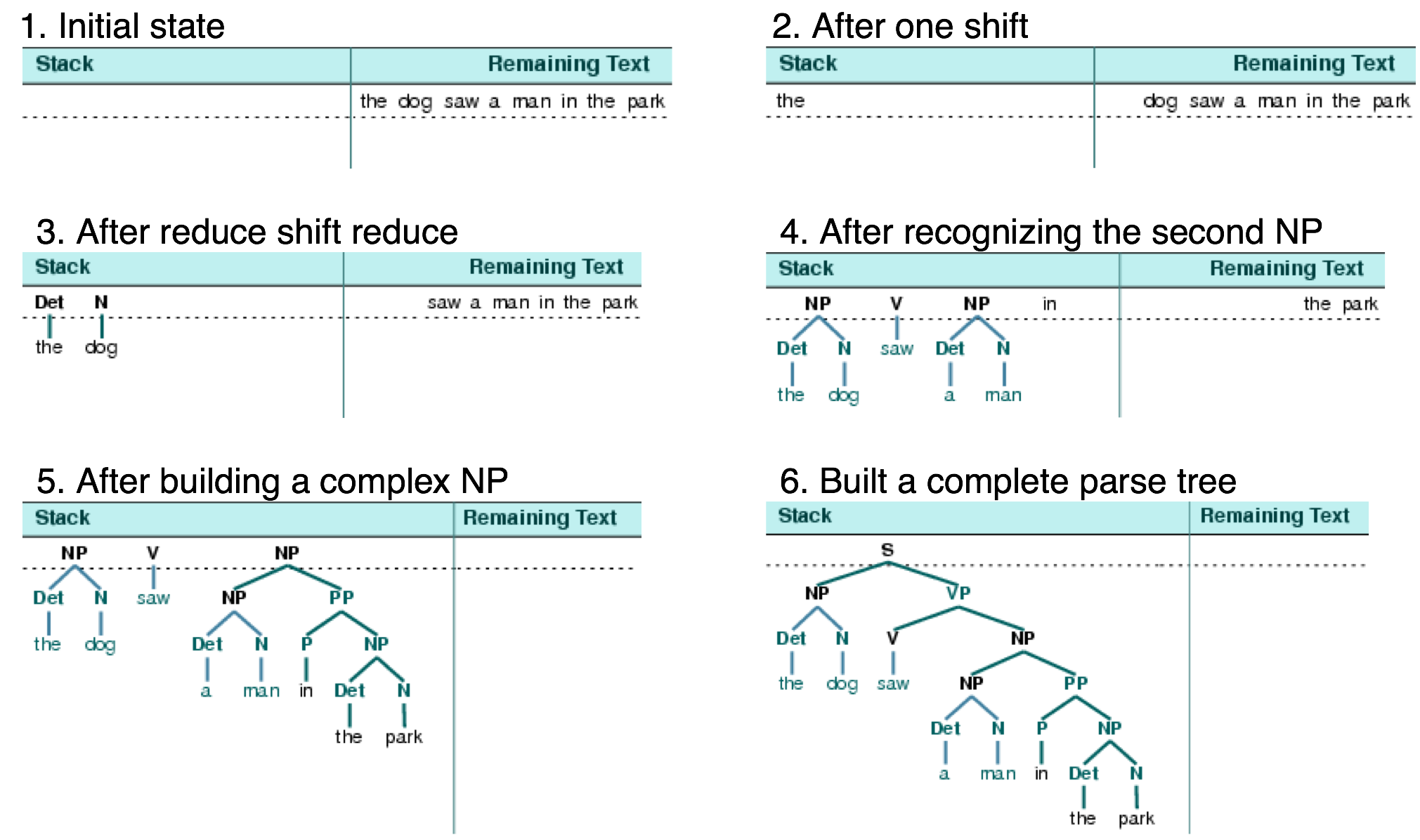
(Source: nltk.org, n.d.)
To read more and understand CFG, read here.
Entities are defined as important chunks of a sentence, such a noun phrase or a verb phrase.
Other examples not covered here is,
- Latent Dirichlet Allocation (LDA) algorithm: Used for Topic Modeling where it identifies the topics present in text corpus (e.g. "health", "doctor", "patient", "hospital")
Examples will be covered in Text Vectorization section,
- N-Grams (Bag-of-Words): Identifying the common words.
- TF-IDF: Extraction using statistical features.
- Word Embedding: Identify similarity between words.
Identifies semantic relationships between 2 or more entities in a text which can be names, places, organizations.
There are 2 types of extraction,
- Entity type: Person, place, organization etc.
- Salience: Importance or centrality of an entity on the scale of
0-1.

(Source: GEORGIOS DRAKOS, 2019)
This technique turns text into vectors (or arrays for example) that can be fed to ML models as features. To do so, it utilises the One Hot Encoding, where for each feature is mapped to a new "column" and if the word/character/phrase exists in the sentence, it is set to 1 (else 0).
For example,
| Document ID | Contents |
|---|---|
| "The sky is blue." | |
| "The sun is bright today." | |
| "The sun in the sky is bright." | |
| "We can see the shining sun, the bright sun." |
After the removal of stop words, it becomes,
| Document ID | Contents |
|---|---|
| "sky blue" | |
| "sun bright today" | |
| "sun sky bright" | |
| "can see shining sun bright sun" |
Text vectorization would represent it as a One-Hot Encoding like,
| Document ID | "sky" | "blue" | "sun" | "bright" | "today" | "can" | "see" | "shining" |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
(Source: Mahidhar Dwarampudi, 2019)
Expanding from the default idea of text vectorization, it displays the word/character/phrase frequencies (aka known as count vectorizer). Imagine a bag full of words, and you picking the word one by one and counting their frequencies. The cons are the ignored order of word/character/phrase (e.g. "No, I have money" becomes {"I": 1, "have": 1, "No": 1, "money": 1}) which removes context or meaning. It tends to be very high dimensional, where in cases if the corpus accounts only 90% of the most common English words that occurs only once, which according to the Oxford dictionary English Corpus, it may result in a vector of at least 7000 dimensions where most of them are zeros (sparse matrix). Regardless, it is simple and can bring quick results for simple problems.
For example, it becomes,
| Document ID | "sky" | "blue" | "sun" | "bright" | "today" | "can" | "see" | "shining" |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 2 | 1 | 0 | 1 | 1 | 1 |
(Source: Tobias Sterbak, 2019) (Source: Dan Jurafsky, 2018)
Again expanding from the default BoW model (which is unigram), it allows for n-gram types of features isntead.
For example,
"This is a great song"
For 2-gram it becomes,
"This is", "is a", "a great", "great song"
For 3-gram it becomes,
"This is a", "a great song".
Examples of such usage is DNA sequencing (e.g. AG, GC, CT, TT, TC, CG, GA).
To obtain the probability of a sentence sequence, the mathematical description of the probability can be presented as such,
Which for the example sentence "its water is so transparent", it becomes,
P["its water is so transparent"] = P["its"] × P["water" | "its"] × P["is" | "its water"] × ...
It is a statistical technique that quantifies the importance of a word/phase/character in a sentence/document based on how often in appears in that sentence/document given a collection of sentences/documents (corpus). The intuition is for example - if a word occurs too frequently in a sentence, it should be more important and relevant than other words (and it ought to have a higher score (TF)), but if a word appears too many times many sentences (or paragraphs), it's proabbly not a meaningful word and hence would be allocated to a lower score (IDF).
For example, after the removal of stop words,
Step 1: Compute TF, to find document-word matrix and then normalize the rows to sum to 1,

(Source: sci2lab, n.d.)
Step 2: Compute IDF, to find the number of documents in which each word occurs, then compute the formula,

(Source: sci2lab, n.d.)
Step 3: Compute the TF-IDF by multiplying the TF and IDF scores,

(Source: sci2lab, n.d.)
Represents words as vector and redefines the high dimensional word features into low dimensional vectors by preserving contextual similarity in the corpus. It is used in Convolutional Neural Networks (CNN) and Recurrent Neural Networks.
Examples are Word2Vec and GloVe.
For an intuition, take for example an personality traits with its range,

(Source: Jay Alammar, 2019)
Then for example person Jay, his personality traits can be plotted like this,
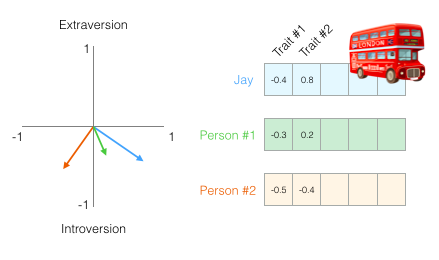
(Source: Jay Alammar, 2019)
Suppose we want to find a person similar to Jay, we can compare via the matrix,
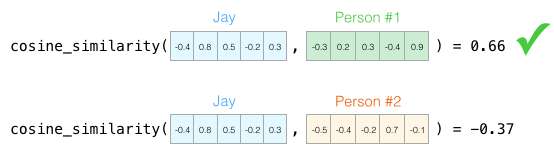
(Source: Jay Alammar, 2019)
The similarity score using the Cosine similarity tells us that Person 1 is the most similar.
So how does this works in words or corpus? Take for example words such as queen, king, man, woman, in a color-coded representation,

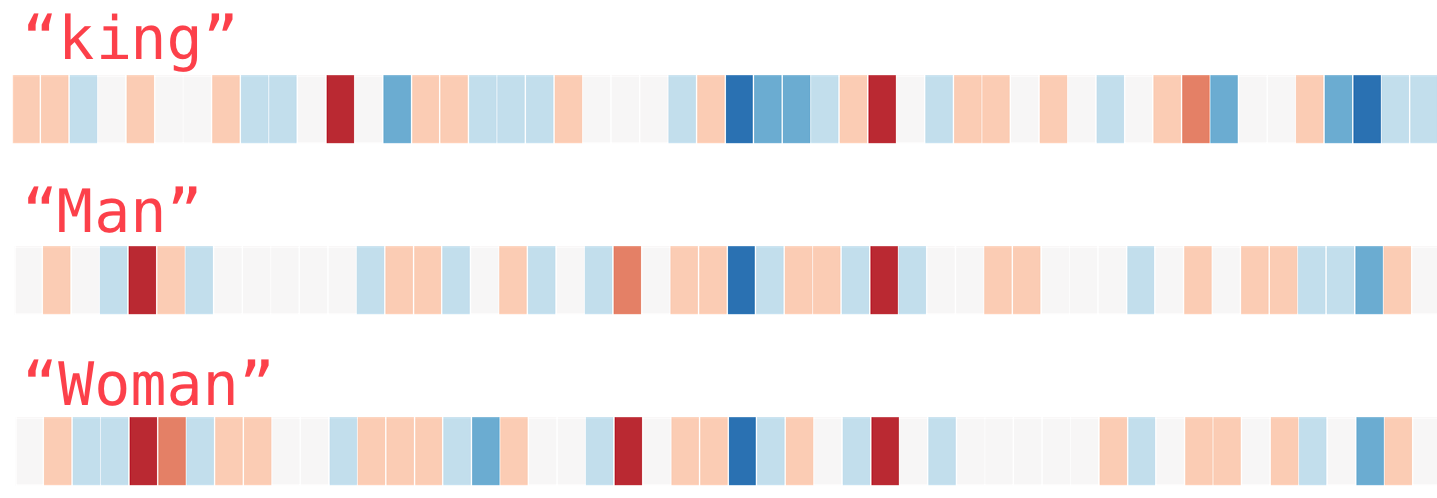
(Source: Jay Alammar, 2019)
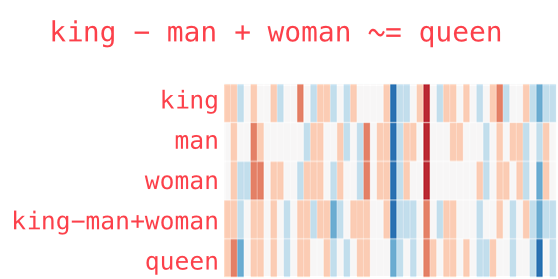
Then to derive "queen", we do the following,
queen = king - man + woman
This is intuitive since a king that isn't a man but a women should relate closely to a queen.
These are the types of key components and analysis carried out.
Ones that have been covered before are:
- Named Entity Extraction (NER)
- Syntactical Analysis (Parsing)
"Semantic" means "related to meaning or logic". It seeks to understand natural language-the way humans communicate based on meaning and context, and get a sense of the implied meaning. It processes the logical structure of the sentences to identify the most relevant elements in the text and understand the topic discussed.
For example, it understands that a tweet is talking about politics/economics even if it doesn't contain the actual words but contains related conceptual words (e.g. election, Democrat, speaker of the house, budget, tax, inflation).
Detects polarity (e.g. positive or negative opinion) in given sentences and try to understand the sentiment behind every sentence.
- Polarity: Object with value from
-1to+1to rate the sentiments of given sentence as negative or positive. - Magnitude: Value of magnitude ranges from
0to∞to signify the weight of assigned polarity.
In a nutshell, focuses on polarity (e.g. positive/negative/neutral) but also the feelings and emotions (e.g. angry/happy/sad) and intentions (e.g. interested/uninterested).
Most complex part of the NLP analysis process, as it deals with outside word knowledge (e.g. external information apart from the existing documents/queries). It focuses re-interprets what was described to understand the actual context of the contents or meaning, and is intended to analyze statements in relation to preceding or succeeding statements (or even overall paragraph) to understand its meaning/context.
For example, in this sentence,
I designed the flower today. But didn’t have the right colors
The commoun noun is "flowers" but the model decodes to what the person is trying to say as "not having the right colors", which requires the computer to look for the earlier statement to get the context right in the sentence.
In summary, it is attempting to find the actual meaning or context rather than the words in the sentence alone (e.g. "What time is it?" could be a question, or a sarcastic reprimanding of a teacher to a student for being late).