Unbundled DB - oleksiyp/oleksiyp.github.io GitHub Wiki
One way of interpreting stream processing is that it turns the database inside out: the commit log or replication log is no longer relegated to being an implementation detail; rather, it is made a first-class citizen of the application’s architecture. We could call this a log-centric architecture, and interestingly, it begins to look somewhat like a giant distributed database:
- You can think of various NoSQL databases, graph databases, time series databases, and full-text search servers as just being different index types. Just like a relational database might let you choose between a B-Tree, an R-Tree and a hash index (for example), your data system might write data to several different data stores in order to efficiently serve different access patterns.
- The same data can easily be loaded into Hadoop, a data warehouse, or analytic database (without complicated ETL processes, because event streams are already analytics friendly) to provide business intelligence.
- The Kafka Streams library and stream processing frameworks such as Samza are scalable implementations of triggers, stored procedures and materialized view maintenance routines.
- Datacenter resource managers such as Mesos or YARN provide scheduling, resource allocation, and recovery from physical machine failures.
- Serialization libraries such as Avro, Protocol Buffers, or Thrift handle the encoding of data on the network and on disk. They also handle schema evolution (allowing the schema to be changed over time without breaking compatibility).
- A log service such as Apache Kafka or Apache BookKeeper is like the database’s commit log and replication log. It provides durability, ordering of writes, and recovery from consumer failures. (In fact, people have already built databases that use Kafka as transaction/replication log).
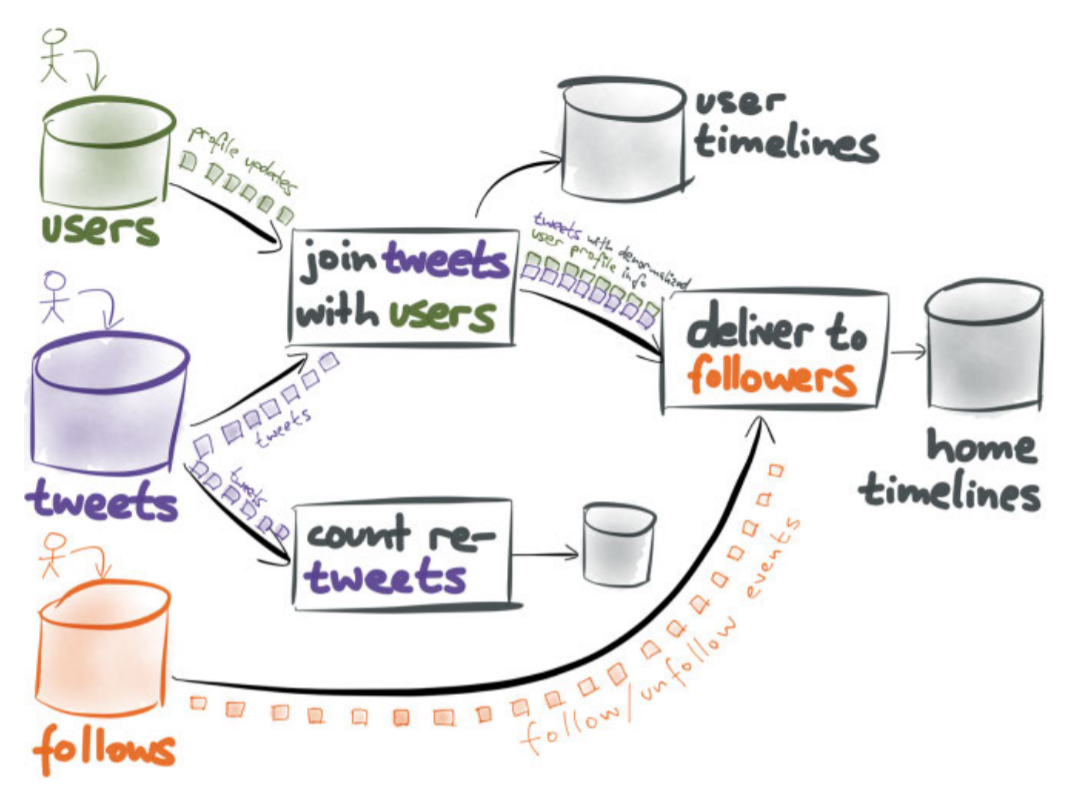
In a traditional database, all of those features are implemented in a single monolithic application. In a log-centric architecture, each feature is provided by a different piece of software. The result looks somewhat like a database, but with its individual components “unbundled”.
In the unbundled approach, each component is a separately developed project, and many of them are open source. Each component is specialized: the log implementation does not try to provide indexes for random-access reads and writes—that service is provided by other components. The log can therefore focus its effort on being a really good log: it does one thing well (cf. Figure 4-3). A similar argument holds for other parts of the system.
The advantage of this approach is that each component can be developed and scaled independently, providing great flexibility and scalability on commodity hardware. It essentially brings the Unix philosophy to databases: specialized tools are composed into an application that provides a complex service.
The downside is that there now many different pieces to learn about, deploy, and operate.