测试的分类 - oceanbei333/leetcode GitHub Wiki
[TOC]
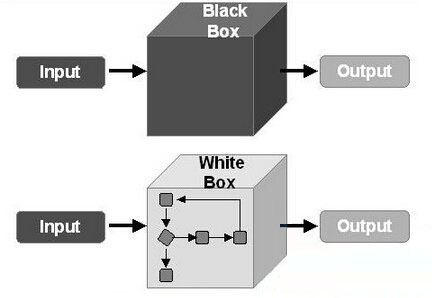
黑盒测试也称 功能测试,它是通过测试来检测每个功能是否都能正常使用。
在测试中,把程序看作一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下,在程序接口进行测试,它只检查程序功能是否按照需求规格说明书的规定正常使用,程序是否能适当地接收输入数据而产生正确的输出信息。黑盒测试着眼于程序外部结构,不考虑内部逻辑结构,主要针对软件界面和软件功能进行测试。
黑盒测试是以用户的角度,从输入数据与输出数据的对应关系出发进行测试的。很明显,如果外部特性本身设计有问题或规格说明的规定有误,用黑盒测试方法是发现不了的。
白盒测试又称结构测试、透明盒测试、逻辑驱动测试或基于代码的测试。白盒测试是一种测试用例设计方法,盒子指的是被测试的软件,白盒指的是盒子是可视的,你清楚盒子内部的东西以及里面是如何运作的。"白盒"法全面了解程序内部逻辑结构、对所有逻辑路径进行测试。
"白盒"法是穷举路径测试。在使用这一方案时,测试者必须检查程序的内部结构,从检查程序的逻辑着手,得出测试数据。贯穿程序的独立路径数是天文数字。
咱们以空调为例来看什么是黑盒测试,什么是白盒测试: 当一台新的空调组装完成,质监部门需要对这台空调的各个功能进行测试,比如开关机是否正常,制冷制热功能是否正常,定时功能是否正常,等等,并将测试的结果一一记录下来,如果有问题,及时反馈给设计部来解决,这就是黑盒测试的范畴。 对于空调的设计师们,他们的测试可能就会更复杂一些,除了对空调的各项功能进行测试之外,还要从空调的内在原理来分析,他们甚至会跟踪空调的内部实现代码,分析空调的各项数据状态来看是否正常运行,而不只是从表面功能来看,这就是白盒测试的范畴。
单元测试:
- 通常是测试单个类,方法的可靠性
- 它的价值在于快速的反馈某一个很小的功能点是否能准确的工作
契约测试:
- 测试接口和接口之间的正确性
- 验证服务层提供的数据是否是消费端所需要的
- 将本来需要在集成测试中体现的问题前移,更早的发现问题
- 更快速的验证消费端和提供端之间交互的基本正确性
接口测试:
接口测试是测试系统组件间接口的一种测试。
主要用于检测外部系统与系统之间以及系统内部各个子系统之间的交互点。
重点测试数据的交换、传递和控制管理过程,以及系统间的相互逻辑依赖关系等等。
集成测试:
- 关注的是各个服务之间交互
- 测试接口连通性和流程的可用性
端到端测试:
- 从用户的角度验证整个功能的准确性和可用性
- 测试的是端到端的流程,会加入用户数据验证功能是否可用
- 不会关注在某一细小的功能点的实现
- 关注的是整个业务流程,产生的业务价值大
单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。
对于单元测试中单元的含义,一般来说,要根据实际情况去判定其具体含义,如C语言中单元指一个函数,Java里单元指一个类,图形化的软件中可以指一个窗口或一个菜单等。总的来说,单元就是人为规定的最小的被测功能模块。
单就单元测试的设计而言,我们期望被测单元在大小上越小越好、在功能上越简单越好,以及在对外部依赖上越少越好,这样能更加方便我们设计可读性好、维护性强的单元测试案例。要达到这点,就需要从功能实现下进行拆分,推荐使用面向对象的设计
- 可以在较早阶段识别软件中的错误
- 反馈迅速: 单元测试通常可以以自动化形式运行,执行速度非常快,可以快速反馈结果,跟持续继承结合起来,形成有效的反馈环
- 重构的有力保障:系统需要大规模重构时,单测可以确保对已有逻辑的兼容,如果单元测试都通过,基本上可以保证重构没有破坏原来代码逻辑的正确性。
- 使更熟悉代码:写单元测试的过程本身就是一个审视代码的过程,可以发现一些设计上的问题(代码设计的不可测试)、代码编写方面的问题(边界条件的处理不当)等。
测试驱动开发
- TDD根据客户需求编写测试用例 对功能的过程和接口都进行了设计,而且这种从使用者角度对代码进行的设计通常更符合后期开发的需求。 因为关注用户反馈,可以及时响应需求变更,同时因为从使用者角度出发的简单设计,也可以更快地适应变化。
- 要求代码符合易测试和测试独立性的要求 将促使我们实现松耦合的设计,并更多地依赖于接口而非具体的类,提高系统的可扩展性和抗变性。 而且TDD明显地缩短了设计决策的反馈循环,使我们几秒或几分钟之内就能获得反馈。
- 将测试工作提到编码之前,并频繁地运行所有测试, 可以尽量地避免和尽早地发现错误,极大地降低了后续测试及修复的成本,提高了代码的质量。 在测试的保护下,不断重构代码,以消除重复设计,优化设计结构,提高了代码的重用性,从而提高了软件产品的质量。
- TDD提供了持续的回归测试 使我们拥有重构的勇气,因为代码的改动导致系统其他部分产生任何异常,测试都会立刻通知我们。 完整的测试会帮助我们持续地跟踪整个系统的状态,因此我们就不需要担心会产生什么不可预知的副作用了。
- TDD所产生的单元测试代码就是最完美的开发者文档, 它们展示了所有的API该如何使用以及是如何运作的,而且它们与工作代码保持同步,永远是最新的。
- TDD可以减轻压力、降低忧虑、提高我们对代码的信心、使我们拥有重构的勇气,这些都是快乐工作的重要前提。
- 快速的提高了开发效率。
测试驱动开发的基本思想就是在开发功能代码之前,先编写测试代码,然后只编写使测试通过的功能代码,从而以测试来驱动整个开发过程的进行。这有助于编写简洁可用和高质量的代码,有很高的灵活性和健壮性,能快速响应变化,并加速开发过程。测试驱动开发的基本过程如下:
- 快速新增一个测试
- 运行所有的测试(有时候只需要运行一个或一部分),发现新增的测试不能通过
- 做一些小小的改动,尽快地让测试程序可运行,为此可以在程序中使用一些不合情理的方法
- 运行所有的测试,并且全部通过
- 重构代码,以消除重复设计,优化设计结构 简单来说,就是不可运行/可运行/重构——这正是测试驱动开发的口号。
给定一个半径,求计算圆的面积
- 环境依赖
pip install pytest
- 确定需求 给定一个半径,半径只能是正整数、正浮点型,不能是字符串、负值、虚数,得到面积
- 新建单元测试文件
# test_circles.py
from circles import circle_area
from math import pi
import pytest
@pytest.mark.parametrize("radius", [-1, '2', 2+3j])
def test_values(radius):
with pytest.raises(TypeError):
circle_area(radius)
@pytest.mark.parametrize("radius", [0, 2, pi])
def test_area(radius):
assert pi*(radius**2) == circle_area(radius)
- 新建circles.py
# circles.py
def circle_area(r):
pass
- 运行单元测试
pytest test_circles.py
- 优化代码
# circles.py
from math import pi
def circle_area(r):
if not isinstance(r, (int, float)):
raise TypeError('radius must be int or float')
if r < 0:
raise TypeError('radius must be positive')
return pi*(r**2)
行为驱动开发
- 引入BDD的软件研发团队通过充分的交流沟通和待实现的产品功能的使用场景举例,来帮助研发团队理解产品特性对业务的价值。 BDD采用更容易测试的软件需求描述方式鼓励需求分析人员、软件开发人员、测试人员密切协同开展软件产品研发工作。
- BDD工具可以帮助把用BDD风格描述的业务需求转换成自动化测试脚本,让软件开发人员同步验证自己编写的代码是否满足业务需求描述的产品特性,并在验证软件产品特性的同时形成软件产品特性文档。从而实现了产品研发文档与软件产品代码编写的同步更新。
- 产品经理(业务人员)通过具体的用户故事使用场景来告诉软件需求分析人员他(她)想要什么样的软件产品。使用软件产品的使用场景来描述软件需求可以尽可能的避免相关人员错误理解软件需求或增加自己的主观想象的需求。
- 软件需求分析人员和研发团队(研发人员、测试人员)一起对产品经理(业务人员)的用户故事进行分析,并梳理出具体的软件产品使用场景举例,这些场景举例使用结构化的关键字自然语言进行描述,例如中文、英文等。
- 研发团队使用BDD工具把用户故事场景文件转化为可执行的自动化测试代码,研发人员运行自动化测试用例来验证开发出来的软件产品是否符合用户故事场景的验收要求。
- 测试人员可以根据自动化测试结果开展手工测试和探索性测试。
- 产品经理(业务人员)可以实时查看软件研发团队的自动化测试结果和BDD工具生成的测试报告,确保软件实现符合产品经理(业务人员)的软件期望。
给定一个半径,求计算圆的面积
- 环境依赖
pip install pytest pytest-bdd
- 确定需求 给定一个半径,半径只能是正整数、正浮点型,不能是字符串、负值、虚数,得到面积
- 新建需求文件 Gherkin
# features/circle.feature
Feature: Circle
Calculate Circle Area
Scenario Outline: Validate Wrong Type Circle Radius
Given a wrong type circle <radius>
Then calculate area with type error
Examples:
| radius|
| -1 |
| "2" |
| "Imaginary number" |
Scenario Outline: Calculate Circle Area
Given a circle <radius>
When calculate circle area
Then got circle area
Examples:
|radius|
| 0 |
| 2 |
| pi |
- 根据需求文件生成单元测试文件
pytest-bdd generate features/circle.feature > test_circles_bdd.py
- 完成单元测试文件
# coding=utf-8
"""Circle feature tests."""
import json
from circles import circle_area
from math import pi
import pytest
from pytest_bdd import (
given,
scenario,
then,
when,
)
@scenario('features/circle.feature', 'Calculate Circle Area')
def test_calculate_circle_area():
"""Calculate Circle Area."""
@scenario('features/circle.feature', 'Validate Wrong Type Circle Radius',)
def test_validate_wrong_type_circle_radius():
"""Validate Wrong Type Circle Radius."""
@given("a wrong type circle <radius>")
@given('a circle <radius>')
def a_circle_radius(radius):
"""a circle <radius>."""
if radius == 'pi':
radius = pi
elif radius == "Imaginary number":
radius = 4+3j
else:
radius = json.loads(radius)
return dict(radius= radius )
@when('calculate circle area')
def calculate_circle_area(a_circle_radius):
"""calculate circle area."""
radius = a_circle_radius['radius']
area = circle_area(radius)
a_circle_radius['area'] = area
@then('got circle area')
def got_circle_area(a_circle_radius):
"""got circle area."""
radius = a_circle_radius['radius']
area = a_circle_radius['area']
assert pi * radius**2 == area
@then("calculate area with type error")
def calculate_area_with_type_error(a_circle_radius):
radius = a_circle_radius['radius']
with pytest.raises(TypeError):
circle_area(a_circle_radius)
- 新建circles.py
# circles.py
def circle_area(r):
pass
- 运行单元测试
py.test test_circles_bdd.py
- 优化代码
# circles.py
from math import pi
def circle_area(r):
if not isinstance(r, (int, float)):
raise TypeError('radius must be int or float')
if r < 0:
raise TypeError('radius must be positive')
return pi*(r**2)
pytest-bdd implements a subset of the Gherkin language to enable automating project requirements testing and to facilitate behavioral driven development.
you can consider it as a normal pytest test function,call other functions and make assertions:
@given('I have an article')
@given('there\'s an article')
def article(author):
return create_test_article(author=author)
If you need your given step to be executed less than once per scenario (for example: once for module, session), you can pass optional scope argument:
@given('there is an article', scope='session')
def article(author):
return create_test_article(author=author)
string (the default) This is the default and can be considered as a null or exact parser. It parses no parameters and matches the step name by equality of strings.
parse (based on: pypi_parse)
Provides a simple parser that replaces regular expressions for step parameters with a readable syntax like {param:Type} . The syntax is inspired by the Python builtin string.format() function.
for cfparse parser
from pytest_bdd import parsers
@given(parsers.cfparse('there are {start:Number} cucumbers', extra_types=dict(Number=int)))
def start_cucumbers(start):
return dict(start=start, eat=0)
for re parser
from pytest_bdd import parsers
@given(parsers.re(r'there are (?P<start>\d+) cucumbers'), converters=dict(start=int))
def start_cucumbers(start):
return dict(start=start, eat=0)
from pytest_bdd import given
@pytest.fixture
def foo():
return "foo"
@given("I have injecting given", target_fixture="foo")
def injecting_given():
return "injected foo"
Feature: Scenario outlines
Scenario Outline: Outlined given, when, thens
Given there are <start> cucumbers
When I eat <eat> cucumbers
Then I should have <left> cucumbers
Examples:
| start | eat | left |
| 12 | 5 | 7 |
Feature: Scenario outlines
Scenario Outline: Outlined given, when, thens
Given there are <start> cucumbers
When I eat <eat> cucumbers
Then I should have <left> cucumbers
Examples: Vertical
| start | 12 | 2 |
| eat | 5 | 1 |
| left | 7 | 1 |
@login @backend
Feature: Login
@successful
Scenario: Successful login
py.test -m "backend and login and successful"
It's often the case that to cover certain feature, you'll need multiple scenarios.
Feature: Multiple site support
Background:
Given a global administrator named "Greg"
And a blog named "Greg's anti-tax rants"
And a customer named "Wilson"
And a blog named "Expensive Therapy" owned by "Wilson"
Scenario: Wilson posts to his own blog
Given I am logged in as Wilson
When I try to post to "Expensive Therapy"
Then I should see "Your article was published."
Scenario: Greg posts to a client's blog
Given I am logged in as Greg
When I try to post to "Expensive Therapy"
Then I should see "Your article was published."
@pytest.fixture
def article():
"""Test article."""
return Article()
Then this fixture can be reused with other names using given():
given('I have beautiful article', fixture='article')
conftest.py:
pytest.ini
py.test --cucumberjson=<path to json report>
pytest-bdd generate <feature file name> .. <feature file nameN>
先看看两者的相同点吧,非常明确的是,mock和stub都可以用来对系统(或者将粒度放小为模块,单元)进行隔离。 在测试,尤其是单元测试中,我们通常关注的是主要测试对象的功能和行为,对于主要测试对象涉及到的次要对象尤其是一些依赖,我们仅仅关注主要测试对象和次要测试对象的交互,比如是否调用,何时调用,调用的参数,调用的次数和顺序等,以及返回的结果或发生的异常。但次要对象是如何执行这次调用的具体细节,我们并不关注,因此常见的技巧就是用mock对象或者stub对象来替代真实的次要对象,模拟真实场景来进行对主要测试对象的测试工作。 因此从实现上看,mock和stub都是通过创建自己的对象来替代次要测试对象,然后按照测试的需要控制这个对象的行为。
1) 类实现的方式 从类的实现方式上看,stub有一个显式的类实现,哪怕简单到只有一个简单的return语句。pytest的fixture就是stub
@pytest.fixture
def data():
return "I am a data"
而mock则不同,mock的实现类通常是有mock的工具包来隐式实现
mock = Mock(return_value="I am a data")
mock()
assert mock.called
2)测试逻辑的可读性 在形式上,mock通常是在测试代码中直接mock类和定义mock方法的行为,测试代码和mock的代码通常是放在一起的,因此测试代码的逻辑也容易从测试案例的代码上看出来。 而stub,我们无法直接从代码中看出对依赖的预期。因此当测试逻辑复杂,stub数量多并且某些stub需要传入一些标记比如true,false之类的来制定不同的行为时,测试逻辑的可读性就会下降。
3)可复用性 Mock通常很少考虑复用,每个mock对象通过都是遵循”just enough”原则,一般只适用于当前测试方法。因此每个测试方法都必须实现自己的mock逻辑,当然在同一个测试类中还是可以有一些简单的初始化逻辑可以复用。 stub则通常比较方便复用,pytest的fixture机制就是最大化的代码复用
4)设计和使用 接着我们从mock和stub的设计和使用上来比较两者,这里需要引入两个概念:interaction-based和state-based。
总结来说,stub是state-based,关注的是输入和输出。mock是interaction-based,关注的是交互过程。
5)expectiation/期望 这个才是mock和stub的最重要的区别:expectiation/期望。 对于mock来说,expectiation是重中之重:我们期待方法有没有被调用,期待适当的参数,期待调用的次数,甚至期待多个mock之间的调用顺序。所有的一切期待都是事先准备好,在测试过程中和测试结束后验证是否和预期的一致。
而对于stub,通常都不会关注期望,就像上面给出的UserDaoStub的例子,没有任何代码来帮助判断这个stub类是否被调用。虽然理论上某些stub实现也可以通过自己编码的方式增加对expectiation的内容,比如增加一个计数器,每次调用+1之类,但是实际上极少这样做。
6)测试与实现的耦合
mock代码和测试代码完全耦合在一起
- 真实对象的行为具有不确定性。
- 真实对象难以创建。
- 真实对象的行为难以模拟(例如网络错误)。
- 真实对象运行效率很低。
- 真实对象有或者是UI。
- 测试需要得到某个对象列表,但是真实对象必须在某种环境下才能提供。
- 真实对象还没实现。
比如 Django项目中,如果被测试的主功能,不依赖数据库,那么不要使用@pytest.mark.django_db,这样会大大降低单元测试的运行速度(大约20s),功能中的涉及到数据库的,使用mock代替
被测试的功能的依赖比较多,比较难以通过mock来实现
被测试的功能可能变化,考虑到测试代码应对变化的能力
测试代码的可复用性,比如BDD中
BDD是一种典型的使用stub的场景,通过fixture和step的复用,相当多的代码也可以复用
但是BDD也有很多缺点,BDD只是针对功能点的测试,相较于单元测试,其颗粒度还是太粗,而且因为是基于stub,所以导致出问题之后,定位问题非常困难
所以BDD不能代替单元测试,应该是单元测试先行,然后再通过BDD保证功能点的实现
4.0.0版本以后的pytest-bdd,去除了given作为fixture机制,并且gvien中也不可以使用fixture中yield机制来做数据销毁。
如果继续需要使用given作为fixture,需要增加target_fxiture关键字
而数据销毁,只能通过pytest的fixture来实现了
开发的前期,对于小的功能的测试,以测试时间快,实现简单快优先,使用mock
开发的后期,对于大的功能的测试,使用stub
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,每个服务运行在其独立的进程中,服务间采用轻量级通信机制互相沟通(通常是基于HTTP协议的RESTful API)。每个服务都围绕着具体的业务进行构建,并且能够被独立部署到生产环境、预生产环境。
- 每个服务可以独立开发
- 处理的单元粒度更细
- 单个服务支持独立部署和发布
- 更有利于业务的扩展
独立开发导致技术上的分离,HTTP通信的机制增加了问题诊断的复杂度,对系统的功能、性能和安全方面的质量保障带来了很大的挑战。
在设计和进行单元测试的时候,根据对被测单元外部依赖的处理方式的不同,单元测试常被分成关联型的单元测试和独立型的单元测试
关联型的单元测试就是将被测单元和它相关的外部依赖(其它的单元)作为一个整体,进行黑盒测试
它的优点是你不需要对复杂的依赖关系进行任何处理,通过测试可以得到关联单元之间真实的状态转换带来的被测单元的行为表现
而缺点就是当发现失效时,难于定位缺陷是来自被测单元还是外部依赖。
独立型的单元测试则是将被测单元之外的全部外部依赖使用测试替身替换,保证发现的任何失效都是来自被测单元的缺陷
独立型的单元测试因为使用了测试替身,所以它既可以测试被测单元作为服务或数据生产者的行为正确性,也可以检查被测单元作为服务或数据使用者时是否正确调用和解析了来自外部依赖的数据源。
当然,在提供这些优势的同时,独立型的单元测试的缺点就是需要创建和维护测试替身,有时甚至是很复杂的测试替身。
-
如果代码通常都是进行各种状态转换和数据计算的复杂功能区,它和外部依赖的部分,都是数据强相关,对于这样的功能代码,使用测试替身的代价太高。使用关联型的单元测试;
-
如果代码主要的功能是数据的传输和预处理,与之交互的数据主要都是来自外部依赖的单元,比如数据库和外部服务,使用独立型的单元测试
对这部分单元测试的目的是验证获取的数据可以被正确的传输和解析,而不是测试和外部的交互过程,于是我们使用测试替身来模拟外部依赖的数据源可以得到更高的测试效率,另外,使用测试替身还可以帮助我们触发各种异常处理的测试场景,比如数据库返回异常的数值,这在使用外部依赖的时候是很难真实的重复测试的。
-
以上都是针对与其他微服务相关的代码,对于关联度不大的代码,还是遵照之前单元测试中论述的的原则
契约测试又称之为消费者驱动的契约测试(Consumer-Driven Contracts,简称CDC),根据消费者驱动契约 ,我们可以将服务分为消费者端和生产者端,而消费者驱动的契约测试的核心思想在于是从消费者业务实现的角度出发,由消费者自己会定义需要的数据格式以及交互细节,并驱动生成一份契约文件。然后生产者根据契约文件来实现自己的逻辑,并在持续集成环境中持续验证。
- 可以使得消费端和提供端之间测试解耦,不再需要客户端和服务端联调才能发现问题
- 完全由消费者驱动的方式,消费者需要什么数据,服务端就给什么样的数据,数据契约也是由消费者来定的
- 测试前移,在集成测试以前进行,越早的发现问题,保证后续测试的完整性
- 通过契约测试,团队能以一种离线的方式(不需要消费者、提供者同时在线),通过契约作为中间的标准,验证提供者提供的内容是否满足消费者的期望。
一般契约测试是在单元测试之后,集成测试之前要进行的,首先在保证各自功能正确的前提下测试消费者和提供者的契约是否相匹配,然后再进一步的测试功能的完备性和整个业务流的正确性。

- 快速反馈
- 契约测试应当聚焦对于接口规则的验证,能够易于编写,快速运行,最简验证。所以通常采用测试替身(Test Double)来代替集成组件加快运行速度(速度与单元测试相当)。
- 测试运行时使消费者与提供者解耦(分别运行测试)
- 对于接口的功能验证,应当由接口集成测试来保证。
- 对于系统间的协作验证,应当由系统间集成测试,或端到端测试来保证。
- 消费者驱动设计优于提供者驱动设计
- 符合需求拉动和简单设计思想,减少冗余设计
因为是消费者最终消费数据,所以消费者最清楚自己需要的是什么数据,所以需要消费制定契约
当某个provider正常上线后,某个consumer需要消费这个provider的服务,那么应该由consumer来提出期望建立它们之间的契约测试。因为,契约测试,形式上,虽然测试的是provider,但,价值上,保证的却是consumer的业务。
需要注意的是,”消费者驱动”述及的对象是契约,而不是契约测试,契约双方都需要自主进行测试
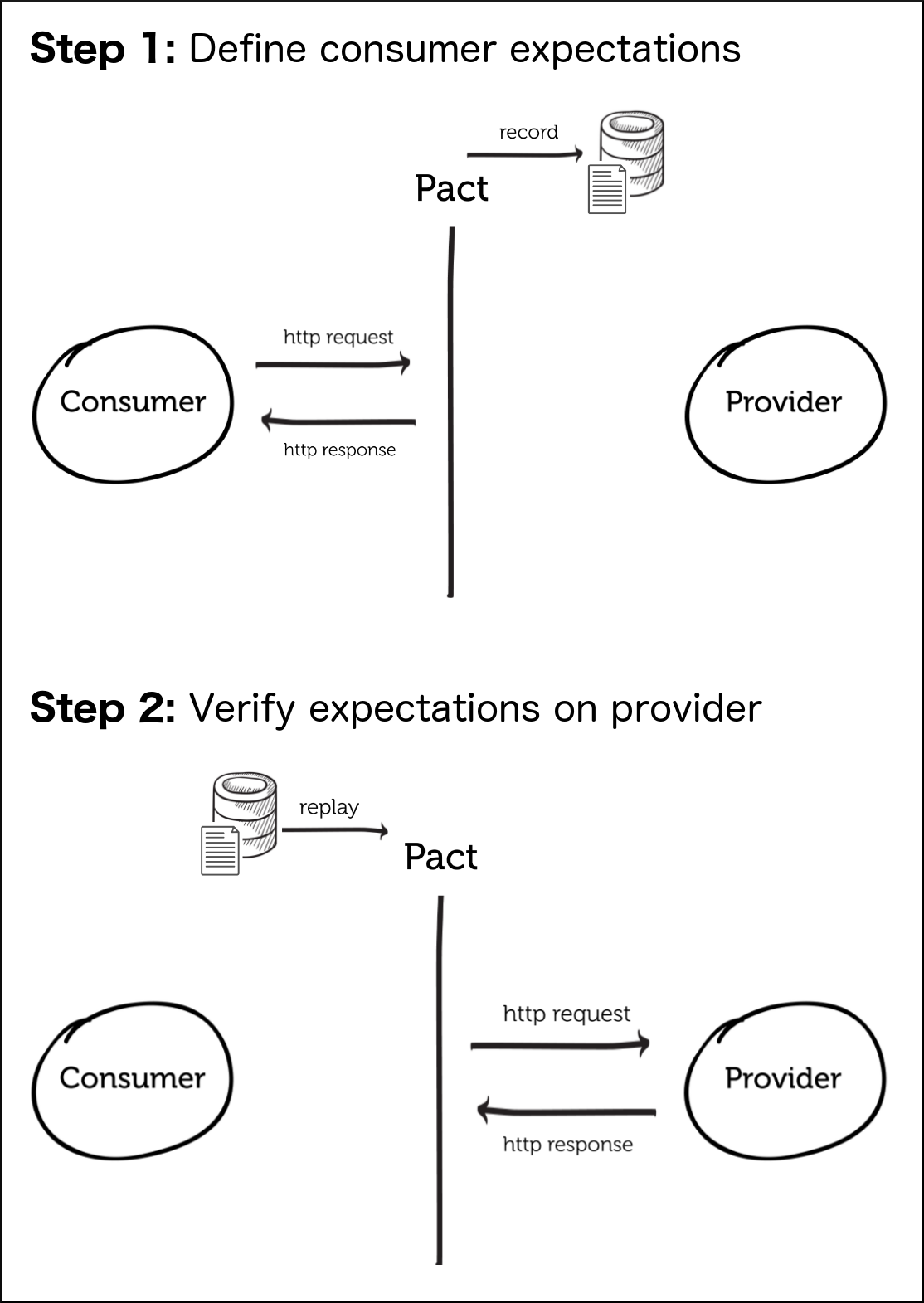
Pact提供对消费者驱动的契约测试的支持。
- 在消费者项目中编写测试,编写对提供者的响应(response body, status code等)的期望
- 在测试运行时,模拟的服务将返回所期望的响应。请求和所期望的响应将会被写入到一个“pact”文件中。
- pact文件中的请求随后在提供者上进行重放,并检查实际响应以确保其与所期望响应相匹配。
python -m microservice.provider.api_server
生产者在8080端口对外提供服务器
消费者 miku
python -m microservice.consumer.consumer_miku
消费者消费生产者的服务器,并在8081端口对外提供服务
消费者 nanoha
python -m microservice.consumer.consumer_nanoha
消费者消费生产者的服务器,并在8082端口对外提供服务
在消费者的项目中编写测试
其实,就是为了实际产生一个消费者对生产者的请求
- 环境准备
- 定义生成的请求的客户端
- 定义契约,包括对消费者请求的期望和对生产者相应的期望
这里虽然定义是一个测试,但是基于契约测试的目的性,这里不做过多的功能测试
如果只是为了生成契约文件,并不要求添加测试代码的。
pytest microservice/contract_test/test_contract_miku.py
pytest microservice/contract_test/test_contract_nanoha.py
- 启动生产者
- 测试生产者
pact-verifier --provider-base-url=http://localhost:8080 --pact-url=miku-provider.json
某些测试是要基于生产者的状态的,需要生产者提前准备一些数据
- 生产者端定义准备数据的接口
- 启动生产者
- 测试生产者
pact-verifier --provider-base-url=http://localhost:8080 --pact-url=nanoha-provider.json --provider-states-setup-url=http://localhost:8080/setup
- 功能测试是确保提供者在某个请求下执行正确的动作。这些测试代码属于提供者团队,不应该由消费者团队完成。
- 而契约测试的目的是确保消费者团队和提供者团队对请求和响应达成共识。
- Pact测试应该关注于:
- 检查消费者如何构建请求以及处理响应时所暴露出的bug
- 检查提供者的行为,消除理解上的偏差
- Pact测试不应该关注于:
- 提供者内部所暴露的bug(尽管有可能作为副产品产生)
关于Pact测试中测试范畴的取舍,经验法则是:如果在当前场景下不包括这部分测试内容,会引起消费者的什么bug,或者关于提供者的行为会出现怎样的理解偏差。如果答案是不会有问题,那么就不需要囊括到Pact测试的范畴中来。
- 所谓隔离的测试(如单元测试),是指只对负责从消费者发送HTTP请求的类进行测试,而不是对整个消费者代码库进行完整的集成测试。
- 对于消费者代码库中任何类型的功能测试或集成测试,应该谨慎对待。
为什么?
- 如果以传统的集成测试思维使用Pact,会将自己陷入泥潭。你的消费者测试将非常脆弱,因为需要使用Pact检查每个响应路径,JSON节点,查询参数和请求头。同时,你还会发现,提供者端的待验证用例数量将会呈笛卡儿乘积式地爆炸增长。这将大大增加提供者运行验证的时间,却难以有效提升测试覆盖率。
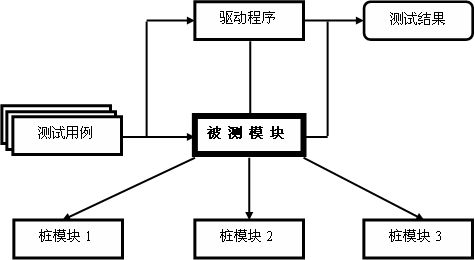
集成测试,也叫组装测试或联合测试。在单元测试的基础上,将所有模块按照设计要求(如根据结构图)组装成为子系统或系统,进行集成测试。 实践表明,一些模块虽然能够单独地工作,但并不能保证连接起来也能正常的工作。一些局部反映不出来的问题,在全局上很可能暴露出来。
我们公司目前没有单独针对整个服务的集成测试,部分集成测试和其他测试混在一起,建议可以搭建一个稳定的环境,用于集成测试
单元测试的颗粒度太小,代码工作量会比较大,而且应对变化的能力比较差,对开发人员造成比较大的负担
BDD的颗粒度太大,可读性太差
由于大部分的功能都是以接口的形式对外发布的,所以基于接口写测试是一个比较好的颗粒度
在需求不进行大的变动,只是单纯的实现的重构或者重新,基于接口的测试大多不需要进行大的变动
对于旧的项目,基于接口写测试,不用深入代码实现中,不用过度关心业务逻辑,快速的完成测试
基于接口的测试,也便于code review,了解测试是否覆盖到功能点