architecture - nsip/n3 GitHub Wiki
n3 is a toolkit that bundles together several pieces of functionality, which we believe make it useful in the K-12 education space:
-
Ingest data in a wide range of formats and schemas, without imposing a single schema and format on data
-
Decompose different ingested data into a single granular representation — so that data from different sources can be crosswalked and queried
-
Realise encryption and privacy throughout data transfer, at the most granular level possible
-
Allow data to be transmitted peer-to-peer rather than via a centralised server, allowing for eventual consistency and resynchronisation of offline data sources
The services offered by the toolkit can help address several ongoing problems in K-12 education, including:
-
Security and Privacy
-
Data interoperability between different schemas and formats
-
Data infrastructure constraints
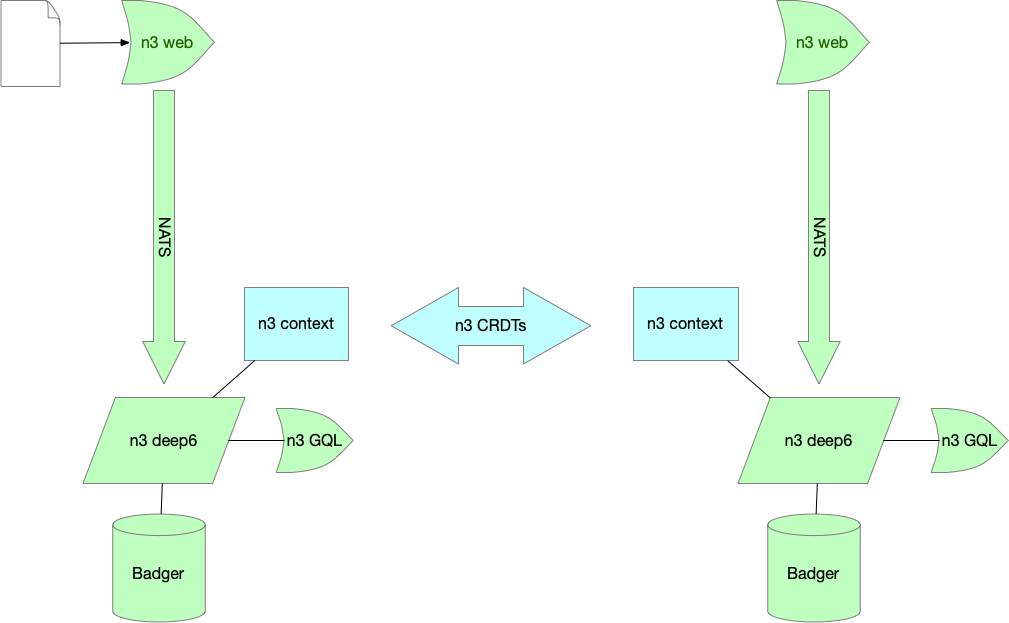
The toolkit is structured as follows:
-
Data is read in by a front-end web service, in their native formats and schemas (https://github.com/nsip/n3-web)
-
Data is streamed from the read service to the backend using the NATS streaming message broker
-
Data is decomposed into triples, and is stored in a hexastore (https://github.com/nsip/n3-deep6)
-
A hexastore is a retrieval-optimised index of triples: https://cs.uwaterloo.ca/~gweddell/cs848/presentations/MSabriCS848Fall2013.pdf . All six permutations of a triple are indexed, and can be retrieved by prefix, so that all triples matching any permutation of an incomplete triple can be retrieved quickly. This allows efficient queries on the decomposed triples.
-
The triples for each object represent its surface structure, rather than engaging in deep semantic analysis: the subject is a unique identifier for the object, the object is one of the values contained in the object, and the predicate captures the position of the value within the object (e.g. as a JSON Path or XPath).
-
The way each data format should be broken down into triples is set up in config files for the hexastore, including identifying which value should serve as unique identifier for the object.
-
The predicate breakdown of the objects is meant to serve as a graph database, allowing traversal of objects related across different schemas. The breakdown of objects tries to build that graph database automatically: if two objects with different schemas have a value in common, a link will be made between the two nodes. (This allows traversal between e.g. a SIF record and a OneRoster object containing the same student name.)
-
There is of course clear potential for overgeneration of links, and any associated query of the graph database will need to be set up to ignore spurious connections.
-
-
The hexastore has a custom query language for triples, that exploits the graph database links automatically built up
-
-
Hexastore triples are stored in the Badger key-value store
-
Aside from the internal graph query language in n3-deep6, the data in the hexastore is also exposed to external query via GraphQL (https://github.com/nsip/n3-gql).
-
The GraphQL schema for the data in the hexastore is built dynamically from the triples data as they are being ingested. It uses a configured object classifier to differentiate the different formats that data have been ingested into.
-
-
The hexastore can be queried via GraphQL in a server-client configuration, but it can also operate as a peer-to-peer network (https://github.com/nsip/n3-crdt).
-
The network set up by N3 is a conflict-free replicated data type (CRDT), set up so that data arriving out of sequence to different nodes will still end up with the different nodes consistent with each other.
-
That consistency relies on the data exchanged between nodes being atomic (triples), and with incremental time counters on data, rather than relying on an absolute timestamps. For more on the theory behind N3’s distributed networking, see https://github.com/nsip/nias3/wiki/Achieving-consistency-for-distributed-data
-
Because of the guarantees around data synchronisation, the peer-to-peer network will cope with individual nodes going offline for extended periods.
-
All data transfers between nodes are encrypted.
-
-
Authorisation across the N3 network is handled by assigning individual data to different contexts, each with its own authorisation settings (https://github.com/nsip/n3-context)
-
The authorisation of contexts can be quite granular, applying to individual triples
-
The following summarises the architecture described above: