Weakly Supervised Learning - newlife-js/Wiki GitHub Wiki
by 연세대학교 최종현 교수님
Weakly Supervised Learning
적은 수의 데이터로 학습
Inductive biases
학습에 없었던 데이터에 대한 추론을 잘하기 위해 추가한 가정, regularizer와 같은 bias를 사용
fitting보다는 generalization을 위해 bias를 추가
■ bias-variance tradeoff
data에는 noise가 존재하기 때문에 high-complex 모델을 사용하면 overfit될 수 있음
tarining error: model이 복잡할수록 작아짐, 데이터가 많을수록 커짐
true error(prediction error): model이 복잡해질수록 작아지다가 어느 순간 다시 커짐, 데이터가 많을수록 작아짐


- Neural network architectures
CNN(공간 관계), RNN(시간 관계), GNN - Hand-crafted regularizers
L2, L1, Dropout, Data augmentation, Early stopping 등 - Structure of data(inter/intra-sample relationships)
한 데이터 내부의 part간의 관계, gemoetric relationship 등을 cue로 사용
Unlabeled data
- Semi-supervised learning
비슷한 시각적인 정보(색깔, 줄무늬 등)를 가진 unlabeled data를 추가

- Active learning
labelling이 필요한 데이터 중 정보량이 많은 데이터를 선택
Continual Learning
Lifelong learning
NELL(Never Ending Language Learner)
매일매일 추가되는 web의 knowledge base(ontology) 학습
NEIL(Never Ending Image Learning)
Web image understanding problem
시간이 흐르면서 추가되는 이미지들을 classification/detection 할 수 있도록
Class incremental learning
시간이 흐르면서 판별해야 하는 class가 늘어남

※ Catastrophic forgetting: 새로운 task에 대한 학습을 하면 이전 학습한 내용을 잊어버리는 것
GDumb
Memory-based method

- Greedy Balancing Sampler: data를 sampling해서 메모리에 저장(메모리가 다 차 있으면, 가장 많은 비율을 차지하는 class의 데이터를 랜덤으로 삭제)
- Dumb Learner: sampling된 데이터로 학습

Data Subsets Set-up
- Disjoint: task별로 해당 task에 대한 데이터만 training에 포함

- Blurry: 첫 task부터 모든 class가 training에 포함

Sampling 방법
- Greedy balance sampler: 클래스별로 data 수가 같도록 sampling
- Cumulative likelihood: class의 knowledge를 best preserving하도록 likelihood라는 metric을 사용
likelihood가 크면 전형적인 sample, 작으면 outlier -> likelihood가 작은 것부터 큰 것까지 모두 포함되도록 sampling

- Classification uncertainty under transformations: sample에 transform을 가해서 sample에 추가

- CLIB: sample-wise importance가 큰 sample들로 dataset 구성

Efficient AI
다양한 기기(스마트폰, TV, AI스피커 등)에 AI를 적용하기 위해 model을 작게 만들 필요가 있음
model의 parameter를 줄이거나, precision을 낮춤
Weight Quantization
NN parameter가 full precision일 필요가 있을까?
single precision이 double precision보다 더 빠르고 때때로 accuracy도 높음
weight를 discrete values로 clustering
Extreme Quantization
weight를 Binarization(Binary Neural Network)

-
ResNet block 구조를 변경해서 성능 올림
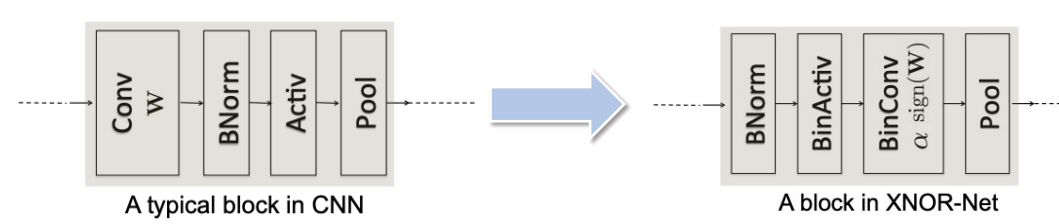
-
gradient vanishing을 해결하기 위해 cell template을 변경(residual connection)

-
zeroise layer 도입
binary conv는 floating point conv에 비해 값이 너무 큰 경우가 있음

output이 작은 conv는 그냥 0으로 만들어 버림
Multi-modal visual recognition
Challenges
- representation: 여러 modality을 어떻게 같이 representation할 건지
- alignment: modality 간의 관계를 어떻게 나타낼 건지
- fusion: 여러 modality의 정보를 어떻게 합칠 건지
- translation: 한 modality의 정보를 어떻게 변환하여 다른 modality에 전달할 건지
Natural Language Video Localization(NLVL)
query의 내용을 담은 video 장면을 찾는 것
