Semantic Segmentation - newlife-js/Wiki GitHub Wiki
by KAIST 홍승훈 교수님
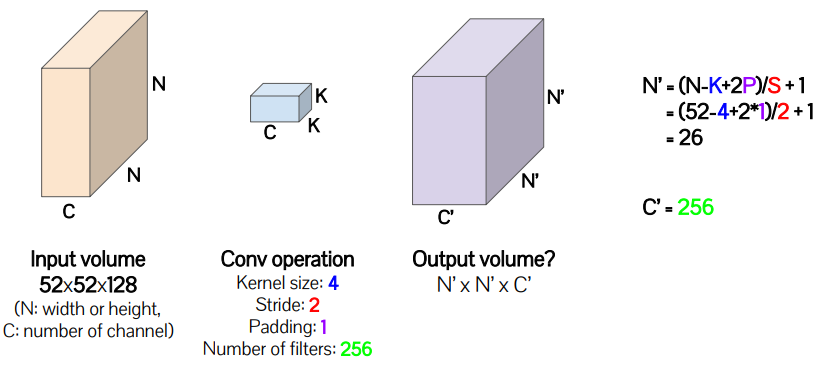
Convolution Recap
Semantic Segmentation
Recognition and pixel-level localization of visual concepts on an image(pixel 단위의 classification)

※ pixel별로 class labeling을 해야 하기 때문에 class^#pixel 만큼의 search space가 큼
Early approches
Region-based proposal + classification
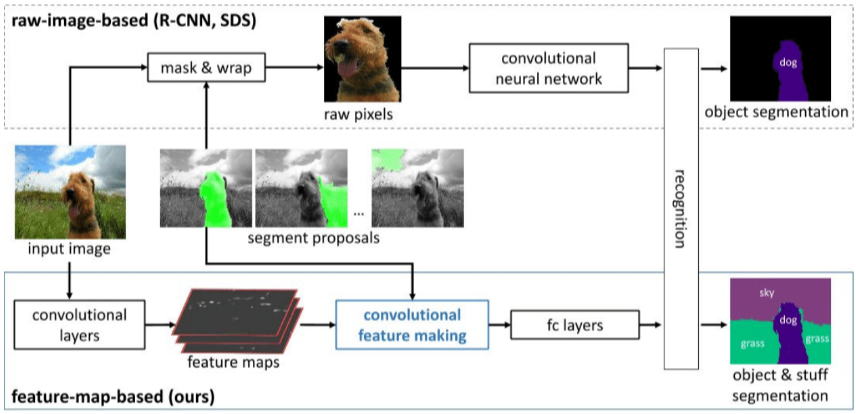
한계: region-proposal accuracy에 의해 성능이 결정, classifier / feature extractor 모델이 개별적으로 존재
-> end-to-end, pixel-level network 도입
Fully Convolutional Network(FCN)
기존 ConvNet: Convolutional + fully connected layers
Conv는 input size에 상관없이 가능하나, fc layer는 fixed size 필요
-> fc layer를 Conv 연산(1x1xC)으로 해석(FCN)
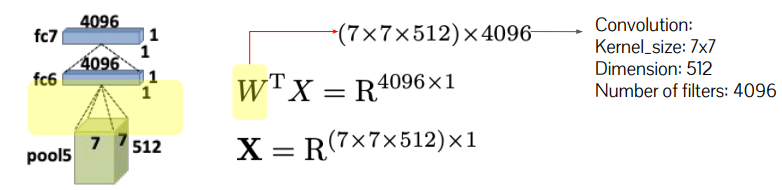
FCN을 sliding window로 순회하면서, pixel별 Score Map을 생성
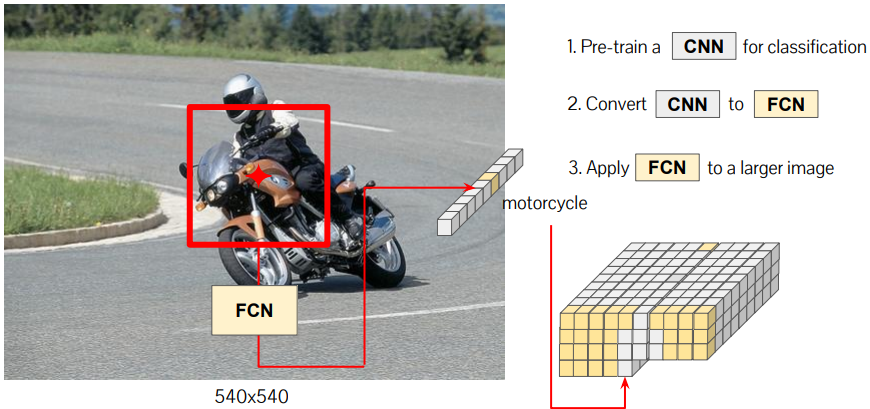 ※ Low resolution / fixed receptive field 문제가 있음(10x10 score map)
※ Low resolution / fixed receptive field 문제가 있음(10x10 score map)
Receptive Field(Field-of-View:FoV)
convolution된 하나의 pixel의 연산에 사용된 input pixel의 범위
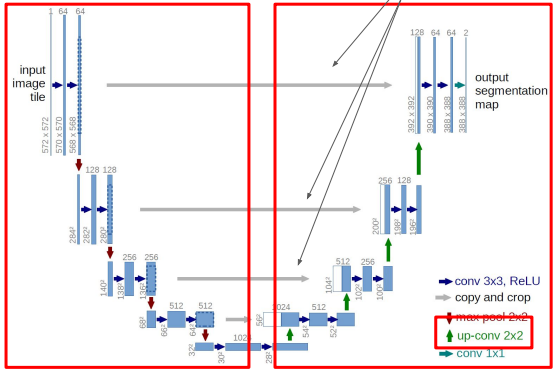
Encoder & Decoder Network
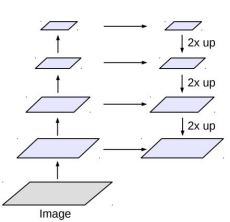
Deconvolution
Reconstruct the information from the representation(upsampling)
Unpooling
image resolution을 높이기 위해 어떤 pixel로부터 pooling이 된 것인지를 예측하여 해당 pixel로 할당해줌
unpooling 후 빈 공간을 deconvolution으로 reconstruct
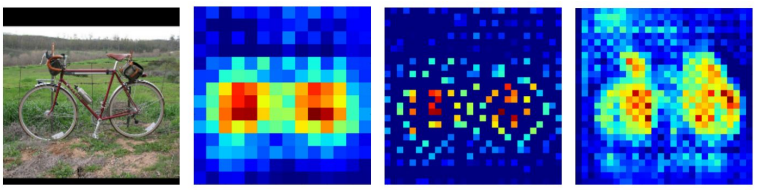
Skip Connection
Decoder가 Encoder 중간 과정을 참고(input feature를 concat)하여 input의 detail을 전달 받음
※ Unet
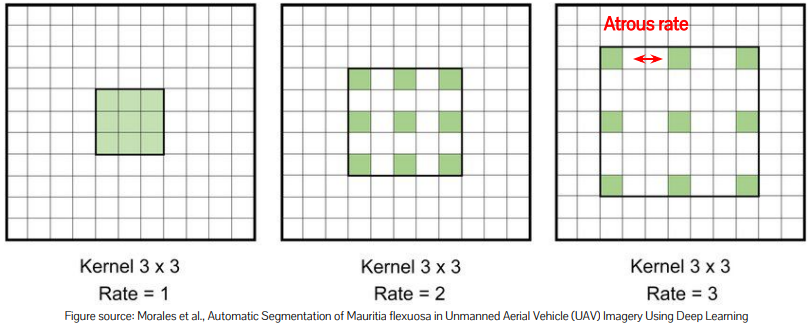
Atrous Convolution
FoV가 너무 작으면 모호성이 커짐(바퀴만 보이면 차인지 오토바이인지 모름)
kernel size를 키우면 parameter가 너무 많아짐
-> kernel size는 키우지만, 커널의 일부 pixel만 사용
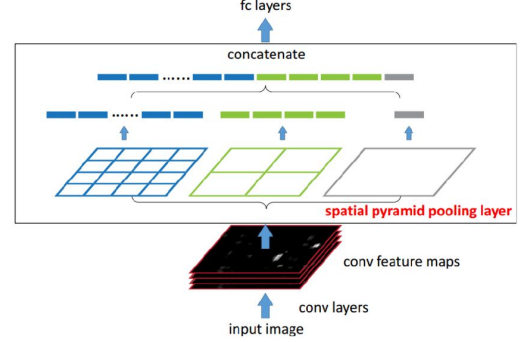
Spatial Pyramid Pooling
Multi-scale Fov로 pooling한 뒤에 concatenate
Pose Estimation
Identifying position of joints(2d, 3d)
※ 어려움: pose의 variation이 아주 다양, occlusion, 사람마다 몸이 다름
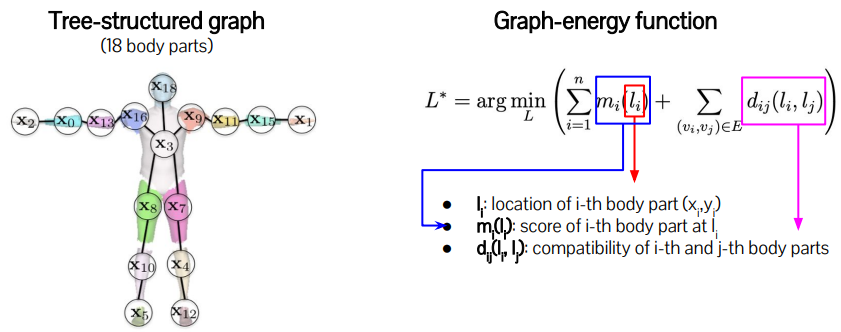
Pictorial Structure(Deformable Part Model)
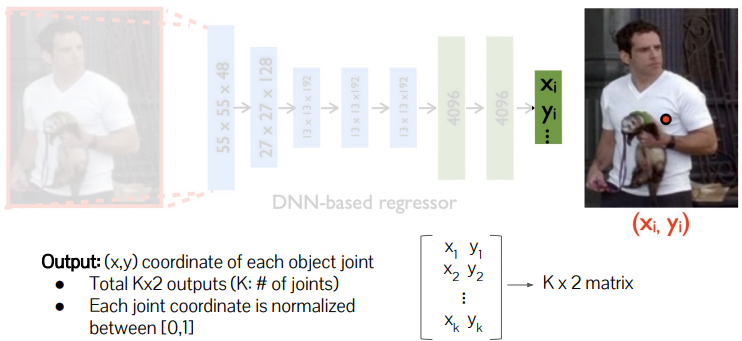
DeepPose
CNN 사용해서 human joint를 예측(pixel -> joint 개수(K) * 2(x,y))
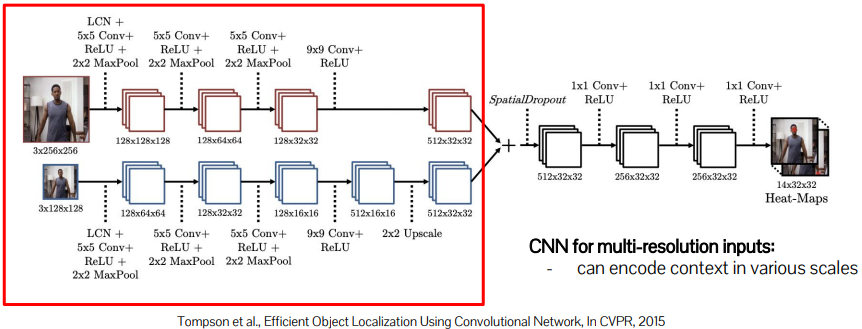
Multi-resolution Heat Map Regressor
x,y를 예측하는 대신 joint의 heat map(score map, KxHxW)을 예측
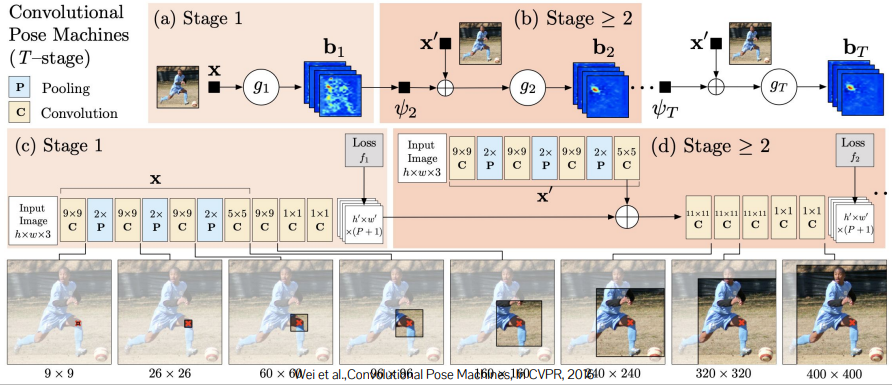
Convolutional Pose Machine
※ local evidence(각 관절만 찾기)는 모호성이 큼(개별적으로는 detect하기 어려운 관절들이 존재)
-> large context: 좀 더 확실한 다른 관절을 참조해서 모호성을 줄일 수 있음
-> FoV를 키워서 large context를 incorporate할 수 있음
Iterative refinement of part localization by increasing receptive field
작은 FoV로 확실한 관절을 찾고 FoV를 키워가면서 모호한 관절들을 찾아감
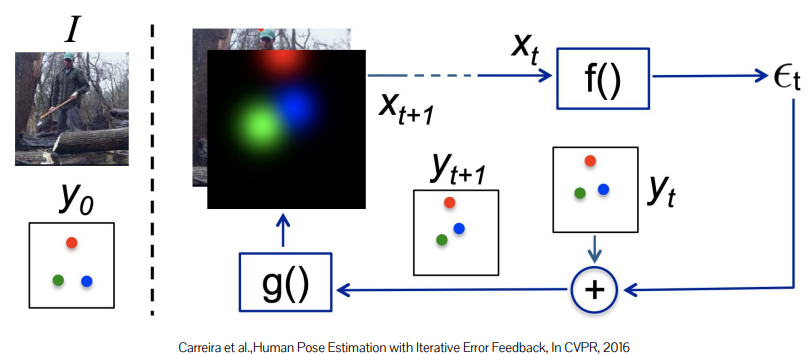
Iterative update of prediction
기본 pose로부터 error feedback을 통해 body part를 옮기는(refinement) 방법을 학습
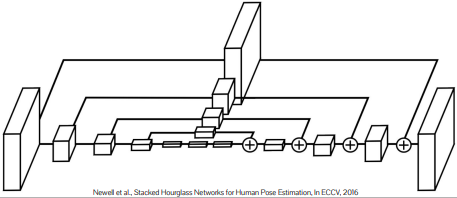
Stacked Hourglass
combining global and local cues
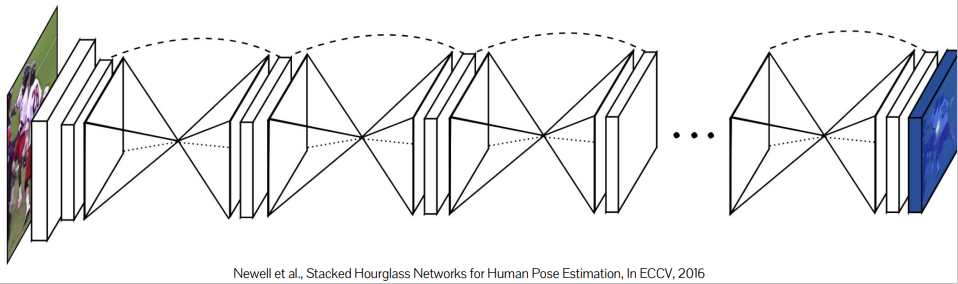 각 layer는 encoder-decoder(Unet) 구조
각 layer는 encoder-decoder(Unet) 구조
Generative Models
True data distribution을 따르는 output을 만들어내는 모델
※ Loss function: KL Divergence -> cross entropy
 true distribution을 알 수 없기 때문에 sample을 이용해 근사함
true distribution을 알 수 없기 때문에 sample을 이용해 근사함
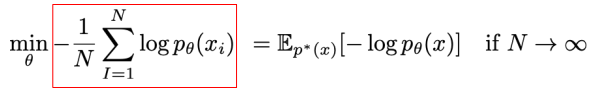
Auto-Regressive Model(AR)
Chain-rule 이용해 factorization
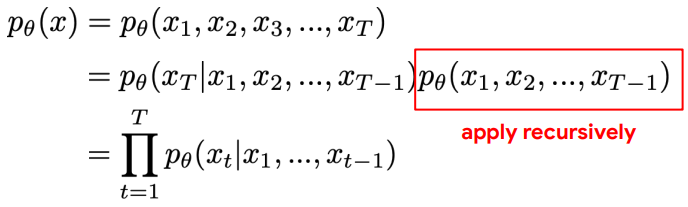 -> maximizing factorized likelihood
-> maximizing factorized likelihood
sequential data 처리에 좋음
Variational AutoEncoder(VAE)
raw 원본 데이터(image 등)는 쓸모 있는 정보만 가지고 있지 않음
-> 최대한 쓸모 있는 정보만 갖고 있도록 compact representation(Latent Space)하는 것이 encoding
※ latent vector의 유용성
interpolation 및 feature의 조작이 가능

하지만, latent space는 우리가 만들어낸 space이기 때문에 latent space의 분포 z~p(z)를 알 수 없다.
-> latent space의 element가 Gaussian 분포를 따른다고 가정(규정의 느낌인 듯?),
encoder가 μ와 σ를 생성하도록 학습
-> latent space는 p(z) ~ N(0, 1) 정규분포를 μ와 σ를 사용하여 Gaussian 분포로 만든 것
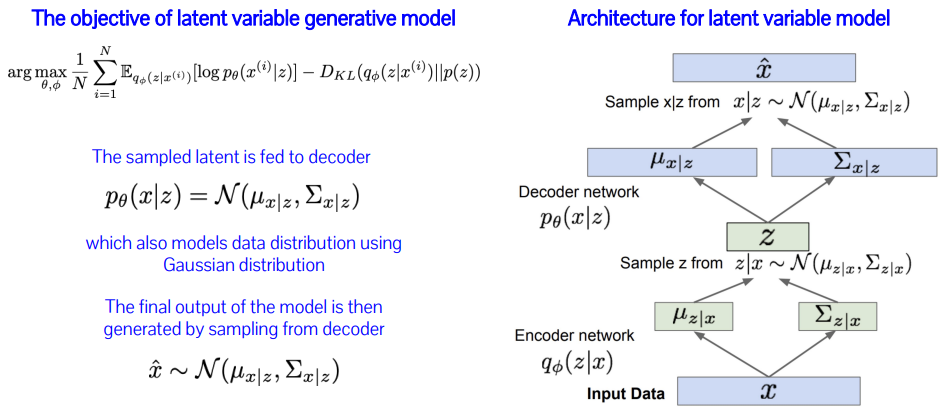
 likelihood를 lower-bound로 optimization
likelihood를 lower-bound로 optimization
loss function의 첫 번째 항은 reconstruction error, cross-entropy 혹은 L2 distance로 해석할 수 있음

KL Divergence 항은 q(z|x)의 분포가 p(z)의 분포와 같아지길 원함
-> p(z)를 정규 분포로 정했으므로, encoder가 정규 분포를 따르는 latent space를 생성하도록 학습
아래 유도와 같이 μ와 σ만으로 계산이 가능
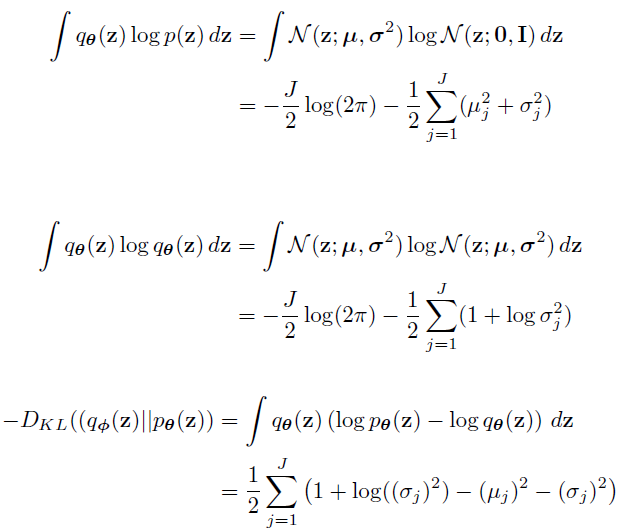
Generative Adversarial Network(GAN)
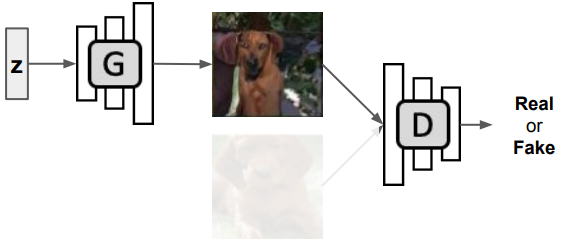
Discriminator: real / fake 판별
Generator: discriminator를 속이기 위한 output 생성
minmax objective function
