Multi Modal Learning - newlife-js/Wiki GitHub Wiki
by 서울대학교 황승원 교수님
Knowledge Modality
Knowledge를 이해하도록 학습
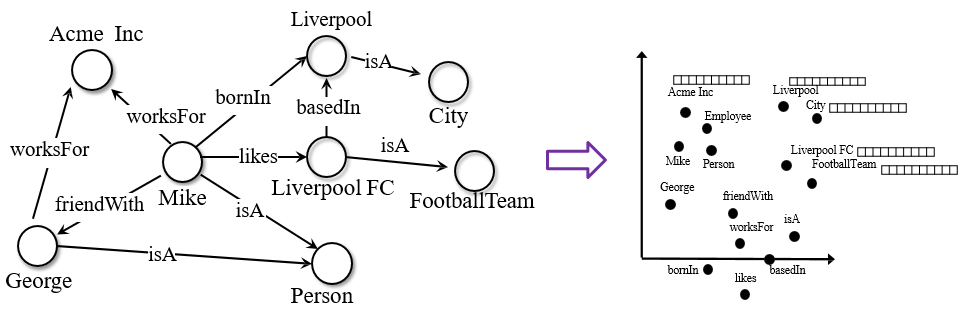
Knowledge Graph Embeddings(KGE)
Knowledge를 graph 구조로 나타내고, low-dimension으로 embedding
Knowledge NLP
Injecting World Knowledge for NLP
Summarization
긴 문장을 짧은 문장으로 요약
wiki로부터 knowledge를 embedding해서 attention mechanism을 이용해 decoder에 적용할 수 있음

※ Hallucination: embedding 상에서는 비슷한 위치에 있지만 사실과는 다른 내용을 generation함
(예: 퀴리는 turing award를 수상했다)
-> 이러한 예들을 contrastive learning을 통해 학습해야 함
NL-code multilinguality
NL -> source code 변환(Text-code)

다른 tasks
Semantic Code Search, Code Clone Detection, Code Translation, Code Refinement
GraphCodeBERT

CLWE(Cross Lingual Word Embedding)
서로 다른 언어의 embedding을 각 단어의 위치가 비슷하도록 alignment
- supervised alignment

- unsupervised alignment
단어 사이의 가깝고 먼 관계가(위치의 분포가) 비슷하기 때문에 단어가 주어지지 않더라도 alignment 가능
 비슷한 언어에서 잘 됨
비슷한 언어에서 잘 됨
Multi-Modal Learning
by 서울대학교 주재걸 교수님
CLIP(Constrative Language-Image Pretraining)



Text-to-Image Generation
예) Dall-E

Vector-quantized variational autoencoder(VQ-VAE)

 embedding space(code-book)에 마련해 놓은 8192개의 vector 중에서 encoding된 각각의 vector와 가장 가까운 vector를 골라서 대체함
embedding space(code-book)에 마련해 놓은 8192개의 vector 중에서 encoding된 각각의 vector와 가장 가까운 vector를 골라서 대체함

encoding된 vector가 code-book의 vector와 더 가까워지도록 update
dVAE & Transformer
